SafeDrop: Detecting Memory Deallocation Bugs of Rust Programs via Static Data-Flow Analysis
论文链接: https://arxiv.org/abs/2103.15420 Publisher: 2021, TOSEM, XuHui
因为写论文加上身体出毛病等等各种原因,最近一个季度啥都没post,本来计划每个月至少发一篇笔记之类的来督促自己学习,现在看来还是小命要紧,以后放慢进度,稳健工作,遇到有趣的工作我就尽量写点笔记发出来。😁
TL;DR 在Rust 编译过程中产生的 MIR 上,结合别名分析+数据流的静态分析方法,该方法针对它所分析的对象(MIR)设计了几种内存错误的pattern,通过静态分析检测内存释放bug。
0 摘要
Rust 是一个新兴的编程语言,旨在防止内存安全bug。然而现阶段 Rust 的设计也带来了一些副作用,使得内存安全问题的仍然存在。具体来说,它使用 OBRM(ownership-based resource management)和对未使用的资源强制自动回收(无垃圾回收器)。这使得Rust 程序也许会出现无效内存回收导致use after free 或 double free。文本研究无效的内存回收,提出了SafeDrop,这是一个静态的path-sensitive 数据流分析方法,用于探测上述bugs。我们的方法根据数据流图递归地分析每个Rust crate 的 API ,并且抽取每个数据流的所有aliases。实验结果证明我们的方法可以成功的检测到所有现存的CVEs。分析增加的开销对比原始的编译时间(编译阶段分析)从1%到110.7%不等。我们进一步应用我们的工具在真实世界的Rust crates,并且找到了8个存在无效内存释放的Rust crates。
1 Intro
本文工作针对真实世界中的Rust Crates 查找一种特定类型的内存安全bug,这项工作与 RAII(资源获取即初始化)相关。具体来说Rust 使用 OBRM (ownership-based resource management) 模型,这个模型假定资源在其所有者创建时被分配内存,一旦其所有者离开当前区域这个资源就应该被释放。理想情况下,Rust 应该保证没有悬垂指针和内存泄漏,即使程序产生异常。然而实际上我们观察到真实世界中Rust 存在 UAF (e.g., CVE-2019-16140) 和 Double Free 漏洞 (e.g., CVE-2019-16144)。
一般来说,内存释放错误是由unsafe 的代码触发的。 Rust 中需要unsafe 的 API 来提供对实现更细节的低级控制和抽象。而误用unsafe 代码可能会造成上述内存中的错误。而且更要命的是,当前的Rust 编译器在不安全代码的内存安全风险方面做得很少,只是假设开发人员应该负责使用它们。由于内存安全是Rust 提倡的最重要的特性,如果可能的话,减少这种风险是极其重要的。
为了解决这个问题,本文提出了 SafeDrop,一种静态路径敏感的数据流分析方法,用于检测由于自动释放机制导致的内存安全错误。SafeDrop 迭代地分析 Rust crate 的每个 API,并检查 Rust MIR(中级中间表示)中的每个 drop 语句是否可以安全执行。我们的方法采用meet-over-path(MOP)[1] 方法,并基于改进的Tarjan算法[11]提取每个函数的所有有价值的路径,这有效地消除了具有相同别名关系的循环中的冗余路径。
我们已将我们的方法实现为 Rust 编译器 v1.52 的一个 query(pass),并对此类类型的现有 CVEs 进行了实际实验。实验结果证明我们的方法可以在有限的误报之下成功地检测到所有现存的CVEs。
贡献总结:
- 我们的论文是第一次尝试研究“与 RAII 的副作用相关的“ Rust 中的内存释放错误。我们系统地讨论了该问题并提取了此类错误的几种常见模式。虽然我们的工作焦点是 Rust,但这个问题也可能存在于其他具有 RAII 的编程语言中。
- 我们设计并实现了一种新的路径敏感的数据流分析方法来检测内存释放错误。它包含多种精心设计,以便在不牺牲太多精度的情况下实现可扩展性,包括用于路径敏感分析的改进的 Tarjan 算法和用于过程间分析的基于缓存的策略。
- 我们已经对现有的 Rust CVEs 进行了实际实验,并验证了我们方法的有效性和效率。此外,我们发现 8 个 Rust crate 包含尚未发现的无效内存释放问题。
2 Preliminaries
主要阐述了以下四个方面内容,不赘述
- Rust 的内存管理
- Rust 编译器的基础知识
- Rust 的借用(Borrow)检查器
- Rust 编译器的Soundness 限制
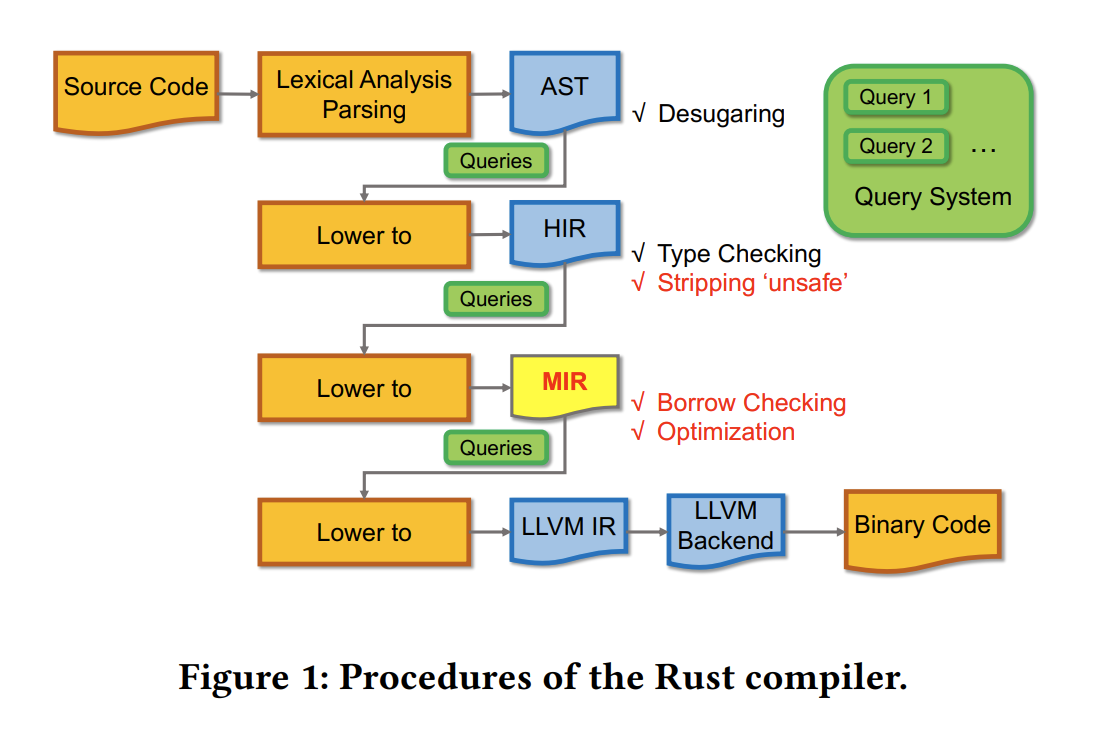
上图是Rust编译器的处理过程。
本章总结,当前Rust 编译器并没有算法来保证unsafe 代码中Raw pointer 和内存回收的安全性,这是本文分析的造成Rust 内存回收错误的主要原因。
3 Problem Statement
Rust 强制执行 RAII 并自动释放未使用的资源。在实践中,这种机制可能会错误地drop一些内存单元,并且容易出现内存安全问题。基于有缺陷的 Drop() 的出现,我们将这个问题分类为两种情况:1)在正常的执行路径上的无效drop;2)在异常处理路径上的无效drop。

上图是Rust 中会引发内存安全问题的 PoC(proof-of-concept)样例。
3.1 Motivating Example
Invalid Drop of Normal Execution.
Fig 2a 中 genvec() 函数是一个内部不安全的构造函数,它基于raw指针 ptr 创建向量 v。在这个 PoC 中,字符串 s 和向量 v 共享相同的内存空间。函数return后字符串自动释放,向量 v 成为一个指向已释放缓冲区的悬空指针,之后在 main 函数中使用此向量将导致 use-after-free。即使不再使用向量,当控制流超出 v 的作用范围,它将被自动丢弃并导致双重释放。在实践中发现了很多这样的bug,比如CVE-2019-16140是use-after-free,CVE-2018-20996 和 CVE-2019-16144 是double free。
Fig 2b 将上述问题以 MIR 的形式展示出来。_1 在 bb0 中创建了一个新的字符串并且在 bb5 中返回了基于_1创建的向量 _0 ,其别名传播链是1->5->4->3->2->8->0. 因此 _0 包含一个 _1 的别名指针。也就是说,drop _1 会导致 _0 变成悬垂指针。
为什么借用检查器不能添加对raw指针的支持来检测此类问题?问题在于Rust处理函数调用时的权衡设计。例如,_2 是通过调用deref_mut(mov _5)创建的 并且它的参数 _5 是 _1 的可变别名。为了简单起见,Rust 假定每个参数都应该:要么将它的所有权转移给callee函数,要么通过 copy-trait 复制变量,并且复制体不与母本共享所有权。这样的假定使得借用检查器免于做复杂的过程间分析。而由于这个决定,使得 unsafe Rust 代码可能出现漏洞。请注意,from_raw_parts() 是一个 unsafe 函数,并且它在本例中是导致内存回收的原因。‘unsafe’ 标记在 MIR 层就被剥离了,Rust 编译器在 MIR 中是看不到的,也就不能区分安全代码的边界了。此外,当前 Rust 的编译器没有加入为 raw pointer做 alias checking 的功能。因此,上述问题解决起来是不太容易的。
Invalid Drop of Exception Handling.
