SoK: Demystifying Binary Lifters Through the Lens of Downstream Applications
Link: https://www.computer.org/csdl/proceedings-article/sp/2022/131600a453/1wKCev3wlbO
Publisher: S&P, 2022
摘要
最近的研究有表明,二进制lifter 可以生成功能和逻辑正确的 LLVM IR 代码,即使对于复杂的情况也能成功。
本文从新的评估视角对二进制lifter 进行了深入研究。解释二进制lifter 的”表现力“,揭露其恢复出来的LLVM IR 可以多好地支持下游二进制分析任务。为此,我们通过编译 C/C++ 程序和提升相应的可执行文件来生成相对应的两种 LLVM IR 代码。然后,我们将这两种 LLVM IR 代码提供给三个关键下游应用程序(指针分析、可辨别性分析(discriminability analysis)和反编译),并检查是否产生了不一致的分析结果。我们从由各种编译器、不同的优化选项和不同的架构生成的总共 252,063 个可执行文件中研究了由行业或学术界开发的四种流行的静态和动态 LLVM IR lifter 。
我们的研究结果表明,现代二进制lifter 提供了非常适合可辨别性分析和反编译的 IR 代码,并表明这种二进制lifter 可以应用于常见的基于相似性或代码理解的安全分析(例如,binary diffing)。然而,提升的 IR 代码似乎不适合严格的静态分析(例如,指针分析)。
为了更全面地了解二进制lifter 的实用性,我们还在三个安全分析任务(Asan 地址错误检查、binary diffing和 C 反编译)上比较了 支持lifter的方法 与 仅使用二进制汇编 的工具之间的性能。我们总结了我们的发现,并为正确使用和进一步增强二进制lifter 提出了建议。我们还探索了使用提升的 IR 代码提高指针分析准确性的实用方法:用lifted IR 增强 Debin(一种用于预测调试信息的工具)。
Debin! 世界线收束了。
0x1 Introduction
贡献
- 提出了一个对二进制lifter 评估的新视角,区别于过去的功能正确性视角,我们关注在lifted IR 需求的视角,即其得到的IR是否能很好的支持下游任务。
- 我们选取了三种安全研究场景下的基本下游任务,为了顺利的评估各种静态和动态的lifter,我们投入了相当大的人工。我们的研究是在交叉编译器、交叉优化和跨架构设置中进行的。为了获取更综合的评估结构,我们还在三个主流的安全任务中直接比较了支持lifter和纯二进制汇编两种 方法。
- 我们研究的结果和意义:现代二进制lifter 的限制——支持严格的静态分析的能力,其解决方案——使用Debin。我们的发现为用户提供了关于如何使用 LLVM 基础设施分析低级二进制代码以实现安全目的的指南,并指出了开发人员需要对Lifter 改进的方向。
0x2 Preliminaries
预备知识。
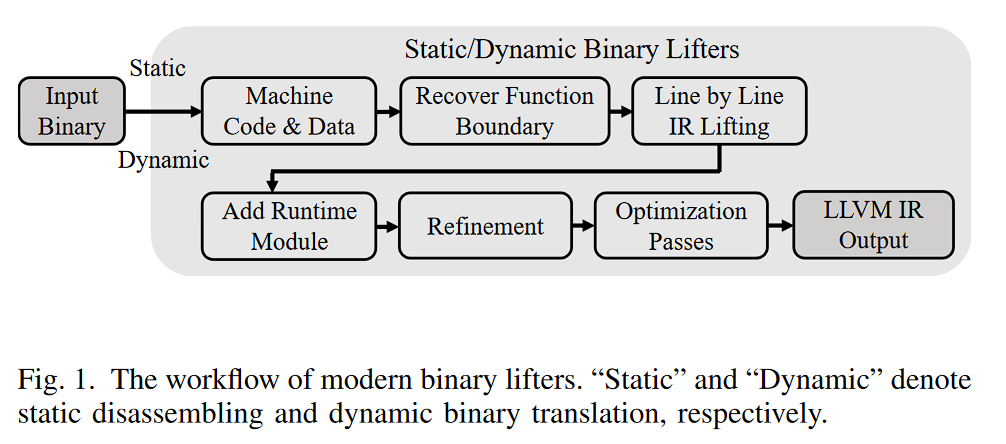
静态和动态lifter的工作流。”Static“和”Dynamic“分别表示静态反汇编和动态二进制翻译。
本章介绍了上图中每个阶段大概是怎么做的,以及现代lifter 在各个阶段的不同做法,或者说特性。
0x3 Motivation Example

fig2 给出了一个study case,关于C源码© 其编译的LLVM IR,和通过编译后的二进制文件lifted IR。
Emulation-Style IR (EIR) vs. High-Level IR (HIR).
