SymLM: Predicting Function Names in Stripped Binaries via Context-Sensitive Execution-Aware Code Embeddings
Publisher: CCS 2022
0 Abstract
现有方法尚未成功建模以穷举所有函数的执行行为,并且对于未见过的二进制的泛化能力很差。为了进一步推动函数名恢复任务的研究,我们提出了一个用于函数符号名预测和二进制语言建模的框架(SymLM Symbol name prediction and binary Language Modeling framework),该框架使用新型神经网络架构——一个融合encoder,该网络可以通过联合建模“the execution behavior of the calling context and instructions”(学习函数指令的语义和它在过程间CFG上的callers和callees的语义),来学习二进制函数的综合语义。我们从27个开源工程中收集了1,431,169个二进制函数来评估我们的框架,这些工程通过交叉编译得到(O0-O3,x86、x64、ARM、MIPS,4 obfuscations)。SymLM 在 precision、recall 和 F1 方面优于之前最先进的函数名预测工具 15.4%、59.6% 和 35.0%,具有更好的泛化性和抗混淆性。消融实验证明我们的设计(例如calling context 组件和execution behavior 组件)大幅提升了函数名预测模型的表现。最终我们的样例研究进一步展示了 SymLM 在分析固件映像中的实际表现。
calling context(调用上下文):指一个函数调用的函数,和调用它的函数。
1 INTRODUCTION
Our Approch.
为了解决函数名中自然语言的一些问题,比如同义词问题,OOV问题,我们构建了CodeWordNet来捕捉特定领域的函数名token的表征。
我们广泛的实验表明 SymLM 是准确的:在各种架构和优化选项中实现了 0.634 precision、0.677 recall 和 0.655 F1。在 F1 上SymLM超过SOTA的工具35%。通过学习上下文敏感的函数语义,我们证明了SymLM比现有工作具有更好的泛化性和健壮性。在针对未见过的二进制函数的评估中,其F1比SOTA工具高出295.5%。另外,消融研究进一步证明了 SymLM 设计:融合calling context 的有效性。例如,语义融合encoder可以将 SymLM 的 F1 分数提高多达 36.2%。我们还将 SymLM 应用于现实世界的物联网固件,它成功地预测了固件映像中的函数名称
Contributions.
- 我们设计了一个新型神经网络架构,SymLM,用于学习保存在调用上下文和函数指令的执行行为中的综合函数语义。
- 我们构建了CodeWordNet模块,以使用指定领域的分布式表征来测量函数名的语义距离,并通过预处理解决 OOV 问题。
- 我们通过超越现有工作推进了函数名称预测的最新技术,并展示了 SymLM 的通用性、抗混淆性、组件有效性和实际用例。我们的代码和数据集发布在 https://github.com/OSSecLab/SymLM
2 BACKGROUND AND MOTIVATION
2.1 Problem Definition
。。。
2.2 Challenges
C1: Limited Semantic Information in Stripped Binaries.
C2: Variety of Compilation Settings and Obfuscations.
C3: Ambiguous Function Names and Various Naming Methods
函数名中的单词常出现原始词干的变形,比如时态,缩写,甚至拼写错误,而且同样功能的函数常被赋予不同的名字。开发人员使用的分隔符是多种多样的,比如大写字母、下划线甚至数字。
因此,函数名的模糊性和命名方法的多样性使得函数名的预测变得困难。
C4: The Out-Of-Vocabulary (OOV) Issue.
在整个函数名级别,我们对二进制数据集的调查显示,21.7% 的函数名只出现过一次。尽管我们可以通过将名称拆分为各个单词来缓解这个问题,但 OOV 比率仍然相对较高,例如 ARM 二进制文件为 5.8%(test 中的label 出现train 中没有的单词)。
C5: Calling Context Modeling.