在一些现实世界的错误中,内存释放问题仅存在于异常处理路径中,因为程序会出现恐慌并进入unwinding(栈展开)过程。例如,如果程序崩溃,CVE-2019-16880 和 CVE-2019-16881 就会出现双重释放问题; CVE-2019-15552 和 CVE 2019-15553 可能会在异常处理中 drop 未初始化的内存。Fig 2 中的 PoCs 展示了这个问题。
假设开发者通过增加一个 mem::forget() 修复了这个bug,在 Fig 2a+b 中能防止bb6 drop(_1)。然而,如果你在 mem::forget() 和创建向量 v 之间访问 v ,那么你的访问仍然是漏洞程序。如果程序在这些点上panic了,那么根据RAII的原则,Rust应该在栈展开的时候调用 Drop() 释放资源。如果存在具有“别名 drop-trait” 的实例(变量),删除这些实例会导致双重释放问题。此外,mem::forget(s) 拿走了字符串 s 的全部所有权,它通常尽可能晚地使用,以便其他语句仍然可以使用该字符串。
同样,drop 未初始化的内存也是异常处理过程中的一个常见问题。Fig 2c 和 Fig 2d 演示了一个 PoC,它首先应用一个未初始化的缓冲区,然后再对其进行初始化。但是,如果程序在缓冲区完全初始化之前发生恐慌,堆栈展开过程将丢弃那些未初始化的内存,如果缓冲区有指针,这类似于 use-after-free,毕竟调用drop的时候这些指针还未初始化。
3.2 Problem Definition
Definition 3.1 (Dropping buffers in use). 如果程序错误的释放了一些后续会被访问的缓冲区, 这可能导致悬垂指针最终导致 use-after-free 和 double-free.
Definition 3.2 (Dropping invalid pointers). 如果无效指针成为悬垂状态,那么移除这个指针会造成double-free; 如果无效指针指向的未初始化的空间中包含指针类型,删除该指针可能会递归删除其嵌套指针并导致无效的内存访问。
3.3 Typical Patterns
清单2:
// Listing 2: Typical patterns checked for invalid memory deallocation in SafeDrop.
// (UAF: use after free; DF: double free; IMA: invalid memory access)
Pattern 1: GetPtr() -> UnsafeConstruct() -> Drop() -> Use() => UAF
Pattern 2: GetPtr() -> UnsafeConstruct() -> Drop() -> Drop() => DF
Pattern 3: GetPtr() -> Drop() -> UnsafeConstruct() -> Use() => UAF
Pattern 4: GetPtr() -> Drop() -> UnsafeConstruct() -> Drop() => DF
Pattern 5: GetPtr() -> Drop() -> Use() => UAF
Pattern 6: Uninitialized() -> Use() => IMA
Pattern 7: Uninitialized() -> Drop() => IMA我们说明了此类错误的几种典型模式。请注意,由于正常执行路径和异常处理路径的数据流方法是相似的,因此我们不会在这些模式中进一步区分它们。清单 2 从语句序列的角度总结了 7 种典型的无效内存释放模式。