关于这两种IR,后文Sec6 给出常见的lifter 生成的类似fig2©的EIR,或者更高级的HIR类似于fig2(b)编译的IR code。Sec2 中讲述的Refinement 技术就是把EIR转换成HIR的过程。Sec2 指出为了弥合EIR和CIR 之间在局部变量上的差别,现代lifter 实现了一些analysis passes 和启发式方法去恢复局部变量,另外,对变量类型的精确恢复也有助于静态分析,见Sec6-B。然而不是所有lifter 都实现了refinement 过程,本节中的例子McSema 就没有refinement,其他lifter 的情况我们会在Sec6详细展示。
为了便于表述,由 Clang 从源代码编译的 LLVM IR 被称为Compiled IR (CIR),Lifter根据emulation 范式产生的emulation-style IR 称为EIR,通过refinement之后的EIR称为high-level IR (HIR)。
Transformations Involved in Emitting EIR and HIR.
在构建lifter codebase 过程中投入了大量的人工努力,我们把汇编代码提升到IR 的过程中使用到的transformations 分成三类:
-
optimizations offered by the LLVM framework
simplifies lifted IR code in a functionality-preserving manner.
-
simple optimizations developed by lifters
移除臃肿的 utility functions, 如果正确实现的话这个transformation也应该生成 functionality-preserving
-
transformations recovering high-level program features developed by lifters
尝试恢复编译期间扔掉的信息
根据人工分析总结,Lifter使用1和2能生成EIR,结合123才能生成HIR。
0x4 Study Overview
关于如何度量IR的好坏,我们将Compiled IR Code 的表现作为上界,使用三个下游任务作为评估方法,通过lifted IR Code 和Compiled IR Code 之间的性能的接近程度作为衡量标准。具体到每个任务上的评估度量标准后面会讲。
接下来介绍了三个下游任务:
- Pointer Analysis
- 本研究的第一部分:是否可以使用lifted IR 代码傻瓜式(即不对IR做修改)的启动指针分析。
- 使用SOTA的 LLVM pointer analysis library: SVF。
- Discriminability Analysis
- 可辨别性分析是各种基于相似度分析的安全应用的基础,比如恶意代码聚类,代码剽窃检测等应用。
- 我们扩展了在 LLVM 框架中开发的代码嵌入(code embedding)工具 ncc 。将代码映射到数值空间,根据其余弦距离判断相似度。ncc 使用”Contextual Flow Graph“来理解LLVM IR代码,这个Graph 结合了IR 数据流和控制流特征。然后ncc 使用基于图神经网络的模型生成程序的数值向量。ncc也提供了一个分类模型用于分类GNN生成的数值向量,这个模型训练在POJ-104。
- 使用ncc的分类来评估IR代码的好坏,即越高的分类精度表明更容易确定两个 LLVM IR 程序的(不)相似性。
- C Decompilation
- 这里评估的方法是:compiled IR 和lifted IR 代码是否可以反编译得到相似质量的反编译 C 代码。
- 使用的反编译工具是llvmir2hll,它是retdec的一部分。
0x5 Study Setup
A. Binary Lifters
本文所调研的Lifter如下表所示:

提一嘴BinRec,这是最近才发布的动态lifter,它以可执行文件作为输入,采用符号执行引擎 挖掘可执行路径,该引擎运行在QEMU上,它对于每条记录下来的路径都可以生成一条LLVM IR 路径。 提供RevGen 用于生成LLVM IR,RevGen 使用IDA-Pro 和McSema 作为前端,这和我们的评估有重叠,所以本文实验中BinRec 不使用RevGen 。BinRec 代表最先进的动态lifter,其设计目标之一就是functional correctness,这在我们后面的实验中得到了很好的证明。
作者对上述四个工具做了一番介绍,然后总结:这四个工具可能是本文撰写时三个最好的静态lifter和一个最好的动态lifter。
B. Downstream Task Setup and Test Case Selection
Pointer Analysis.
