基于机器学习的函数名恢复总结(上)
本文总结2018年至今(2022.10)发表的关于使用机器学习方法恢复二进制代码中函数名的工作,帮助中文社区快速了解该课题当前的研究进展,期待更多研究者的加入,加速解决该任务的进度。同时欢迎对该课题感兴趣的同学做交流。
总结将包含6篇工作,按照关键词,摘要,方法,主要实验和讨论的模板进行总结,篇幅过长本文将分为上下两节。
必须的预备知识:逆向分析基础,Transformer,LSTM,图网络模型,自然语言处理基础
DEBIN
CCS 2018, Debin: Predicting Debug Information in Stripped Binaries
关键词
BAP-IR, Conditional Random Field(CRF), MAP inference, Extremely Randomized Trees, Undirected dependency graph
摘要
我们提出了一种预测剥离二进制文件中调试信息的新方法。我们首先在数千个未剥离的二进制文件上训练机器学习模型,然后使用模型来预测剥离二进制文件缺失的调试信息,包括符号名(symbol names)、类型(types)和位置(locations),它们是在编译和剥离时被擦除的源码级信息。
我们的方法能区分并抽取出二进制代码中的关键元素,例如寄存器上的变量和内存中的变量。为了预测这些抽取出的元素的符号名和类型,我们使用概率图模型和一个广泛的特征集来捕捉二进制代码中的关健特征。
针对这个研究任务,我们实现了一个自动化工具DEBIN 用于处理ELF 文件。它可以实现输入剥离二进制文件输出恢复调试信息后的二进制文件的功能。支持的ELF 文件架构有x86,x64,ARM。在x64数据集上的实验结果,预测符号名和类型达到68.8% precision 和68.3% recall 。我们还证明,DEBIN 能辅助分析真实世界的恶意软件——它揭示了可疑的库文件调用和其他可疑行为,例如 DNS 解析器读取器。
code: None
方法
DEBIN 恢复样例展示:

上图是DEBIN在一个真实样本中的DNS resolver reader 函数上的恢复效果。
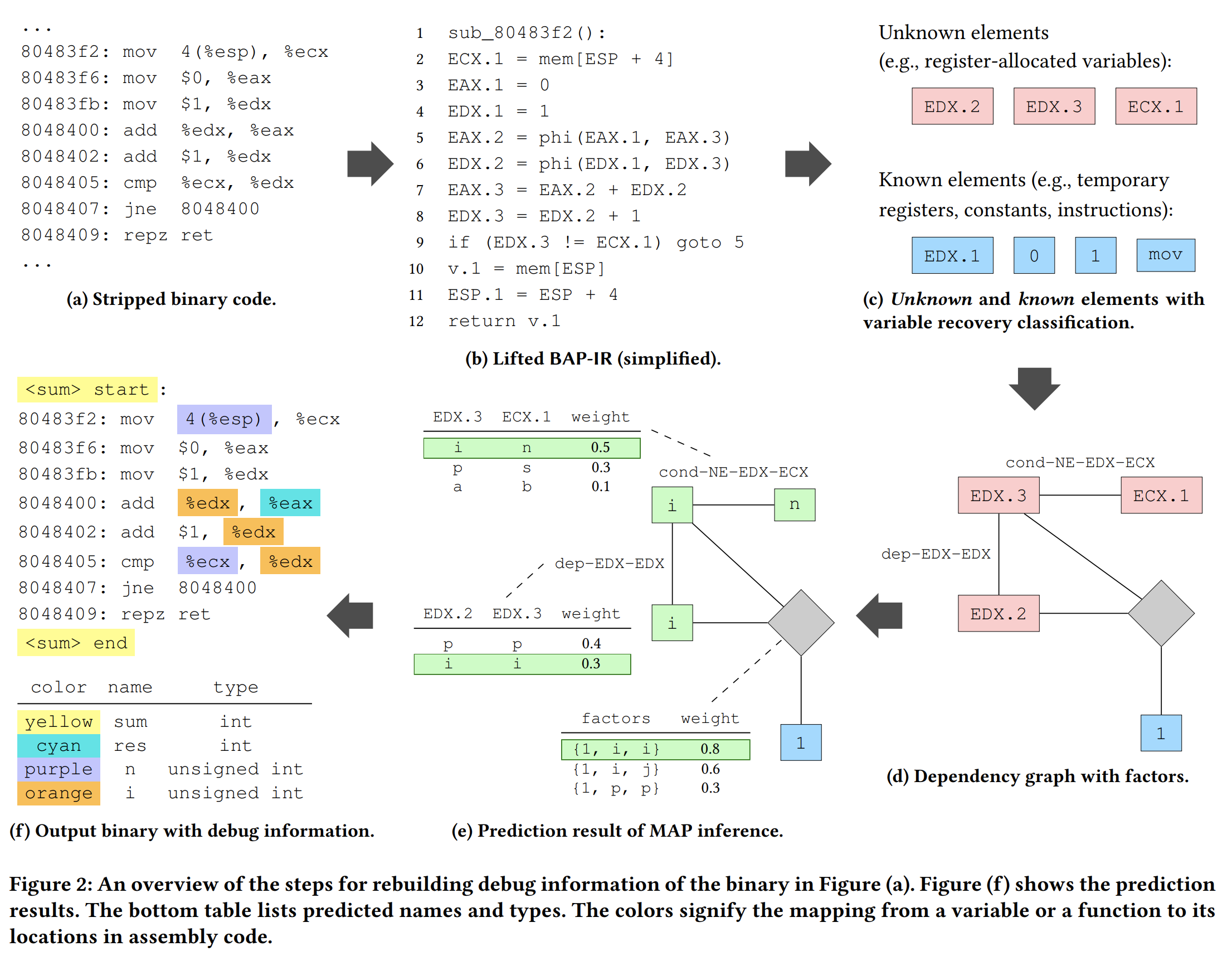
DEBIN对二进制文件的分析过程如上图所示,接下来简单叙述一下。
-
Lift Assembly into BAP-IR
使用BAP做code lift,得到fig2(b)
-
Extract Unknown and Known Elements with Variable Recovery Classification.
将IR程序元素划分为两个集合:
- unknow elements,这些元素的信息被strip掉了,例如存储变量的寄存器
- know elements,这些元素的信息已经出现在二进制代码中了不需要做预测,例如临时寄存器,常量和指令
因为人工判断上述两种元素是很困难且费时费力的,所以本文要训练一个二分类模型(Sec3.1)来做判断。
-
Build Dependency Graph.