模式 1 和模式 2 对应于我们的Fig 2b 的 PoC,它会导致 UAF 或 DF。我们使用 GetPtr() 作为获取指向具有 drop-trait 的实例的 raw 指针的一般表示,并使用 UnsafeConstruct() 来表示用于构造新别名的 unsafe 函数调用(例如,from_raw_part())。
模式 3 和模式 4 类似,但交换了 UnsafeConstruct() 和 Drop() 的顺序。
模式 5 没有 UnsafeConstruct(),但直接使用悬空指针并导致 use-after-free。
模式 6 和模式 7 对应于我们的Fig 2d 的 PoC,它与未初始化的内存有关。我们使用 Uninitialized() 来表示没有初始化的具有 drop-trait 的实例的构造函数。使用未初始化的内存或直接删除它都容易受到无效内存访问 (IMA) 的影响。
4 Approach
4.1 Overall Framework
我们使用路径敏感的数据流分析方法来解决这个问题,并将其集成到名为 SafeDrop 的Rust 编译器中。下图Fig 3为总览:
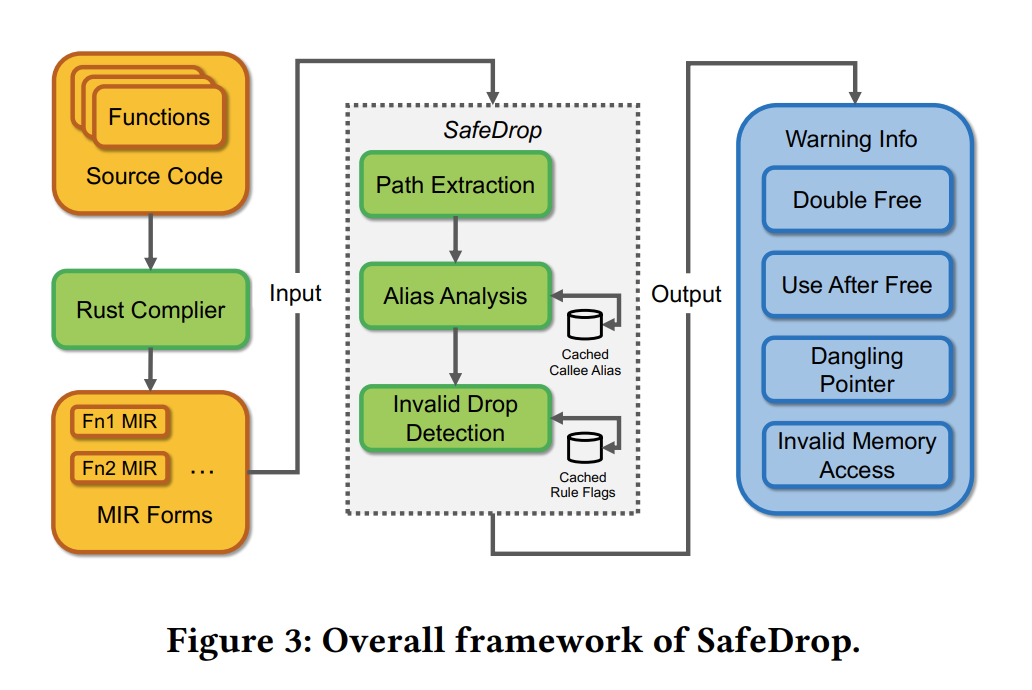
方法的关键步骤:
-
Path Extraction
SafeDrop 采用 meet-over-paths 方法来实现路径敏感。由于函数的路径可能是无限的,我们采用一种基于 Tarjan 算法的改进算法来合并冗余路径并生成“生成树”。遍历这棵树,最后枚举出所有有价值的路径。
-
Alias Analysis
SafeDrop 对字段敏感(field-sensitivity)。此步骤分析变量之间的别名关系以及每个数据流的复合类型的字段。 SafeDrop 也是过程间的,上下文无关的。它缓存并重用获得到的 “被调用者(callees)在返回值和参数之间的别名关系”。
-
Invalid Drop Detection
基于上面建立的别名集合,这一步在所有数据流上和记录的可疑代码片段上,搜索所有漏洞pattern。
下面来详细说一下这几个步骤。
4.2 Path Extraction
meet-over-paths method 会遍历函数的cfg,枚举所有有价值的路径。在SafeDrop中,有价值路径应该满足两个标准:
1)有价值的路径应该是多个代码块的唯一的集合,其中必须包含开始节点(函数入口)和推出节点。
2)不能是任何其他有价值路径的子集。
如果在第二个标准有冲突的路径,我们只选择具有更多独特代码块的路径。这样,我们就不必重复遍历循环,而只需要考虑循环块的最大集合。有效性可以根据SSA形式的代码的别名分析规则自我解释。
我们使用修改的Tarjan算法来移除冗余路径。这个算法的细节如下:

1-6 首先使用改进的 Trajan 算法生成图的生成树
7 遍历生成树访问所有有价值的路径
传统的 Tarjan 算法用于分解图的强连通分量(SCC)并简洁地去除循环(line 2)。因此,SafeDrop 可以将强连通分量收缩为点,并生成该图的生成树(line 3)。理想情况下,生成树枚举所有有价值的路径,而不需要重复遍历循环。但是,由于某些特定的 Rust 语句,这种粗粒度的方法可能会导致不正确的分析结果。例如,Rust 对枚举类型引入了一种批判性设计,这使得传统的 Tarjan 算法不太准确,因此我们应该进行一些修改。Fig 4 展示了这样一个例外情况以及我们相应的解决方案:
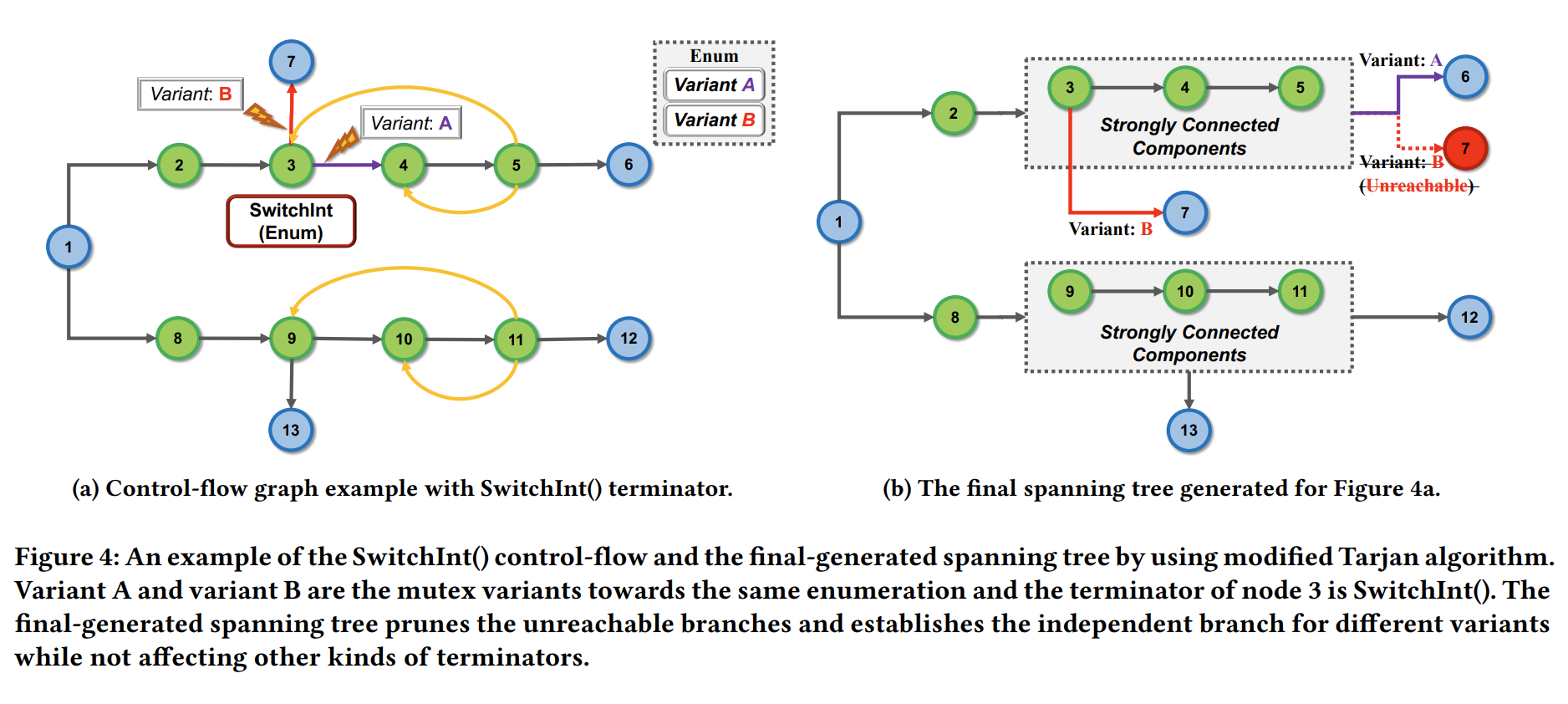
解释一下,Fig 4 使用了一种特定类型的终结符 SwitchInt() ,这就是导致不准确的原因。 SwitchInt() 的参数是一个枚举类型,枚举的变化(A or B)决定控制流的走向,例如Fig 4a 中的node 3 在收缩SCCs到一个点后,由 SwitchInt() 链接的分支互相排斥的,因为 A 和 B 是互斥体。