我们使用 SVF 提供的所有 24 个流量敏感测试用例。对于每个测试程序,一些pointer pairs 使用 MustAlias 、MayAlias 或 NoAlias 进行注释。它们是指针分析任务的true label。我们研究提升和编译的 IR 代码是否可以支持 SVF 生成正确的指针分析结果。
Discriminability Analysis.
我们使用 ncc 论文中的默认设置将 POJ-104 数据集中的程序拆分为训练、验证和测试集。每个数据集都将被编译或提升为 LLVM IR 程序。所以,最后我们会分别创建5个train、 valid、 test set,对应五个被测试的lifter tools。
使用ncc 做分类任务,准确率越高,说明提供给ncc 的IR 质量越好。
C Decompilation.
将IR 代码丢给llvmir2hll 做反编译,根据反编译代码的质量评估IR的质量。
代码的结构性越好说明越可读,关于代码结构性的度量标准参考了别人的评估标准,选取了一个指标:统计 #goto 语句的数量,越少的 goto 语句说明可读性越好。
另一个指标是,函数平均代码长度LOC(lines of Code),基于朴素的理解代码越冗长可读性越差。由于McSema 中包含用于模拟机器指令的工具函数,这会增加IR 代码长度,所以我们计算每个用户定义的函数的平均 LOC,而不是整个二进制文件的反编译代码。
从SPEC INT 2006测试套件(共九个程序)收集C程序,排除了三个C++程序。
C. Changes Made on IR Lifters and Downstream Applications

上表是我们为了使数据集中的二进制文件可以正确的被处理所做出的人工努力,我们对几个lifter 和下游任务的ncc、llvmir2hll都做出了很多修改,才使得任务可以进行。具体修改参考。