基于整个二进制文件构建一个无向依赖图(undirected dependency graph)节点是BAP-IR 抽取出来的代码元素,边是这些代码元素之间的关系。如fig2 (d)所示,关系划分为两种Pairwise 和Factor :
-
Pairwise
EDX.3 和ECX.1 两个代码元素之间存在 “不相等” 的条件比较关系,EDX.3 和EDX.2 之间存在赋值的依赖关系
-
Factor
如果两个节点可以演化出一个常量节点,就使用一个灰色菱形连接。上如图所示 EDX.3=EDX.2+1 ,这种Factor 关系常用于表达 i++ 的操作,其作用可以理解为通过链接多个节点来增强模型的表达能力
总体来说,依赖图上的这两种关系源自于,作者分析出的二进制代码元素的语义行为。抽取代码元素的具体过程在原文Sec4详细叙述。依赖图模型表征条件随机场CRF概率模型,它可以捕捉节点之间的关系,并且其后可以接入一个预测模型,判断一个代码元素是否需要分析。
-
-
Probabilistic Prediction.
DEBIN 在依赖图上使用Maximum Posterior(MAP)推断。
如图fig2 (e)所示,概率预测的时候是通过给每个unknown node 命名,且每个node 都附带一个表,表中是其和相邻node 的关系,每个可能的关系组合都会赋值一个weight,这个权重是通过训练数据得到的先验值,其在直觉上表示赋值的似然估计。
MAP 推断算法的优化目标是找到一个全局最优的赋值方案使得weight 的总和最大化。
-
Output Debug Information.
DEBIN 最终的输出如图fig2 (f),它恢复了sum函数的函数名和返回值类型(int),变量res, n, i 的变量名与类型,以及他们在汇编代码中的位置。这些变量和汇编代码中的位置之间的关系是一对多的。
DEBIN将恢复出来的调试信息打包成DWARF格式,输出一个带有调试信息的二进制文件。
关于二分类模型. 预测寄存器或内存偏移是否映射到源码中变量,该变量可以是局部变量、全局变量或函数参数(不区分)。每个寄存器或内存偏移都可以用一个特征向量表示,生成这些代码元素的特征向量的方法是人工定义的规则。本文使用的二元分类模型是一个Extremely Randomized Trees ,它将特征向量作为输入,并输出一个布尔值,表示它是否为需要预测的变量。
关于条件随机场模型在依赖图上的计算. 这里有个关键的事情还没讲,Feature Functions,文中根据依赖图上的Pairwise和Factor分成两类特征函数:
- Pairwise Feature Functions:当赋予两个可能的值到两个代码元素,应用这个特征函数,根据两个节点之间的关系计算一个标量数值。
- Factor Feature Functions:当一种factor连接的多个节点都被赋值后,应用这个特征函数,根据节点之间的关系计算一个标量数值。
这里忽略关系的定义和各种关系应用的Feature Functions 的细节。