因此,SafeDrop 明确地将连续的 𝑘 个 SwitchInt() 指向相同的枚举参数,其中包含 𝑛 个可能的变体(line 5),为所有终止符枚举每个变体一次以解决互斥冲突(line 4-6 )。这种做法可以修剪不可达路径,并且为不同变体(Fig 4b 中node 1 的上部分支)构建独立路径,而不影响其他终结符(Fig 4b 中node 1 的下部分支)。该方法最终将本期的时间复杂度从降低到 。
接下来遍历所有生成树,该过程将抽取出所有有价值的路径。
由于 SafeDrop 实现了meet-over-paths方案,因此它为每条路径分配了独立的遍历状态,在遇到多分支节点时备份状态,从递归返回时将恢复状态(line 18)。这个操作保证了进入不同分支前遍历状态的一致性。
尽管我们利用修改后的 Tarjan 算法来删除冗余路径,但路径爆炸并非完全不可避免。未解决的路径爆炸主要是由嵌套的条件语句而不是循环产生的,因此我们为其设置了一个较大的阈值。如果计数器超过上限,SafeDrop 将执行传统的半格方案,这是精度和速度之间的权衡。
4.3 Alias Analysis
SafeDrop 对每个路径执行别名分析并为每个程序点建立别名集(算法1 Line 11)。在本小节中,我们首先讨论别名分析的基本规则,然后介绍我们如何执行过程间别名分析。
Basic Rules for Alias Analysis.
… 暂时省略,待补充
清单3:别名分析中的类型过滤器。当且仅当以递归方式过滤所有字段并且这些类型应同时实现 Copy trait 时,才会过滤带有星号的复合类型。
Value := Type::Bool : The primitive boolean type.
| := Type::Char : The primitive character type.
| := Type::Int : The primitive signed-integer type.
| := Type::UInt : The primitive unsigned-integer type.
| := Type::Float : The primitive floating-point type.
| := Type::Array *: The homogeneous product types.
| := Type::Structure *: The named product types.
| := Type::Tuple *: The anonymous product types.
| := Type::Enumeration *: The tagged union types.
| := Type::Union *: The untagged union types.清单4:别名关系的标准以及赋值中对右值的匹配操作。SafeDrop 对move赋值使用零开销的设计,因为这是右值的所有权和别名关系的转移。SafeDrop 在分析之前构造一个指向变量(field)的映射,并在遇到move赋值时将映射从 RValue 传输到 LValue。
LValue := Use::Copy(RValue) => e.g. _2 = _1 Use Copy Trait
| := Use::Move(RValue) * => e.g. _2 = move _1 Use Drop Trait
| := Cast::Copy(RValue) => e.g. _2 = _1 as i32 Cast Types
| := Cast::Move(RValue) * => e.g. _2 = move _1 as i32
| := Ref(RValue) => e.g. _2 = &mut _1 Create Reference
| := AddressOf(RValue) => e.g. _2 = *mut _1 Create Raw PointerInter-Procedural Alias Analysis.