现有的作品都没有考虑调用上下文的执行行为,包括已经初步尝试对函数的执行行为建模的最新工作(Sec 2.4 TREX)。另外,虽然 NERO 构建了函数调用图并将函数调用点的信息作为其模型的输入,但它并没有充分考虑被调用函数的行为。
2.3 Prior Efforts and Our Motivations
。。。
2.4 Microtrace-Based Pretraining
本文课题组先前的工作,TREX 提出了一种通过预训练micro-execution trace value 的方式建模执指令的执行语义。TREX 在二进制相似度搜索领域取得了不错的成果。
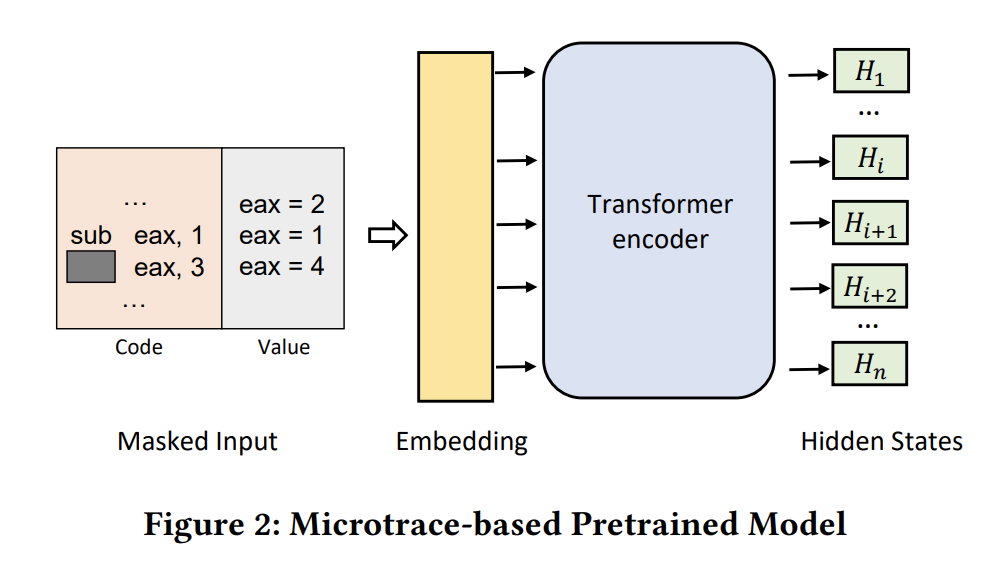
上图Fig2 展示了TREX 的预训练模型,模型输入指令,和对应的由微执行产生的值。当盖住操作符,模型要预测执行逻辑 eax?3=4 。预训练后,TREX 生成每条指令的语义嵌入(向量表示),可进一步用于检测具有相似执行行为的二进制函数。StateFormer 作为其后续研究也通过学习函数执行语义来推断变量类型。而这两者都不是为函数名预测设计的,所以他们不能解决上述C3 C4两个挑战。
Missing Calling Context. 不幸的是,TREX 也没有考虑函数调用的副作用,所以它只能学习部分函数语义, StateFormer 也存在同样的问题。这限制了它们在面临挑战 C5 时对二进制函数语义的理解。为了弥补这个缺陷,我们提出了 SymLM,基于 microtrace 的预训练模型,来学习完整函数语义用于预测函数名。
3 OVERVIEW
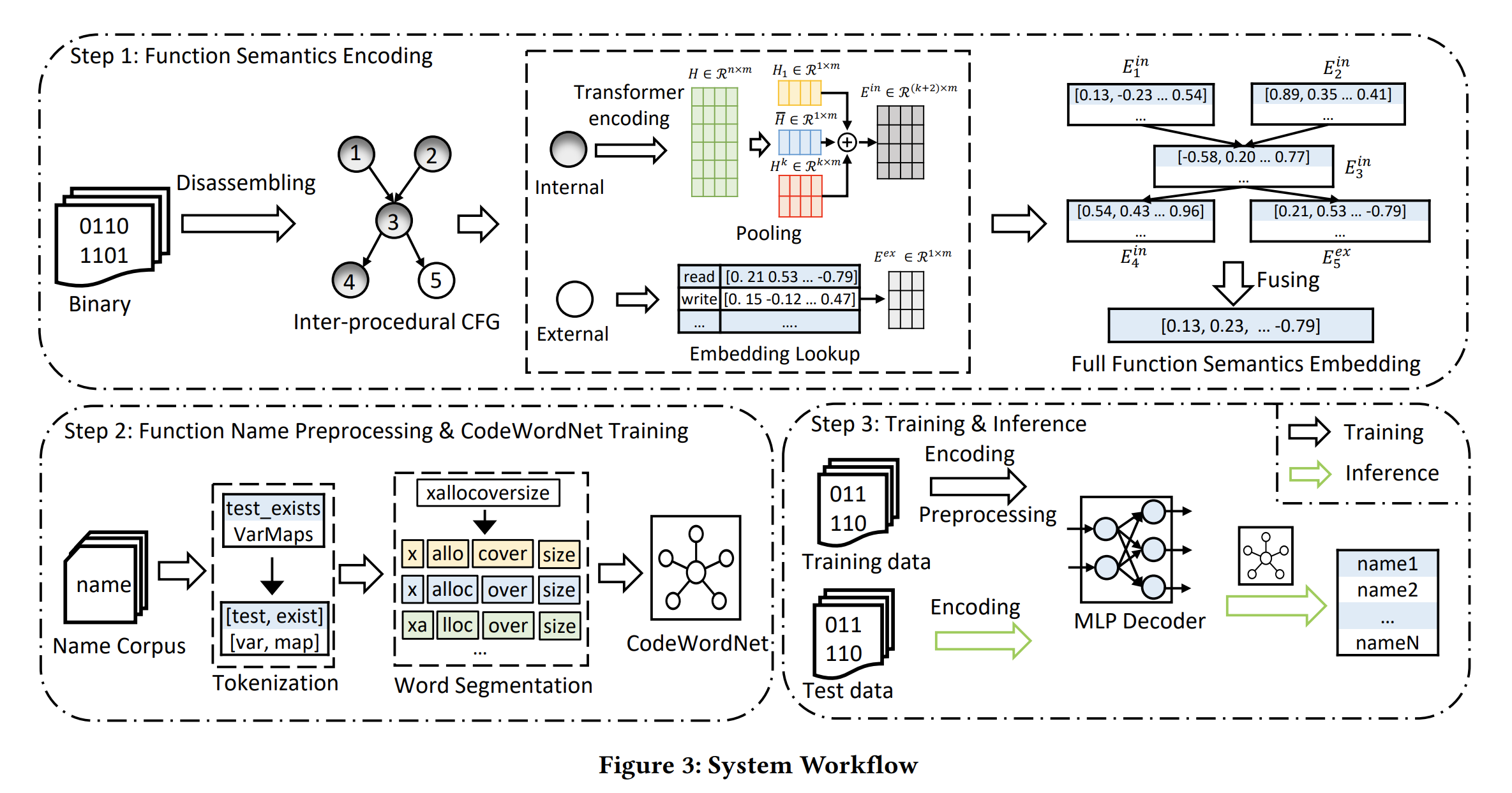
上图展示了SymLM的工作流,主要是3个关键步骤:
1)Function Semantics Encoding:理解二进制函数综合语义并编码到向量表征形式;
2)Function Name Preprocessing and CodeWordNet Training:建模函数名语义,缓解自然语言的模糊性,减少OOV的token;