主要实验
Dataset. x86, x64, ARM 架构,每个架构收集了3000个编译自C语言的未剥离二进制文件。
二分类模型性能:
Accuracy: x86 = 87.1%, x64 = 88.9%, ARM = 90.6%.
预测模型性能:
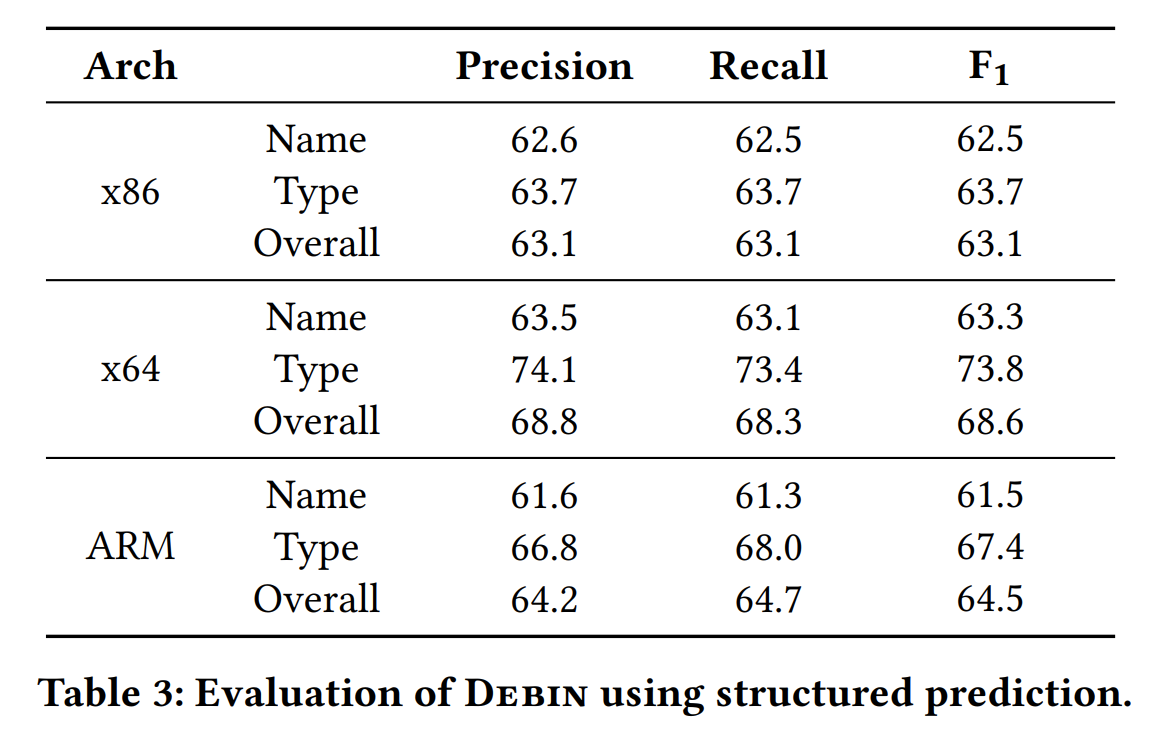
对比之前的工作:
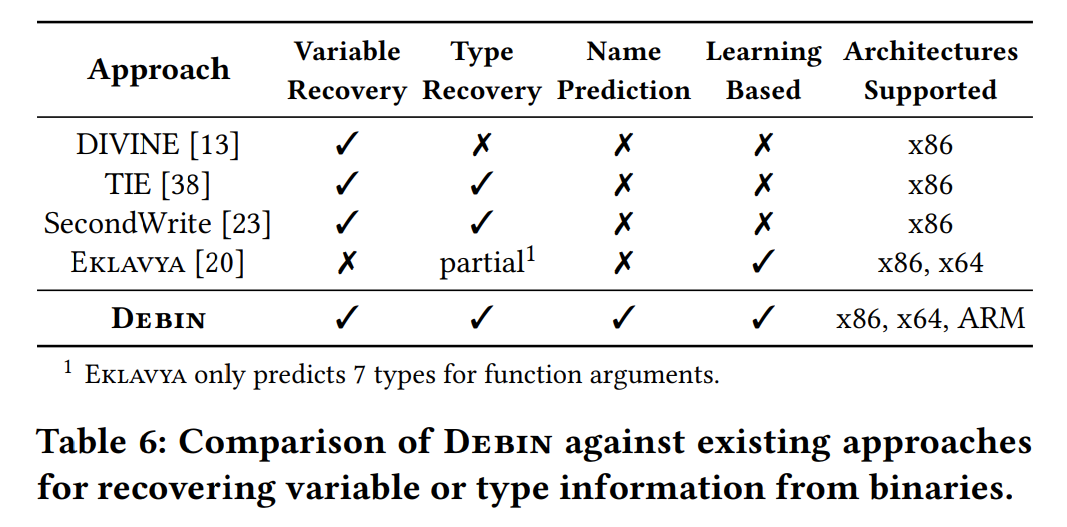
讨论
时间消耗. 每个架构的符号名和类型预测的训练阶段持续大约 5 小时:大约 4 小时训练两个 ET 二分类模型(一个用于寄存器,另一个用于内存偏移),一个小时用于训练 CRF 模型(60线程)。每个二进制文件(一个线程)的平均预测时间约为 2 分钟,其中大约 80% 用于二分类变量确定是否需要预测,20% 用于运行我们的分析以构建依赖关系图并对该图执行 MAP 推理。未来可能的工作项目是提高二分类模块的效率。
恶意样本分析上的局限性. 使用我们的概率模型,DEBIN 从我们的训练集学习二进制代码的特征,这些都是良性样本。然而,恶意二进制文件通常表现出比良性二进制文件更复杂的行为。例如,我们在恶意软件数据集中发现了使用自定义字符串编码的样本。还可以执行诸如控制流扁平化之类的混淆技术来阻碍分析。DEBIN 可能对混淆的二进制文件还不能做出准确的预测。安全分析师可以将去混淆方法与DEBIN 相结合来解决这些问题。
PUNSTRIP
ACSAC 2020, Probabilistic Naming of Functions in Stripped Binaries
关键词
VEX-IR, Conditional Random Field(CRF), Word2Vec, call-graph, Intraprocedural-CFG
摘要
二进制可执行文件中的调试(符号)信息包含所有函数名和变量名。当调试信息存在的时候很大程度减轻了逆向工程的难度,但是这些信息大概率在发布二进制文件之前就被移除了(stripped)。我们设计了punstrip,它使用二进制代码的概率指纹和概率图模型来学习函数名和二进制代码结构之间的关系。punstrip 提供了一种判断语义上相似(即使文本完全不同)的函数名的方法,我们称为 Symbol2Vec ,用于在剥离二进制文件中推荐有意义的函数名。本文证明了我们的方法能够识别跨不同编译器和优化级别的相同函数,并且证明了我们的工具可以根据二进制代码结构预测出语义相似的函数名。我们使用来自 Debian 软件源的开源C语言二进制文件评估我们的方法,并与最先进的方法进行比较。为了促进相关研究,我们将我们的代码和数据集开源。
code:
punstrip/Symbol2Vec: Symbol2Vec Embeddings (github.com)
dataset:
https://github.com/punstrip/debian-unstripped