基本的别名分析是过程内方法。它流敏感地分析每条语句,将每个程序的别名关系存储为不相交的集合。然而,这样的分析是unsound的,因为它忽略了函数调用。如果执行路径上包含函数调用,我们将执行过程间的别名分析,来获取调用参数和返回值之间的别名关系。
Callee Analysis. 程序的调用链嵌入在每个基本块的终结符中,包含参数、返回值和内部被调用者ID。随着函数调用的到来,SafeDrop 调用一个查询,通过其内部 ID 向编译器询问被调用者的最终优化的 MIR。 然后 SafeDrop 遍历这个 MIR 并为其变量建立别名集。被调用者上的别名分析最终返回一个包含参数和返回值之间的别名关系的结果给它的调用者。
Recursion Refinement. SafeDrop 采用**不动点迭代(fixed-point iteration)**的方法解决递归调用问题,它维护一个调用栈来确保每个函数ID只在栈上出现一次。函数第一次到达时将它的ID入栈,SafeDrop 将在返回值和参数之间设置默认别名关系(false),并中止调用它自己以防止无限递归。考虑到递归调用通常会退出并且别名关系可能同时发生变化,分析器应该使用更新的别名结果重新执行 SafeDrop 的分析算法到堆栈中的函数,直到最终的别名关系达到不动点。
Cache Refinement. 由于 SafeDrop 是一种通过meet-over-paths的方法,因此参数和返回值之间的别名结果是所有有价值路径的并集(算法1 line15)。即,一个参数与返回值有别名关系,只要它至少有一个路径。 SafeDrop 只需要对给定函数分析一次。第一次遍历该函数后,分析结果会被缓存到哈希表中(line 9),再次遇到该函数时分析器可以直接得到结果。
4.4 Rules for Invalid Drop Detection
一次内存释放的安全性通常取决于别名集。对于每条路径,SafeDrop 对每个内存释放语句都会执行流敏感的检测,以确认它是否会引发内存安全问题(line 12)。如果检测到内存释放错误,SafeDrop 将会记录此问题的类型和相关源代码,然后将结果合并到path末尾(line 15)。
SafeDrop 维护一个污点集来记录释放的缓冲区以及返回的悬空指针。它将dropping变量添加到污点集中,如果在path终止符中找到 Drop() 就将其标记为污点源。对于复合类型的变量,SafeDrop 会增加每个drop-trait 字段到污点集中,而不时整个变量。污点源在别名集中传播并污染其他别名。 然后 SafeDrop 迭代检查程序使用的变量和每个程序点的污点集中的所有元素之间的别名关系。有个例外,我们将 uninitialized() 构造的变量插入到污点集作为变量声明的时间,如果稍后初始化,则删除该变量。
根据Sec3中描述的几种存在漏洞的典型模式。我们总结了四个规则来判断path是否存在由无效内存释放引起的内存安全问题,所有这些规则都将应用于正常执行和异常处理path上,如下所示。
- Use After Free: The taint set contains the alias of the using variable in a statement or passing this variable to a function.
- Double Free: The taint set contains the alias of the dropping variable in a Drop() terminator.
- Invalid Memory Access: The taint set contains an uninitialized variable at the time of using and dropping.
- Dangling Pointer: The taint set contains the alias of the returned pointer. Although it loses the using context, this pointer is actually buggy and highly unsafe to use.