0x6 Findings
A. Binary Lifting Results
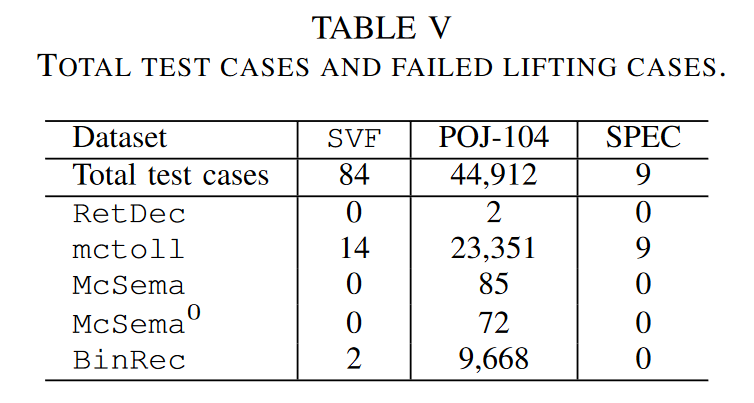
上表是上一小节中三个任务上的所有测试样例,和其中做lifting 失败的样例数量统计。
简单分析一下:
数据集:SVF和POJ数据集中的文件比较小,可以在几秒内完成lift,而SPEC中的二进制程序比较大需要数分钟至数小时才能完成。
Lifters:
- BinRec:速度远远慢于其他lifter,因为BinRec 使用符号执行探索程序路径。SVF中有两个程序是BinRec 无法分析的(异常退出), POJ数据集程序数量众多,我们设置超时时长为10mins,21.6%的程序没有分析完成,最终该数据集上的函数覆盖率是93%。这里分析速度较慢不能怪BinRec,因为我们在Sec5中说了不使用BinRec的 的RevGen技术,如果我们用上这个技术或者换成其他更好的符号执行引擎,是可以很快的完成分析的。在SPEC 上我们对每个用例执行了50h的分析,平均函数覆盖率是23%,这样的覆盖率阻碍了IR 反编译性能的评估,在Sec6-D详细描述。
- mctoll:在SVF数据集中,有7个不能分析,有7个生成了broken IR。SPEC数据集中的所有样本都不能分析。
- RetDec:总体来说取得了最好的可用性,不能分析的样本最少。
B. Pointer Analysis
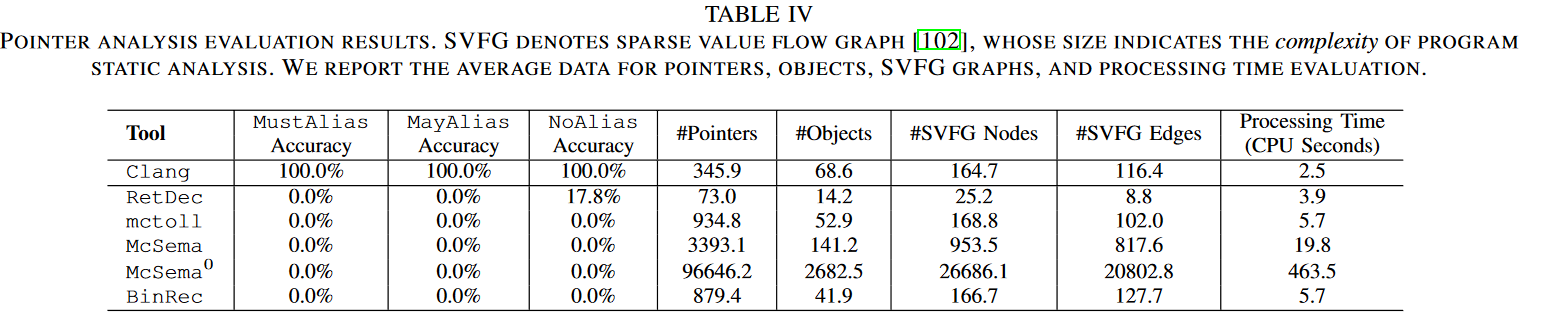
SVF数据集上对测试程序中pointer pairs 做了注释(MustAlias MayAlias NoAlias),测试lifted IR能否正确的恢复出这些注释。后面几列是SVF对各种IR做SVFG分析的时候产生的空间和时间消耗。