https://github.com/punstrip/cross-compile-dataset
方法
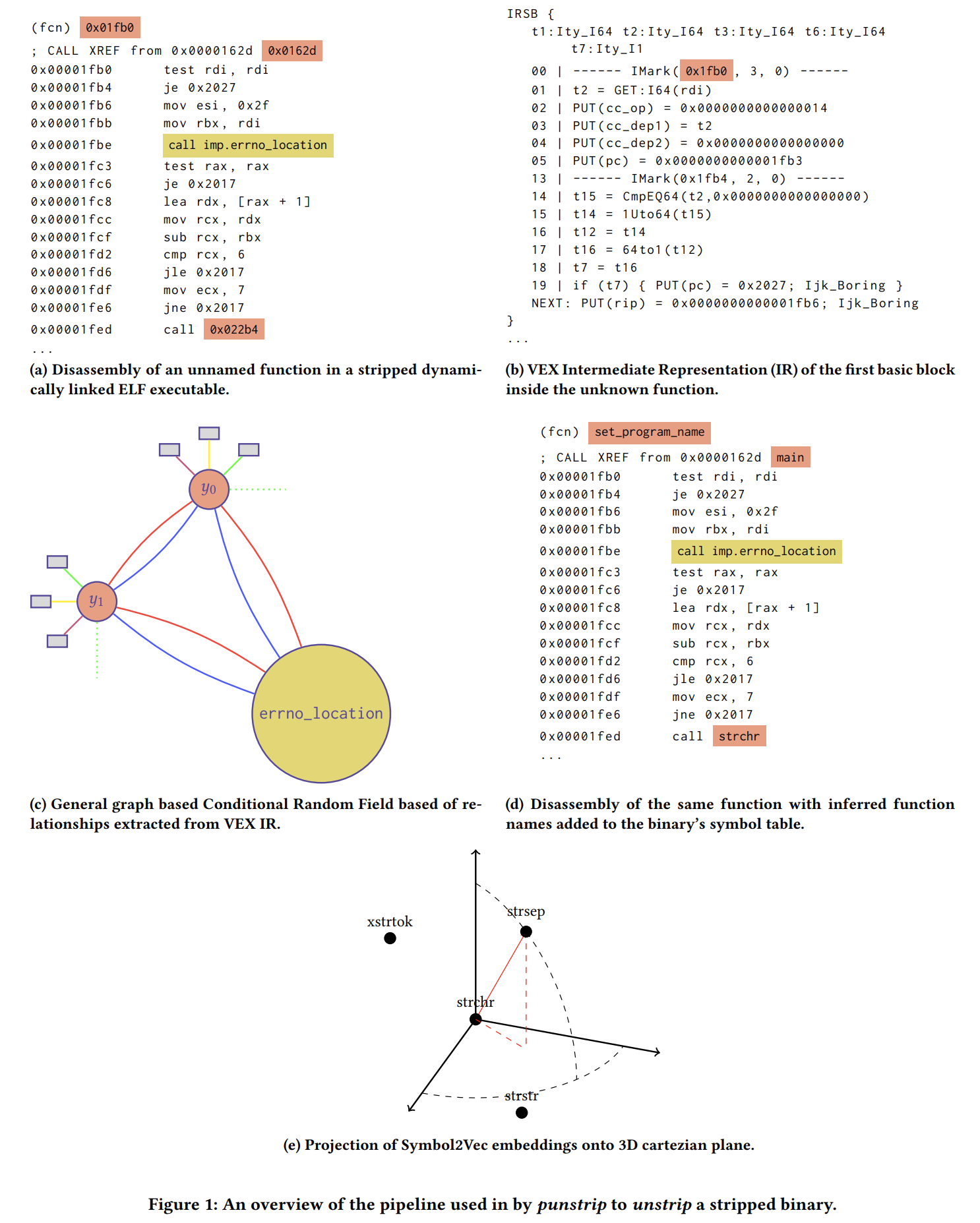
上图fig1 是punstrip 恢复剥离二进制文件中函数名的工作流。
(a) 反汇编器从剥离二进制中确定函数边界,恢复汇编代码。
(b) 为了实现夸编译器和跨优化选项的能力,将汇编代码提升到中间语言(IR),在中间语言上提取特征。这里选择 VEX IR 原因是它提供比 BAP IR 更抽象代码表征。实际执行的时候反汇编器先划分基本块,然后在基本块上执行SSA 以提升到 IR 。
© 从 IR 上抽取高级特征和函数之间的关系后,我们以条件随机场 (CRF) 的形式构建概率图形模型。CRF 模型对二进制文件中的所有函数的code 和 data 之间的pairwise 和 factor 关系进行建模。在大量未剥离二进制文件上训练图模型,我们可以同时最大化所有未知函数名的联合概率,而不是孤立地考虑每个函数。
(d) 最后,在我们推断出未知函数名后,我们修改 ELF 可执行文件符号表并将条目插入到 strtab 和 symtab 部分。
(e) 我们考虑相似函数名称的问题,并实现一种方法 Symbol2Vec 来计算函数名相似性。
关于IR上的特征提取. 所有的特征抽取如下图tab1 所示:
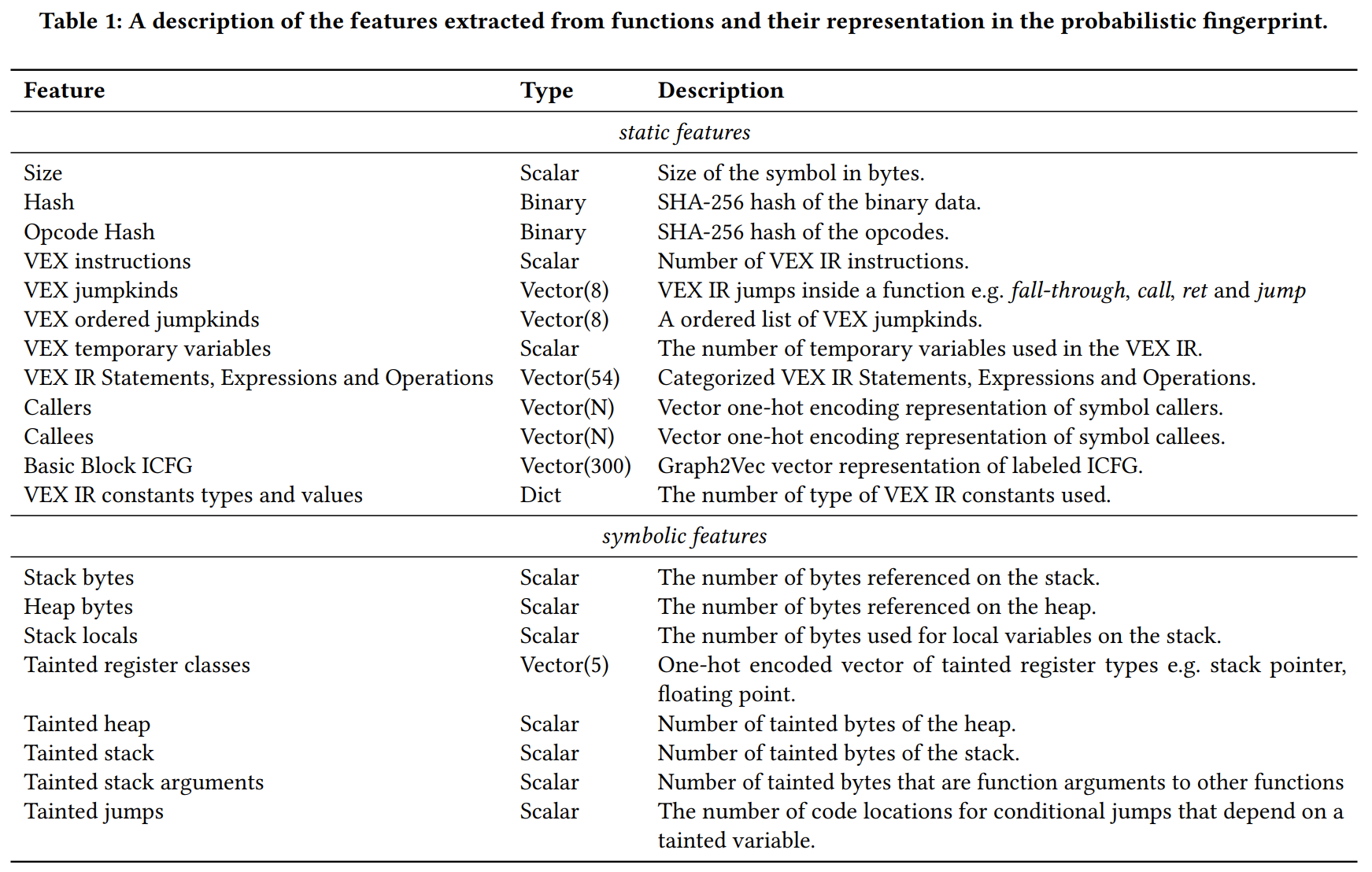
-
静态特征:
其中包括两个有助于找到精确匹配的低级特征:二进制代码的哈希,反汇编操作码的哈希。操作码哈希可以模糊代码中的偏移量、立即数和地址等数值。其他特征均从IR上提取。
其中使用Graph2Vec 将该函数的过程内CFG嵌入到一个300维的向量,该向量表征函数的图结果,相似的图结构得到的嵌入向量的欧氏距离更近。
-
符号特征:
我们使用我们自己建立在 VEX IR 之上的动态符号执行来提取符号语义特征。我们基于ANGR 实现了自己的执行引擎,以提供跨多个平台的分析。
最终的目标是将上述提取的特征转换成一个对所有可能符号名的概率分布(函数的概率指纹)。对于所有标量和向量类型的特征,将他们拼接为一个向量输入贝叶斯分类器(实验发现贝叶斯优于其他机器学习和深度学习算法)学习分布。将binary和dict类型的特征中出现在所有函数体的特征拿出来通过一层全连接神经网络学习分布,输出softmax层维度是所有可能的函数名的数量。
关于 CRF 模型上的计算. CRF Generation 如下图fig2:
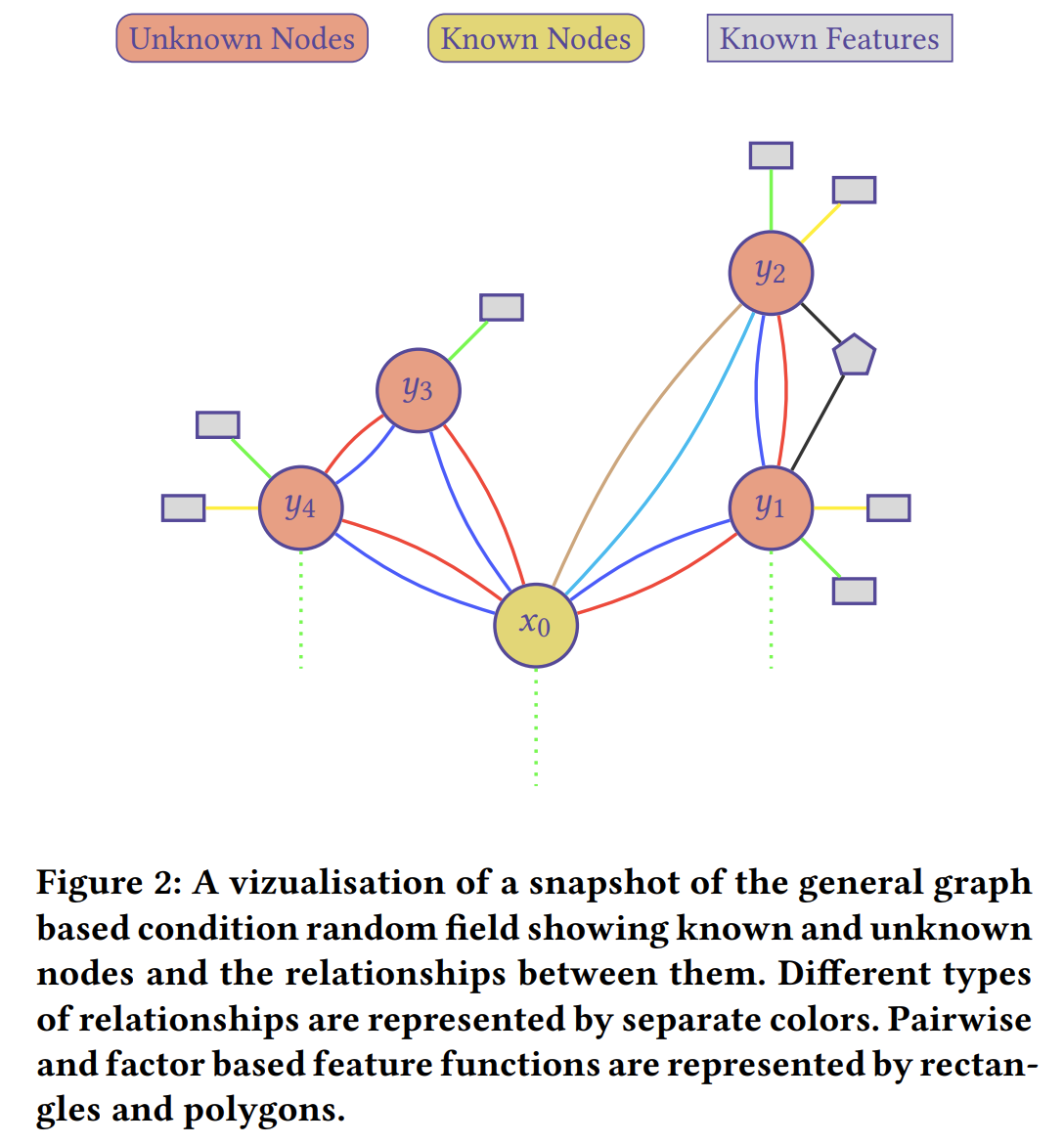
对于若干个随机变量组成的图,且假定这些变量之间有依赖关系,CRF 模型要根据已知的变量预测这个图中每个未知变量的值。具体到本文就是:对于一个binary中根据已知函数名(known nodes),已知特征的函数(known features),未知函数(unknown nodes),综合考虑,推断函数名。
这里在图上定义了两种关系(细节见tab2):
-