使用SafeDrop分析后,一条规则标记为 true 标志表示此函数内部存在对应类型的内存安全问题。这些标志被缓存到哈希表中,作为过程间分析(line 9)之后的分析结果的一部分。对于每个路径,当 SafeDrop 完成对选定路径的遍历(line 15)时,这些标志以及参数和返回值之间的别名关系将被合并。
4.5 Corner Case Handling
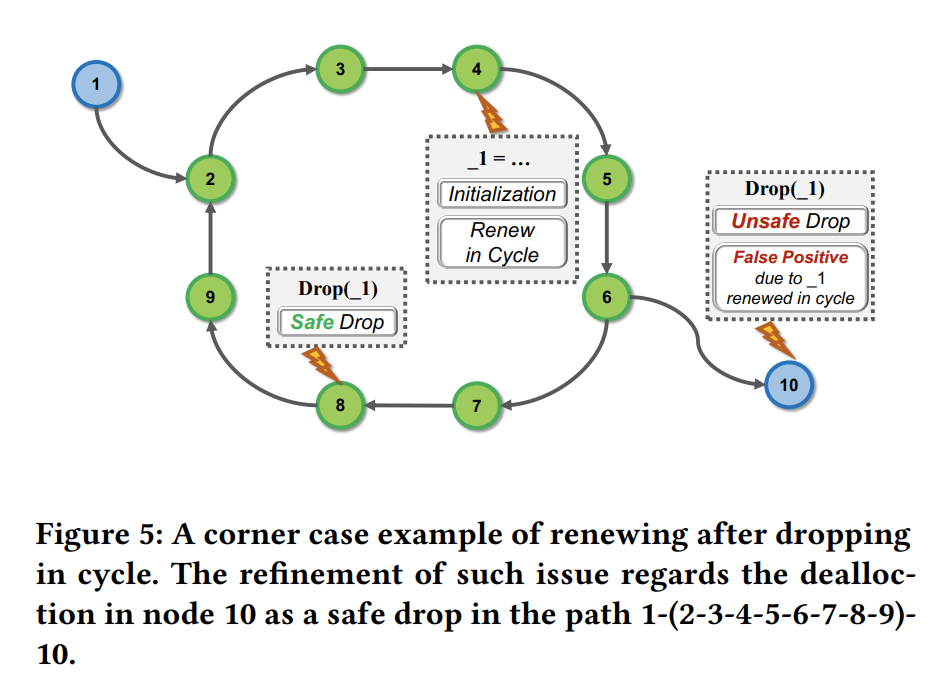
修改后的 Tarjan 算法生成生成树以提取有价值的路径,这个过程消除了循环中的冗余遍历。但是,存在一种引入大量误报的极端情况,我们以Fig 5 为例。在Fig 5 中,_1被初始化并drop在 SCC (2-3-4-5-6-7-8-9)上。 在路径 1-2-3-4-5-6-10 中节点 10 的释放是安全的,在路径 1-(2-3-4-5-6-7-8-9)-10 中被视为无效drop。第二条路径确实是误报,因为 _1 在节点 4 中更新,但我们省略了从节点 2 到节点 6 的两次遍历。
因此我们做出了细化:SafeDrop会记录变量的定义块,并验证是否“指向同一变量的重复drop的分支” 是在 “SCC中定义块和释放块之间”。细化的正确性是基于别名分析中别名关系合并的单调性。
5 Experiment
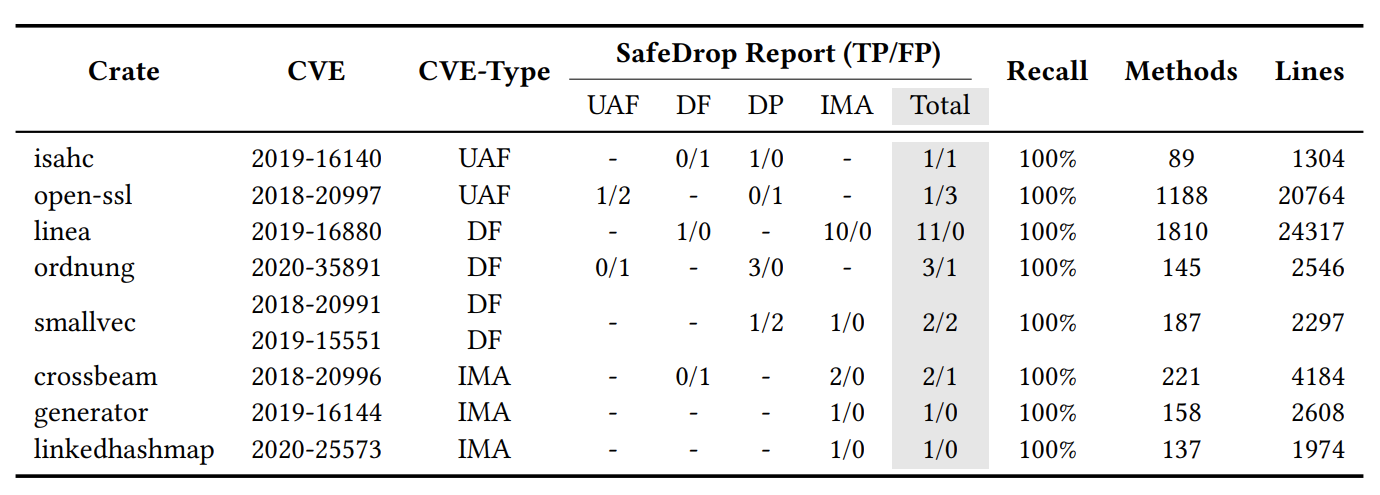
Tabel 1:已被报告过的CVEs上的实验结果。这些CVEs包含四种bug(UAF=use after free, DF=double free, DP=dangling pointer, IMA=Invalid memory access)。这里的结果已通过人工检查和分类。报告的 bug 在表中被分类为 True Positive/False Positive (TP/FP)(使用 “-” 代表 0/0 ),我们还统计了方法数和代码行数来表示 crate 大小.