结论就是,所有lifter产生的IR都完蛋了,原因是这些IR很难正确的执行严格的静态分析。
只有RetDec完成了一点指针分析,我们来简单说一下。
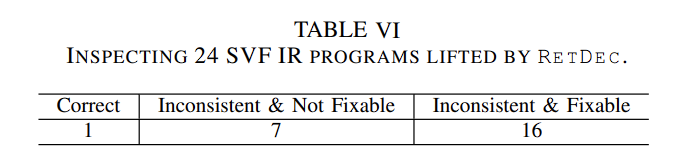
RetDec对SVF数据集中的24个程序的分析结果的人工检查,可以看到仅有1个分析正确,由16个虽然是不正确但是可以通过人工修复。以下是修复结果:
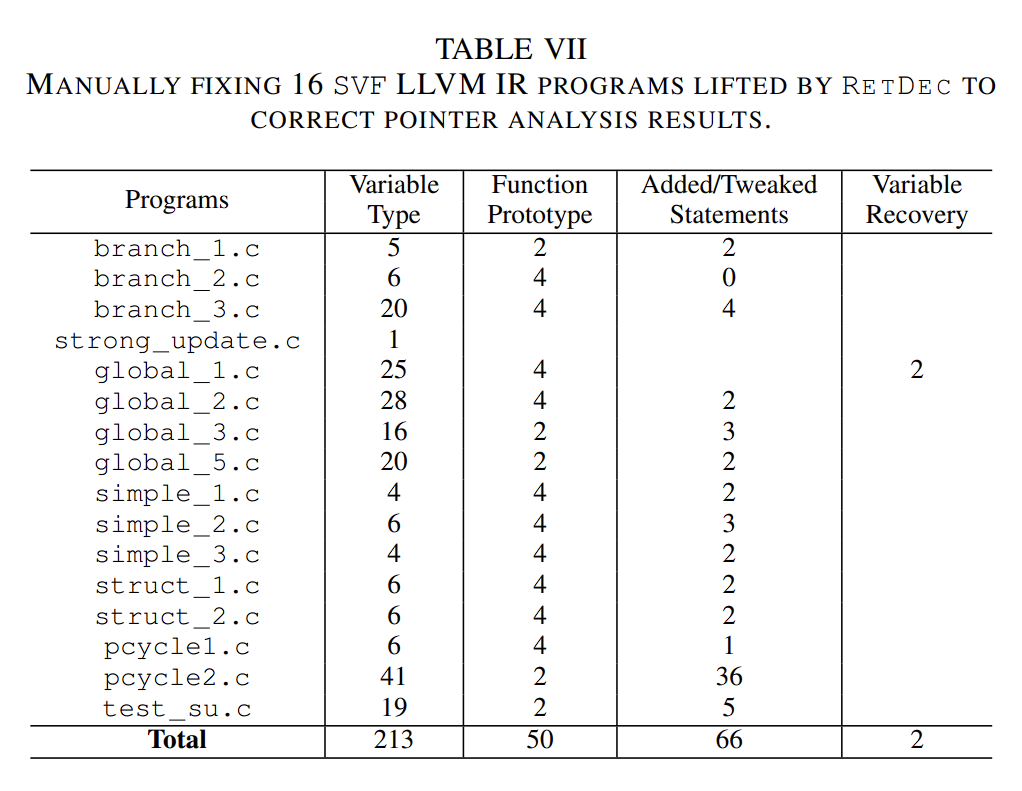
人工修复了16个SVF数据集中由RetDec提升得到的IR程序,用于修正指针分析结果。人工修正了213个不精确的变量类型,50个函数原型错误,新加入和调整了几个语句。完成对IR的人工修正后,最后实际上通过指针分析得到的变量恢复也就只有两个。。。
Lifted IR 难以用于严格的指针分析的原因总结为:
(1)类型恢复的困难,准确来说是难以区分指针类型和非指针类型。恢复复合数据类型比如结构体和数组,仍然是一个难题。
(2)函数类型恢复困难,准确来说,要使得lifted IR 和编译生成的IR 相似是很难的。
可能的改进方法:
- 我们进一步人工研究了lifters的源码,发现在评估中CIR和HIR的不一致性并不是主要来自于工具的bug。而是,这些lifter 没有完全实现本领域(指针分析)的研究成果。现存研究所提出的进行变量恢复和类型推断的静态分析技术,例如VSA。函数原型推断也可以使用相似的方法或者使用AI技术。
- 而且,我们也注意到McSema 使用商业工具IDApro作为它的逆向前端,它目前只是使用IDApro获取函数边界,我们建议McSema利用IDApro的函数原型信息。