label-node: 一个函数 和它的特征(定义在tab1)的概率关系。
-
label-label: 两个函数之间的各种概率关系
比如就是两个函数之间相隔d 个node 的调用概率
CRF的推断就不写了,如果不太懂,可以将CRF看作黑盒,只需要知道通过CRF 同时得到所有未知函数名使得所有函数名的联合概率最大。
关于Symbol2Vec. 给函数赋予一个描述性的名字是相当主观的,或则说同一个函数可能具有两个在词法上完全不同的名字,它们却有相同的含义,这种情况是算法难以处理的。为了缓解这种情况,我们创建了一种方法来度量函数名的相似度。我们通过将函数名投影到高维向量空间中来做到这一点,这样语义相似的函数名在向量空间中看起来很接近,而不同的函数名则相距很远。
类似预Word2Vec,本文具体做法是:在二进制文件的调用图上预测给定中心函数周围上下文函数。
主要实验
Metric. 并非预测和真值完全相同才算正确,而是有两种判断方法:
- 通过NLP 处理函数名后,计算Jaccard 距离作为度量,当距离低于一个阈值时,就认为两者是相似的。
- 通过Symbol2Vec 计算语义相似度,设定一个阈值,作为相似的判断标准。
实验1
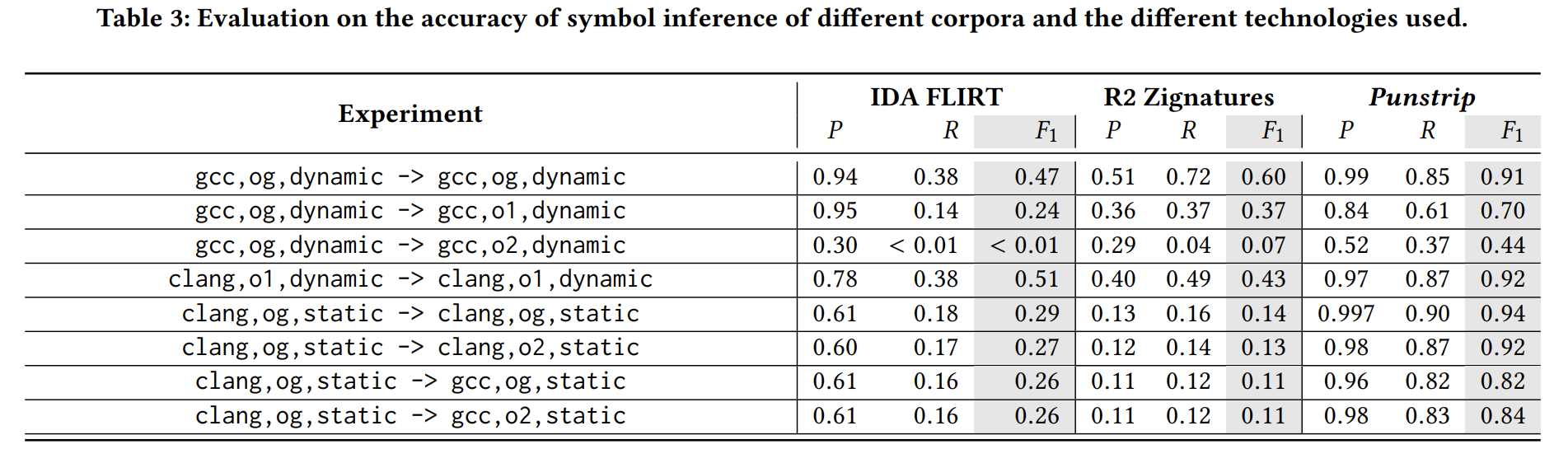
我们执行这个实验来评估我们的概率指纹如何识别编译到不同二进制文件和不同设置下的函数。在给定的编译选项训练集训练模型,然后在不同编译选项的测试集推断函数名。
Dataset. 二进制文件来自coreutils, moreutils, findutils, x11-utils and x11-xserver-utils,它们可以产生 149 个的二进制文件和 1,362,379 个符号。通过交叉编译产生可2132 个不同的二进制文件。149 个二进制文件分割为15:134作为测试集和训练集。另外,这些程序在它们之间具有适度的代码重用,我们确保训练集的函数名不会出现在测试集。
实验2
为了测试punstrip 是否可以学习到一般意义上的任意函数之间的抽象关系,有必要构建一个包含来自不同软件包的带有调试信息的大型二进制数据集。我们从Debian 软件源中的数千个开源软件包构建这个数据集。
Dataset. 188,253 个binary,得到82GB可执行文件,我们仅使用C语言编译的部分,17,549个binary,将这些可执行文件随机分成 10 个大小相等的组,进行10-fold 交叉验证。
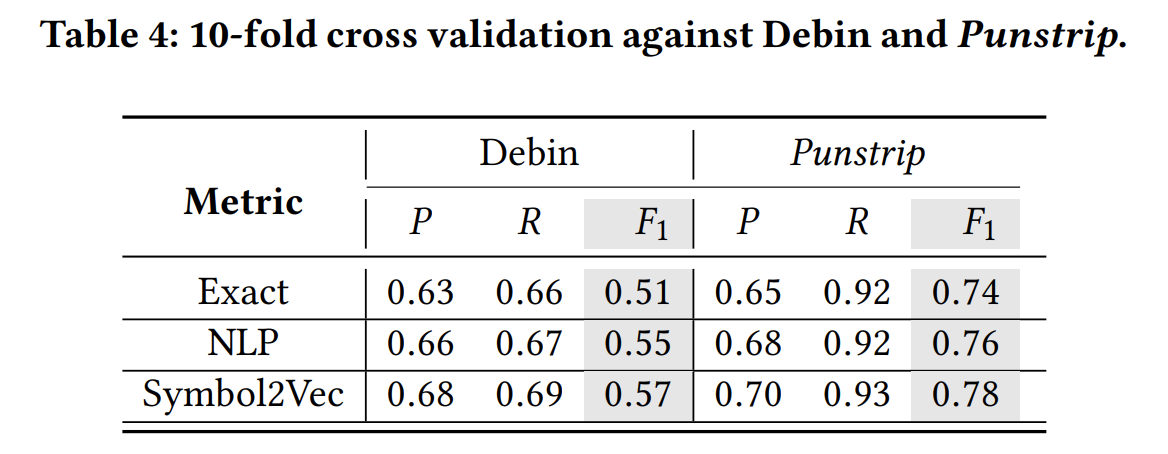
可以看到不管是精确匹配函数名还是使用NLP 或Symbol2Vec 作为评判标准,punstrip 都要强于DEBIN。
讨论
限制:
在我们的方法中,我们未考虑函数边界确定的准确性。在现实世界环境中,函数边界提取阶段可能会出现错误,由于恢复的图结构不准确,可能会对概率推理产生不良影响。