3)Training and Inference:训练模型将函数语义向量映射到函数名。
下面将分别阐述一下这三个步骤中的细节,辅助理解fig3 SymLM的工作流。
Function Semantics Encoding
首先,构建过程间控制流图ICFGs,如Fig3 step1,其中节点3(函数)可能调用内部节点4(内部函数)或者外部节点5(外部函数)。
接下来,SymLM 采取下面两个步骤构造函数内部指令的嵌入 :
- 使用microtrace-based 预训练模型(fig2)生成函数tokens 的embedding,这个预训练模型在fig3中就是Transformer
- 下采样token embeddings 生成结构化表征()。例如,对于节点3,使用 指代这个函数的指令嵌入。
为了产生函数的上下文嵌入 ,需要同时嵌入节点callers和callees的执行行为信息。对于其他的内部函数可以用上述方法分别生成其 向量,而对于外部函数比如节点5,SymLM 通过查找embedding table 来获取其嵌入 。
最后,SymLM 融合一个节点的callers和callees的嵌入向量来生成语义嵌入 ,并通过结合 和 得到最终的函数表征向量。
关于如何下采样计算内部函数的 . 和TREX 中直接使用token embeddings的均值不同,SymLM 使用一个特别的pooling 策略来下采样获取更好的模型表现。具体来说,我们观察到,在自然语言处理任务中,直接使用 [CLS] 的嵌入或者所有token嵌入的平均值作为句子嵌入,这两者已被证明是无效的,它们会分别导致 17.5% 和 10.3% 性能下降。根本原因是基于 BERT 的预训练模型生成各向异性token 嵌入。我们将多种下采样嵌入向量拼接起来,包括[CLS] embedding,所有token embedding的均值,以及token-position-insensitive embedding ,三者拼接作为函数语义嵌入 。其中token-position-insensitive embedding:从上图fig3 step1 中取前 k (实验中k=5)行最大的向量作为。关于如何比较每一行的大小,文章并没提到(盲猜直接求和一行)。