总的来说,我们lifters 开发人员更多的采用学术研究成果,或者尽可能发掘其使用的第三方工具的全部潜力。
C. Discriminability Analysis
在POJ-104 生成的各种IR数据集上,使用ncc 做分类任务。
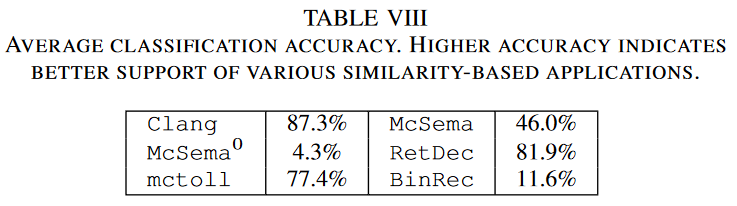
POJ上平均分类准确率,准确率越高说明lifter 生成的IR 越好,越利于各种基于相似度的任务。
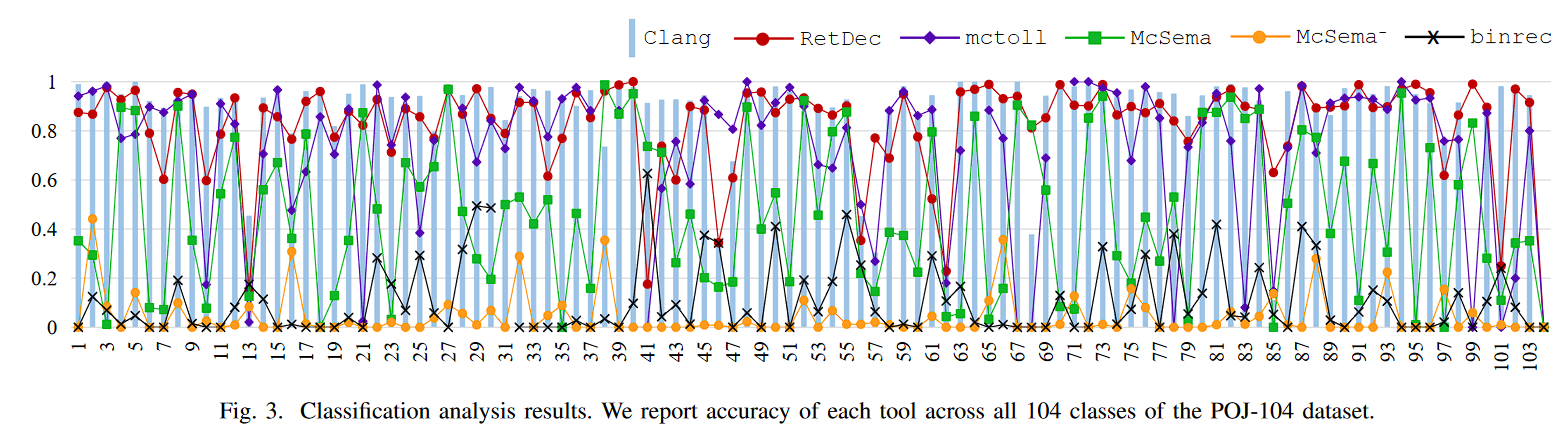
不同类别而上各个lifter 生成的IR 的表现。RetDec 在某些类别上甚至好于Clang
总结:RetDec 和mctoll 展现了很不错的在Discriminability Analysis 上的性能,我们还做了binary-diffing tasks,其结果和这里一致,放在论文的附录中。
这里的结果虽然不能说是非常精确,但是至少能给研究者在使用binary lifter上提供一些选择的参考,尤其是在做相似度任务的时候,例如code patch search。
原文这里还分析了有效性威胁,关于DNN-based Discriminability Analysis的潜在偏差。
D. Decompilation Analysis
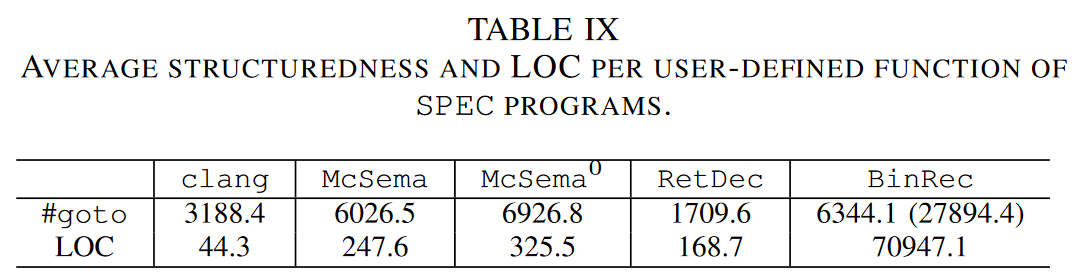
可见clang 和retdec 得到的IR通过llvmir2hll 得到的类源码的可读性最好。
总结:RetDec恢复的紧凑IR 代码在很大程度上提高了反编译C代码的结构性和可读性。
E. Functionality Correctness of Lifted IR Programs
所谓Functionality Correctness我们的测试方法是重编译IR代码,看编译的二进制文件是否能完成正确执行。