当汇编代码只出现微小变化时,我们的概率指纹成功概率更高;然而,在完全未知二进制代码,或者代码被混淆的情况下,punstrip 表现不佳。 换句话说,punstrip 受限于二进制分析的正确性,利用程序分析来恢复代码特征和关系,所有能误导或阻碍程序分析的技术都可能对punstrip 产生影响。
对抗限制:
punstrip 可以与现有的逆向工程软件套件或调试器相结合,以分析动态执行期间,包含未知代码的内存区域。
NERO
PACMPL 2020, Neural reverse engineering of stripped binaries using augmented control flow graphs
关键词
binary slice, call site, CFG, LSTM, Transformer, GCN
摘要
我们实现了一个新方法用于预测剥离二进制文件中的函数名。我们的方法结合了静态分析和神经网络模型。主要的思路是使用静态分析的方法增强函数调用点(call site)的表征,使用控制流图(CFG)组织这些调用点,最后分析这些调用点生成预测的函数名。我们使用这些增强调用点表征来驱动 graph-based, LSTM-based and Transformer-based 的函数名预测方法。
我们的实验表明,与当前最好的无静态分析的神经网络文本模型方法相比,我们方法分别提高了 28% 和 100%。
code: https://github.com/tech-srl/Nero
方法
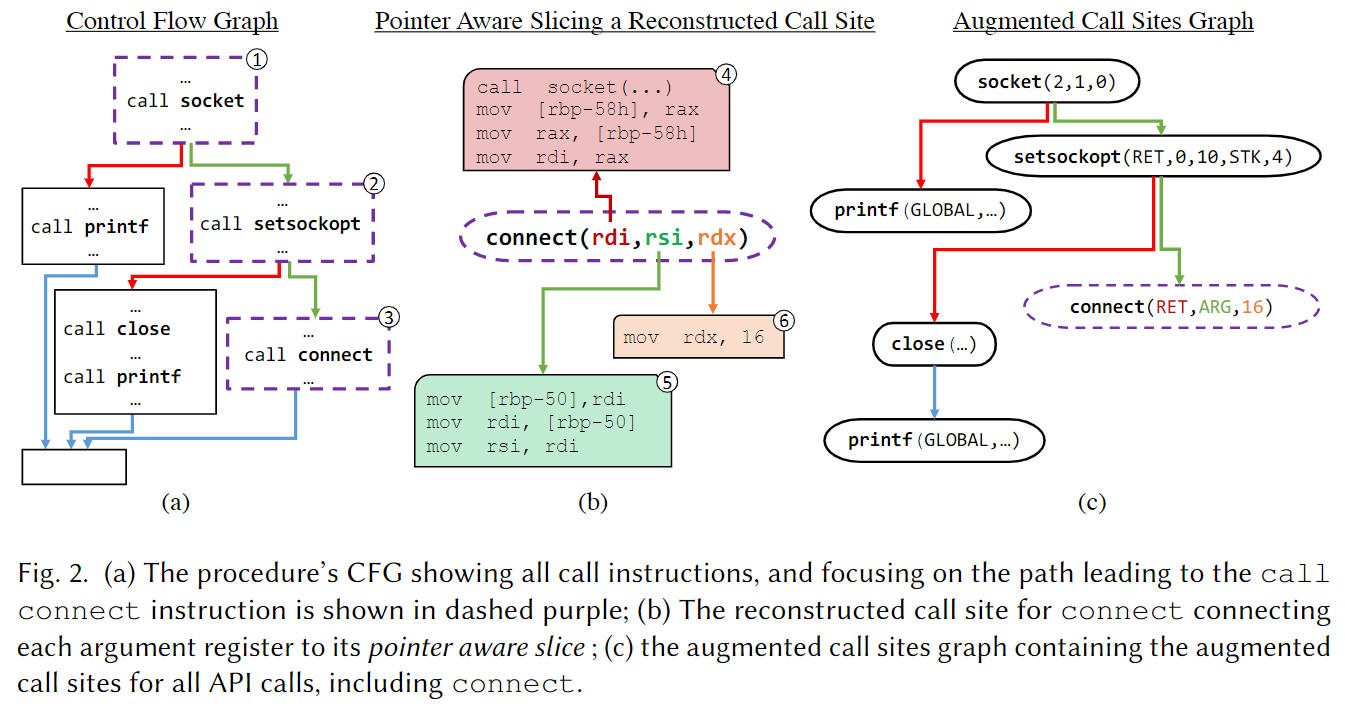
上图是Nero 基于控制流进行的调用点(call site)增强示例图:
(a) 是二进制程序的控制流图,其中省略了call指令之外的指令。我们现在关注call connect这条外部调用指令,从程序入口到这条调用指令的路径是紫色虚线的三个基本块。
(b) 这是call connect这条指令重构时每个参数的数据流切片,即与调用点处每个参数相关的指令序列。切片算法参考了Lyle and Binkley 1993,在原文中有详细阐述,这里不会展开细节。
© 基于 (b) 中的每个参数的程序切片,分析得到对应的抽象表示。抽象表示包括:(1) concrete value 具体数值 (2) ARG 代表传入该函数的参数 (3) GLOBAL 代表全局变量 (4) RET 代表调用另一个函数的返回值 (5) STK 代表栈上的变量。
完成上述处理后,每个函数得到一个 augmented call site graph ,基于这个增强调用图取执行路径作为神经网络的输入,训练神经网络预测函数名。
An augmented call site graph example
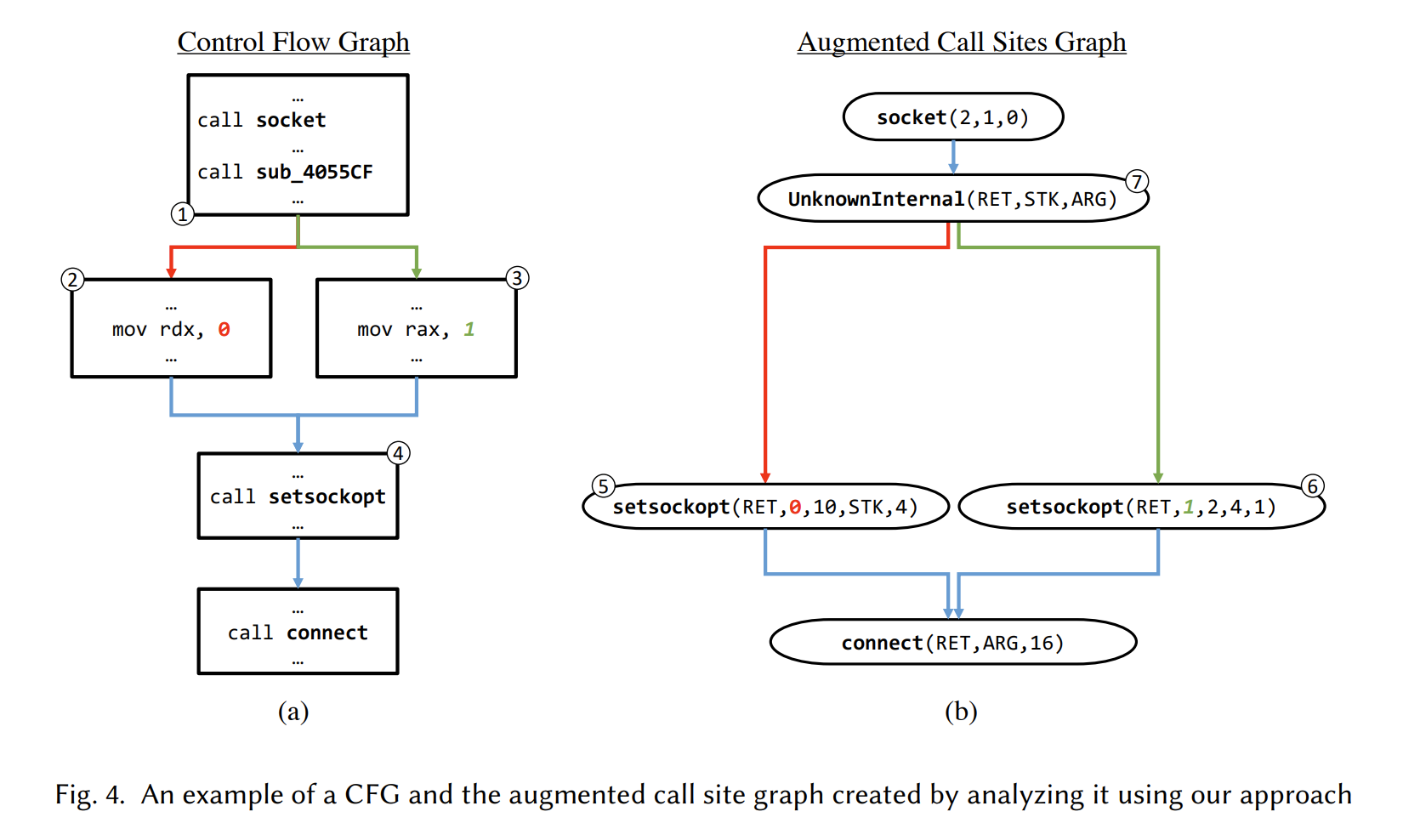
上图展示了一个CFG 和一个增强的调用图 augmented call site graph。CFG 中node 4在增强图中表示为两个不同的路径上的函数调用,原因是对node 4处的调用中的第二个参数做切片分析时选取的CFG 的路径不同,从而导致创建的切片也不同,之后得到的augmented arguments representation 也就不同。