关于外部函数的嵌入. 基于这样一个观察:“外部函数的语义通常是固定的,且很大程度上体现在其函数名上”,本文使用一个随机初始化的embedding layer 来根据外部调用函数的函数名获取其 。相当于一个词汇表的嵌入,而这个词汇表是通过训练集中的外部调用函数名构建的。在模型训练期间更新这个嵌入层以获得外部函数名的最佳嵌入。当外部函数名不可用时,我们放弃融合对应的函数调用。
关于如何融合多个 获得 . 我们提出了一个具有选择性的调用上下文融合策略:1)SymLM 根据caller和callee的call和called by 目标函数的频率排序,2)拼接top-n个caller和top-n个callee的向量:
其中, 和 分别是 𝑖-th caller and 𝑗-th callee 的嵌入向量。
关于如何融合目标函数的 和 得到最终的模型输入. 拼接两个向量。
Function Name Preprocessing and CodeWordNet Training
总结了7种OOV问题,如table 2,设计了多种方法来解决这些问题。
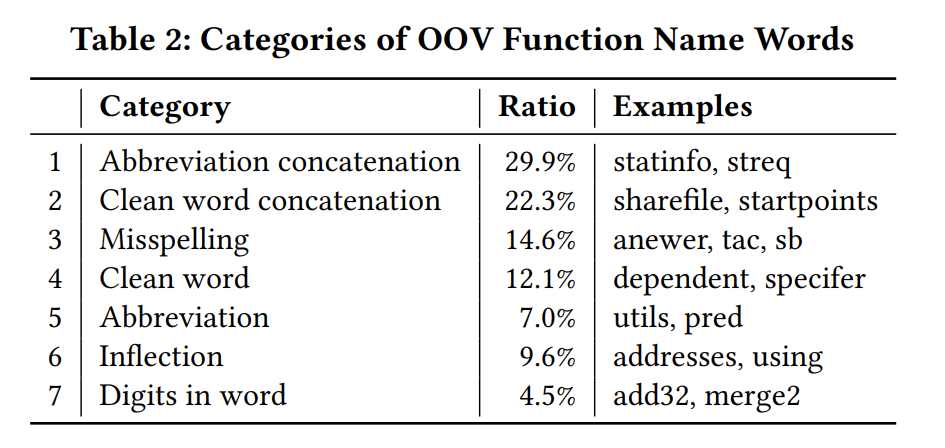
首先,在tokenization 过程中,我们对带数字的单词和单词的变形两种情况进行词形还原,以解决表 2 中的 6 和 7。其次,我们基于 unigram 语言模型构建了一个分词模型,对常见连词进行分隔,解决1 和 2。其余问题归结为 3、4 和 5。OOV 类别 3、4 和 5 中的词的关键原因是使用单词的变体(例如,同义词、缩写和拼写错误),我们设计了 CodeWordNet 模块,它可以在函数名称的上下文中生成单词的语义向量表示。借助该模块,SymLM 可以测量词的语义距离,建模函数名称语义,并解决类别 3、4 和 5 中的 OOV 问题。
Training and Inference