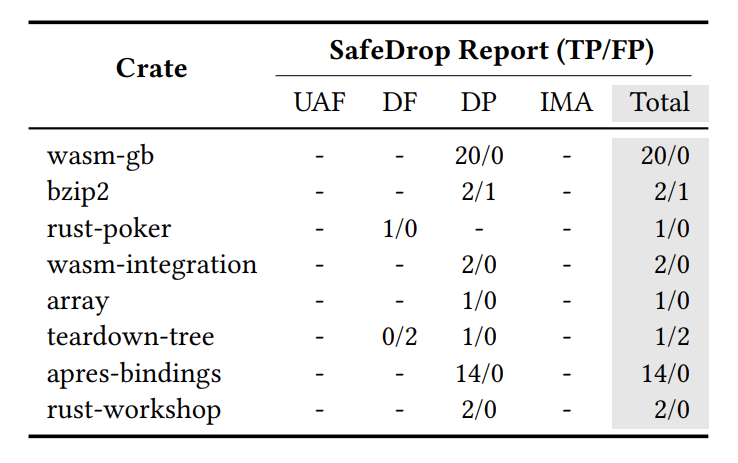
Tabel 2:适应性的实验结果。我们选择了一些使用unsafe代码块的crates来测试本文方法。这8个crate中的问题是未曾被人报告过的。
下图是一个样例,这是一个异常处理path上的无效drop,匹配了清单2 中的pattern 2。

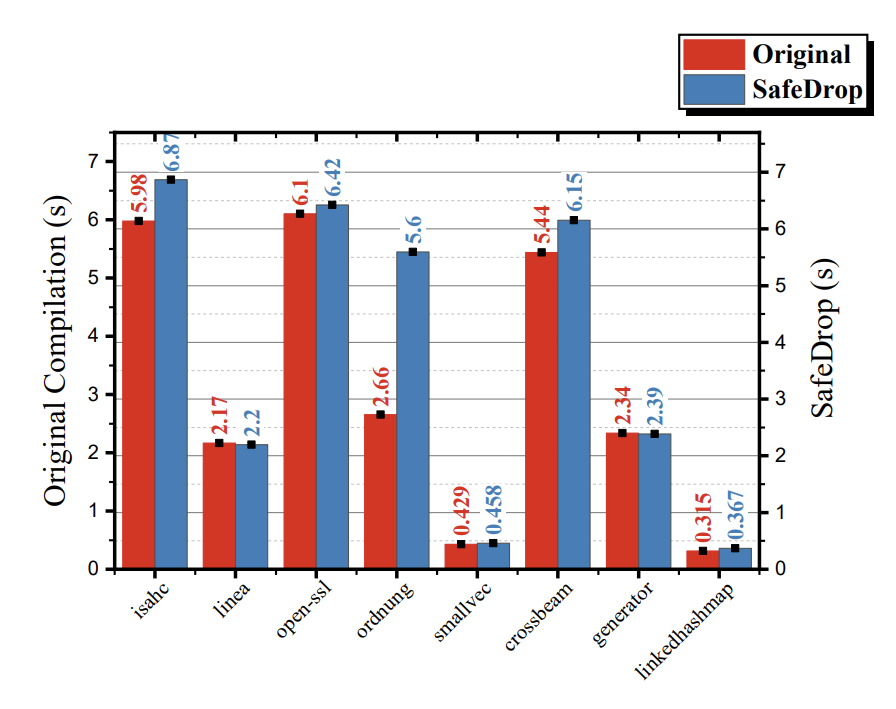
效率:
我们在比较了原始编译器的编译时间和SafeDrop分析时间,可见SafeDrop不会消耗过长的分析时间(通常不会超过原始编译时间的 2 倍)。
validity
False Positives.
过程间别名分析严重依赖于query optimize_mir 来获取被调用者的 MIR 。但是,由于编译器的内部设计,SafeDrop 无法捕获某些 MIR,例如某些特定的 trait 实现。SafeDrop的补救措施是,在运行类型过滤器之后,我们的方法会在未过滤的参数和返回值之间建立别名关系。通过这种操作提升别名辨识的soundness,虽然这可能导致一些false positive,但是就不会丢失别名信息了。由于这些情况并不普遍,并且类型过滤器可以识别大多数明显的错误,因此在 SafeDrop 中的误报仍然是可管理的(可接受的)。特别是,我们删除了从 Clone trait 建立的别名,因为函数 clone() 的返回值是对原始变量的深拷贝。
False Negatives.
Rust 对内联函数采用了一些tricky的设计,这可能导致一些误报。query可以成功地从编译器获取这些函数的 MIR,但 MIR 内容是空的。因此 SafeDrop 会丢失一些别名关系。此外,SafeDrop 不支持primitive array type, closure, raw pointer offset, 和 function pointer,这可能会导致漏报。
参考文献:
论文链接: https://arxiv.org/abs/2103.15420 Publisher: 2021, TOSEM
【1】Glenn Ammons and James R. Larus. 1998. Improving Data-Flow Analysis with Path Profiles. In Proceedings of the ACM SIGPLAN 1998 Conference on Programming Language Design and Implementation (Montreal, Quebec, Canada) (PLDI ’98). Association for Computing Machinery, New York, NY, USA, 72–84. https://doi.org/10.1145/277650.277665
【11】Harold N. Gabow and Robert Endre Tarjan. 1983. A Linear-Time Algorithm for a Special Case of Disjoint Set Union. In Proceedings of the Fifteenth Annual ACM Symposium on Theory of Computing. Association for Computing Machinery.