同时也注意到node 1中的一个内部调用,缺少了过程名,就用UnknownInternel表示。
Models
这里简要阐述一下,本文使用的Models 如何输入上述得到的augmented call site graph。
1 embedding function name and argument
将训练数据库中的函数名分割成token,通过学习得到一个embedding vocab:,每个token都对应一个embedding。
此外,通过学习给每个抽象的参数值定一个embedding,包括具体数值也有。 记作:
2 encoding a call site
对于一个call site 把上述token 的embedding 求和得到一个向量作为encoding 的第一部分;把(高参设定)个参数的embedding 首位相接,作为第二部分。形式化为:
使用一个专门的no_arg 符号的embedding 补全 个参数。
3 Encoding Call Site Sequences with LSTMs and Transformers
使用LSTM-based 和Transformer-based 的seq2seq 模型,本文抽取一个程序上入口到终结节点的所有可能的路径,用这样一个集合表征这个程序。
注意,这里和传统的seq2seq 范式的区别在于,输入不是标准的单一符号序列,而是一组call site序列,所以这些model 可以说是 “set-of-sequences-to-sequence”。
4 Encoding Call Site Sequences with Graph Neural Networks
本文使用GCN 模型时,直接把一个程序的CFG 图作为输入。
这里由于直接输入CFG 不像上面输入call site 序列,所以要处理一下CFG :
从节点是基本块的CFG 开始,一个基本块上可能有多个函数调用。因此,我们将每个基本块拆分为一个调用点链,一个调用链的的第一个节点连接这个基本块所有传入的边,最后一个节点连接到该基本块的所有出边。
同样的,这里在重构调用点参数时,选取的CFG 上的路径不同构造出的参数抽象值或具体值可能不同,所以这里也复制了这些可能不同的调用点,组合所有参数的可能的值,如上面图fig4所示。
主要实验
Dataset. 我们的评估重点是在 Linux 上运行的 Intel 64 bit 可执行文件。我们从 GNU 代码仓库中收集了一个包含各种软件的数据集。其中不包含多种语言混合开发的软件。为了避免不同工程之间的代码重用问题,我们采取了以下策略:
- 排除同一工程的不同版本
- 排除C++编译的工程
- 排除可能是用于测试或者作为样例的工程
- 排除静态连接的文件