为了学习从函数语义向量到函数名的映射,我们使用带有调试信息的二进制文件提取数据集训练 SymLM,其中函数名标签从符号表中解析得到。对于训练,SymLM 首先将完整的函数语义编码为嵌入,然后预处理函数名标签,通过多层感知 (MLP) 解码器将函数语义嵌入解码为要预测的名称,最后通过最小化预测损失进行训练。在推理阶段,SymLM 将剥离的二进制文件作为输入,并根据函数的语义嵌入预测函数名tokens,其中生成函数名时 SymLM 也利用到了 CodeWordNet 生成多个同义词。
4 DETAILED DESIGN
。。。
5 EVALUATION
使用Ghidra 作为反编译工具,基于TREX 实现了microtrace-based pretrained model,增加了1864 行新代码。我们使用NLTK 和SentencePiece 构建了我们的函数名处理组件,使用Gensim 构建了CodeWordNet 。开发了一个Ghidra插件和脚本来反编译二进制和解析调试信息。其他部分使用Pytorch 和fairseq 实现。
评估指标(同NFRE和NERO):
。。。
RQ1: How effective is SymLM in function name prediction?
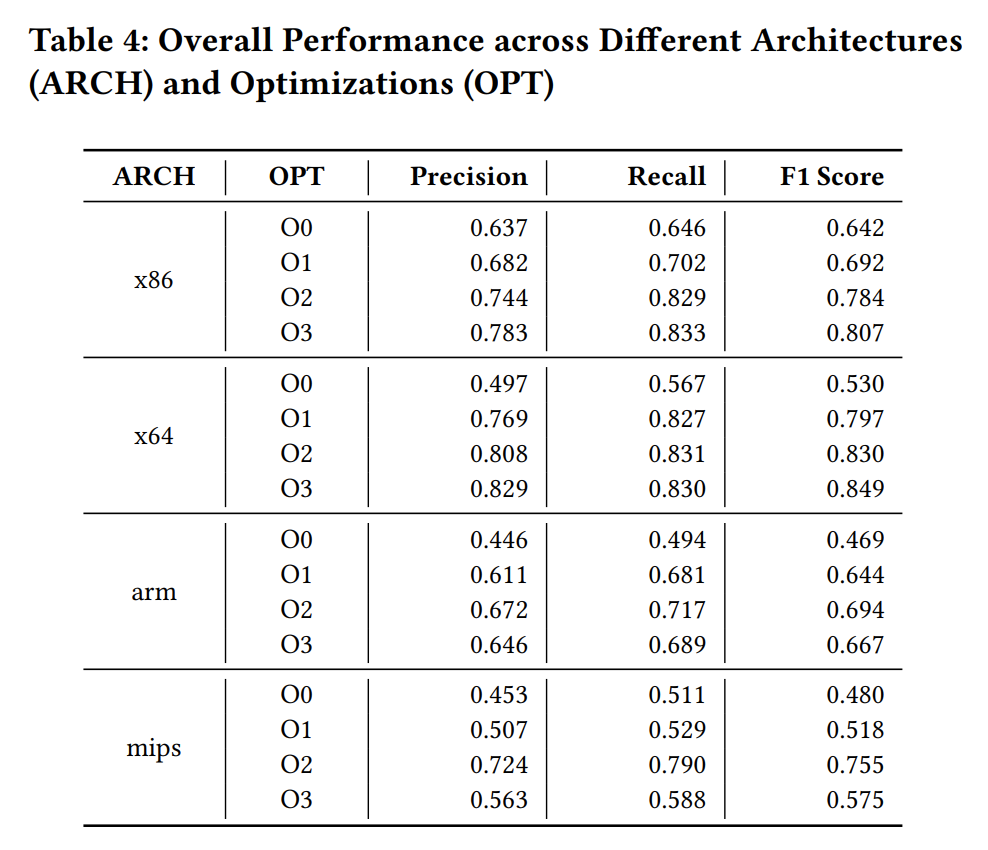
SymLM 在预测二进制函数名任务上非常有效,它在不同的架构和优化中实现了 0.634 的精度、0.677 的召回率和 0.655 的 F1 分数。
RQ2: How does SymLM compare to the state of the art?
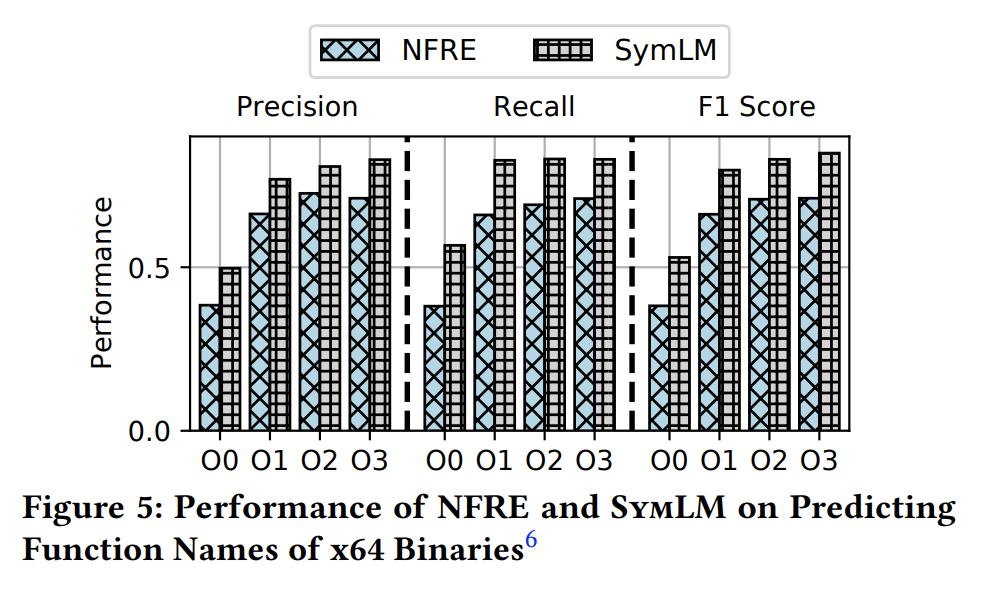
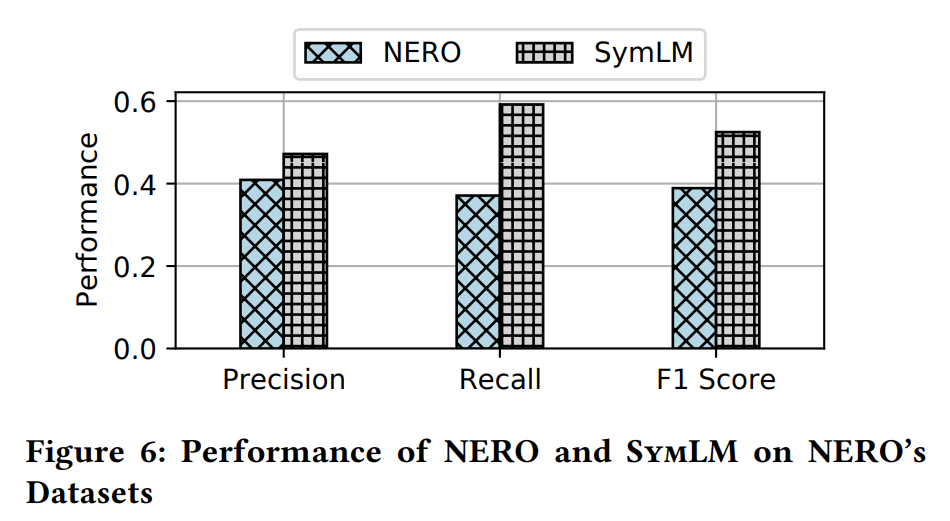
SymLM 比之前最好的工作更有效。例如,它在准确率、召回率和 F1 分数上比 NERO 高出 15.4%、59.6% 和 35.0%。
RQ3: How can SymLM generalize to unknown binaries and resist obfuscations?
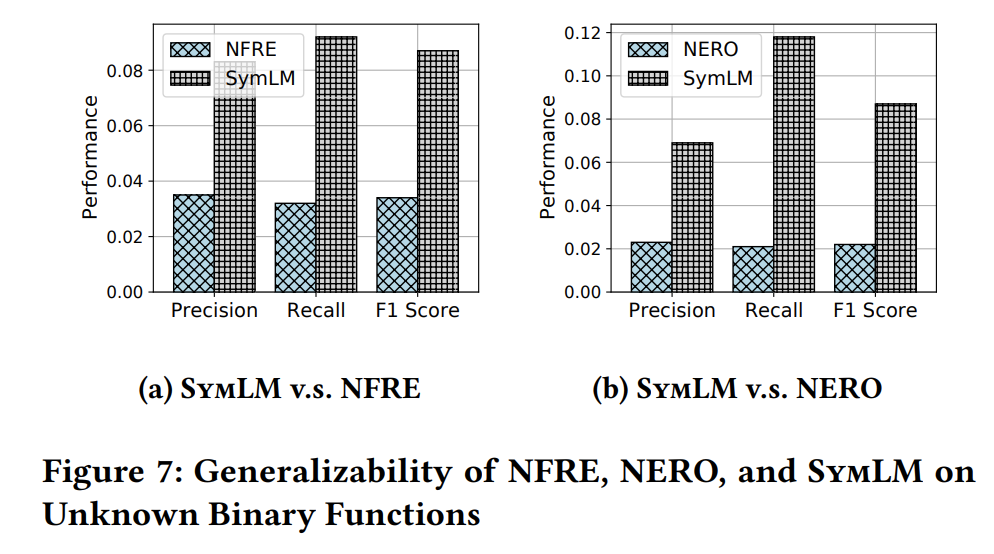
泛化性能更好,但是还是不够好
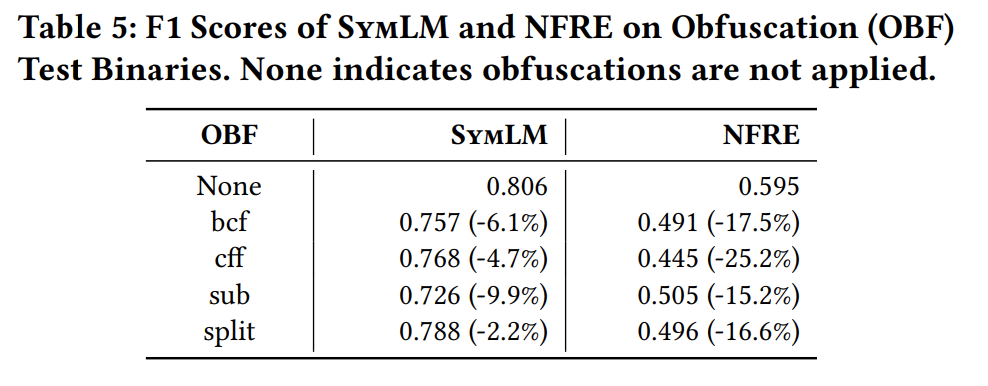
健壮性,抗混淆能力不错。
RQ4: How can SymLM’s components improve its performance?