最终数据集包含67,246个函数用于训练,在二进制文件级别上按照 8:1:1 切割。统计结果:平均每个函数名2.42 (±0.04) 个token,每个函数489.63 (±2.82)个汇编指令,5.6 (±0.03)节点 (in GNN); 9.05 (±0.18) 路径 (in LSTMs and Transformers)。
数据集中大约有15%的函数没有外部函数调用,但是他们仍有内部调用,得益于我们的增强调用点的工作,这些数据也能用于训练。
Metrics. 我们采用了以前工作使用的评估方法,函数名切割成token,实行大小写无关、顺序无关和重复不敏感以及忽略非字母字符的评判标准,统计precision, recall 和 F1 指标。例如,对于真值时’open file’ 的函数名,预测为 ‘open’ 给出precision 100% recall 50%;而预测’file open input file’ 给出 67% 的precision 和 100% recall。
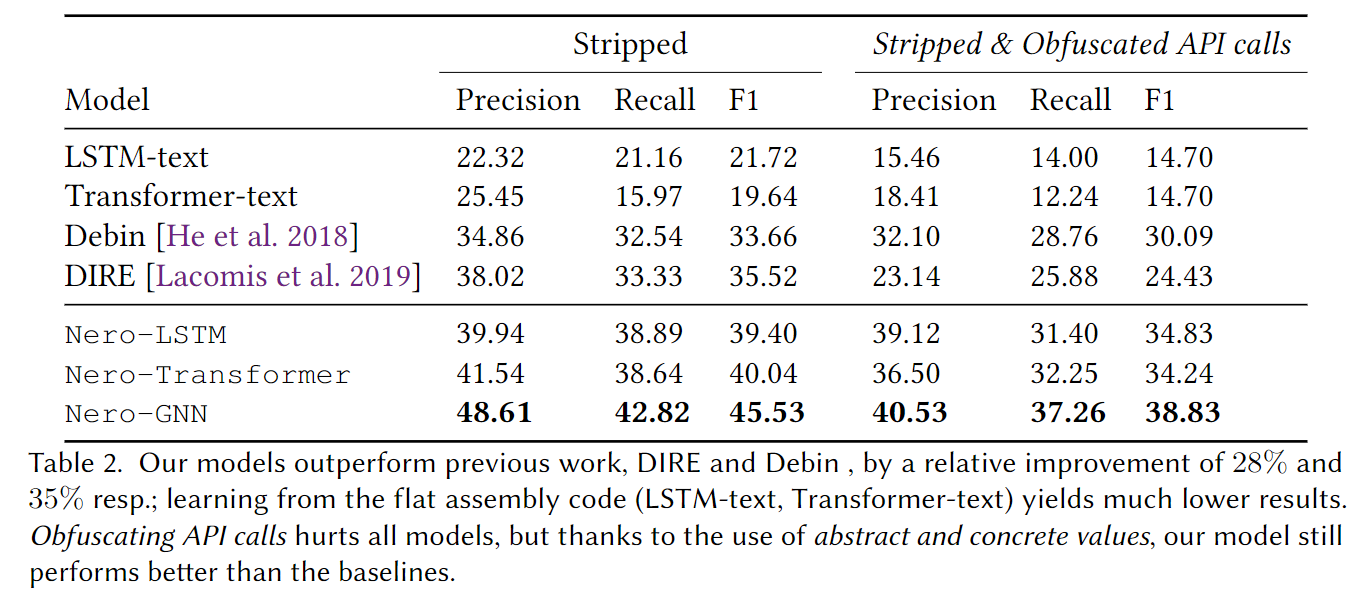
Nero 优于DIRE和Debin,分别有28%和35%的提升。混淆API调用的对抗性能,Nero要优于其他工具,主要就是Nero 更依赖增强调用点的分析工作。
消融实验
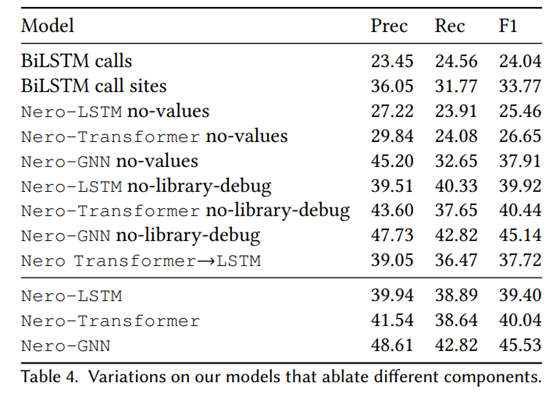
no-values: 调用点仅使用调用函数名,不分析参数,不使用任何增强的参数表示。
no-library-debug: 重构调用点的时候对外部调用不使用外部调用符号名信息。
可以看出,GNN 的效果在本文方法中优于set of sequences to sequences 的序列模型LSTM、Transformer。
去掉library-debug对三个模型的影响很小,可以说是误差级别了。
values对序列模型的提升较大,在F1上对LSTM、Transformer、GNN提升分别大约是14%、14%、8%。
讨论
Limitations:
Heavy obfuscations and packers. 在我们的评估实验中探究了API 混淆的影响,实验表明它们会导致模型的精度显著下降。要解决这些问题最好是在静态分析阶段检测它们并在尝试预测函数名之前采用一些反混淆和解包方法。
Representation depending on call sites. 由于我们对程序的表征是基于调用点的重建和抽象,该算法强假设目标程序至少有一个调用点,并且非常依赖静态检测和分析调用点的能力。另外,实验发现较小的程序(平均4个调用,10个基本块)预测函数名的效果小幅优于整体水平。
Predicting names for C++ or python extension modules. Nero 实际上可以用来预测类或类方法名。增加 C++ 代码进行训练并支持 C++ 的预测是一个很好的未来工作方向。 Python 扩展模块包含更多信息,也是一个可以扩展的方向。
本文决定专注于从 C 代码创建的二进制文件,是因为 C 二进制包含的信息量最少,而且我们比较的其他工作也是这样做的。