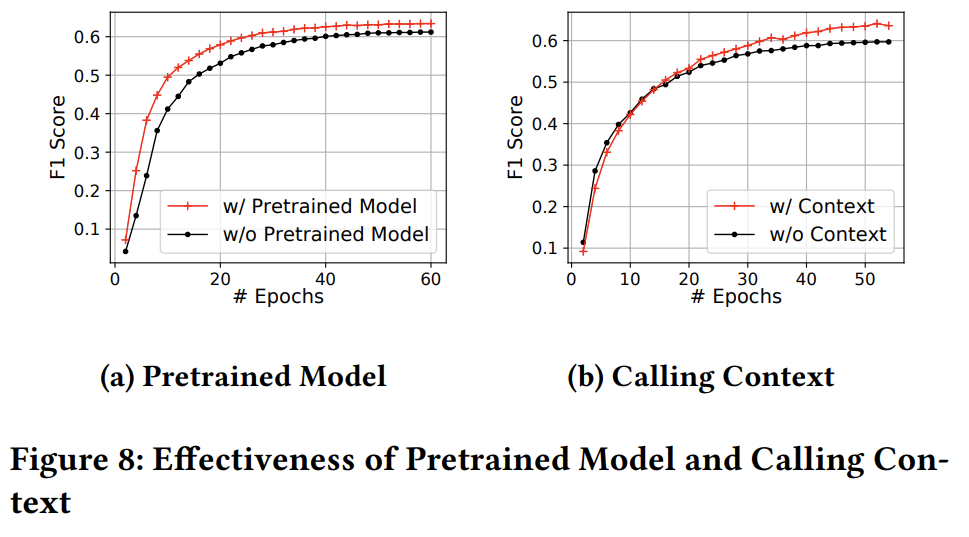
-
fig8 (a) 是预训练模型对预测模型的提升,也就是基于TREX 的指令token嵌入模型。
在前20 epoch的提升比较明显,而在超过20 epoch后基本可以忽略不计。
-
fig8 (b) 是调用上下文对预测模型效果的提升,即是否包含目标函数的上下文函数的嵌入 。
调用上下文的加入对模型能力上限有提升,7.9%。
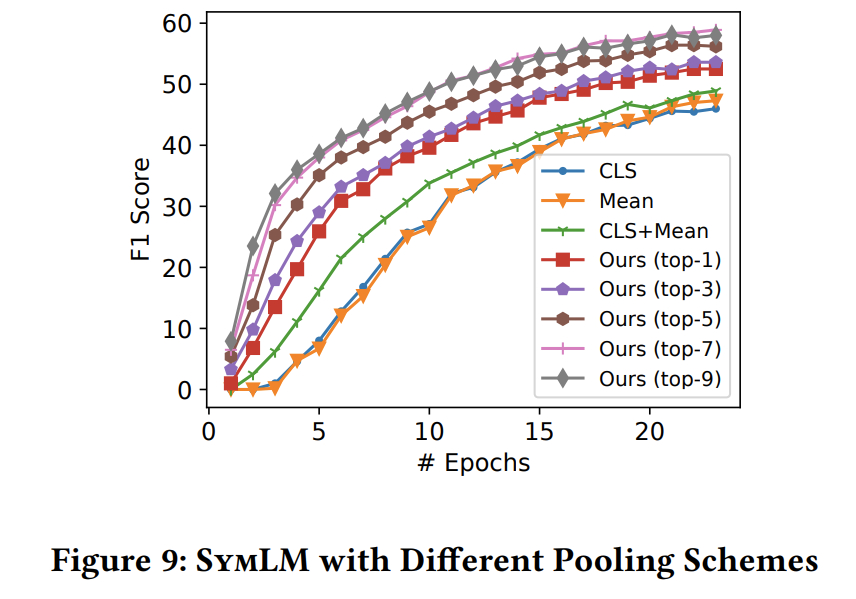
fig9 是fig3 step1中对函数tokens 的embedding 矩阵 池化策略的不同,对模型的影响。
本文的池化策略对模型的提升还是比较显著的,加入 token-position-insensitive embedding 后提升明显。
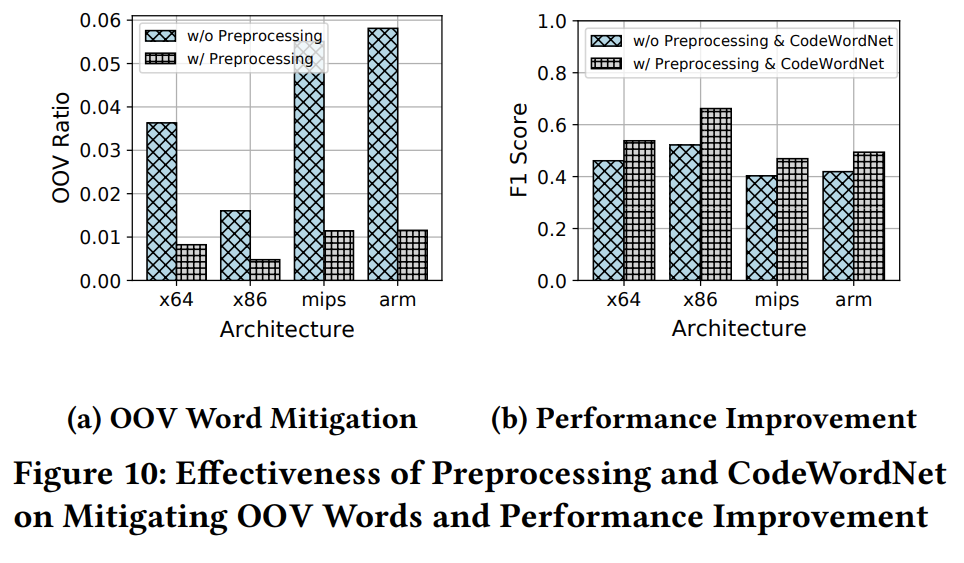
fig10 是对函数名token预处理后OOV问题的减轻程度,以及预测模型性能的提升。
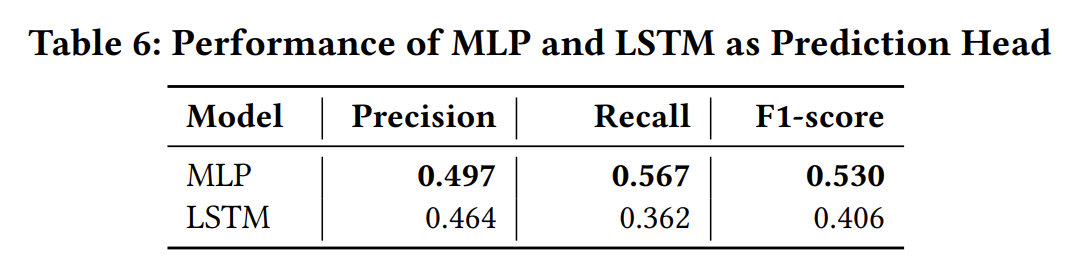
不同的预测模型(解码器),MLP略优于LSTM。
6 CASE STUDY
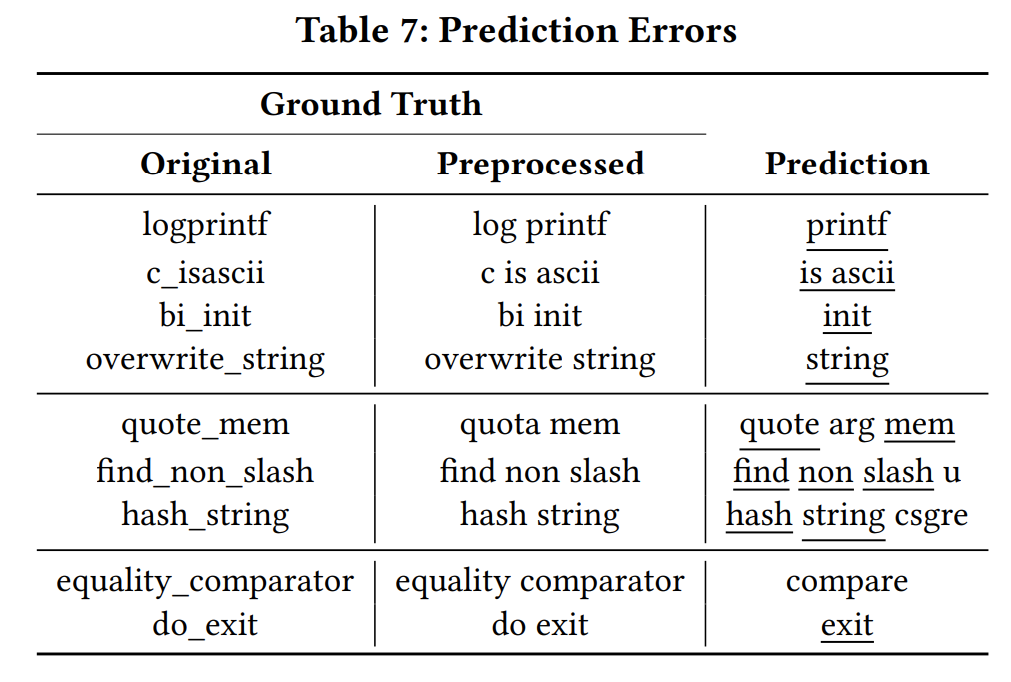
。。。
7 DISCUSSION
本节讨论我们工作的局限性和未来的方向。我们考虑以下可能使我们的评估结果产生偏差的案例,解决它们都可能是有趣的未来工作。
Dataset Size. 当前数据集规模不够大,更大的数据集应该能使模型具有更好的泛化性。
Obfuscation. 本文中仅考虑编译器混淆,而没有考虑其他形式的混淆,例如加密和加壳。我们将其看作和本文正交的研究问题,任何对这些问题的研究进展都能促进我们的方法提升。
Operating System. 我们仅关注Linux上的二进制,其他OS或许有不同的调用上下文语义,这可能会使SymML 失效。
Noise in Ground Truth. 虽然我们试图解决模棱两可的函数名称问题,但由于 SymLM 中使用的词嵌入算法的限制,该问题并未完全解决。此外,本文只考虑token级别的语义相似性,而未考虑具有多个token的相似短语。我们将在未来的研究中解决这些问题。