这里SVF数据集中的程序相对简单没有输出,所以我们只采用POJ和SPEC中的程序作为功能正确性的测试。
对于POJ 中的104个任务,我们人工阅读源码,来构造输入,我们最终确定了86个程序的输入输出。
对于九个SPEC 程序,我们使用脚本进行测试。
结果如下:
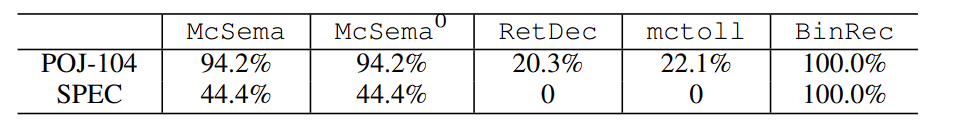
在BinRec的论文中,作者用SPEC做了函数功能正确性的测试,所以我们直接根据作者的建议正确配置了 符号执行引擎去提升POJ测试用例,结果是全都成功了。
此外本文还对跨平台和跨编译选项做了进一步研究。
0x7 Cross-Platform Evaluation
本节对lifters在ARM架构上的表现。RetDec和McSema支持64bit ARM架构。
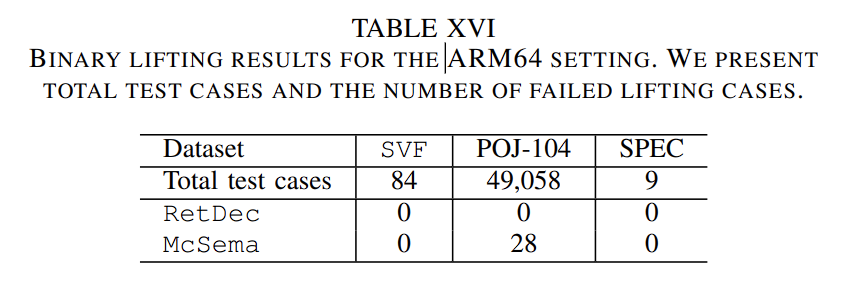
可见只有McSema有1%的失败,其他都lifting 成功了。
测试结果:

指针分析的结果比x86平台还差一些,
discriminability分析的准确率和x86平台差不多,
C反编译任务上,RetDec和x86平台稍好一些;McSema在LOC上和x86平台持平,在goto语句数量上比x86平台高很多。
对于功能正确性来说,这两个lifter 在ARM 平台上的表现都很差。
0x8. CROSS-COMPILER & OPTIMIZATION EVALUATION
跨编译器和优化选项,之前的实验都是使用不带任何优化的clang编译的,我们使用gcc(7.5.0版),和完整的编译器优化(-O3)进行实验。关于lifting 成功和失败的样本情况,在附录中给出,总的来说就是和TABLE V一致。
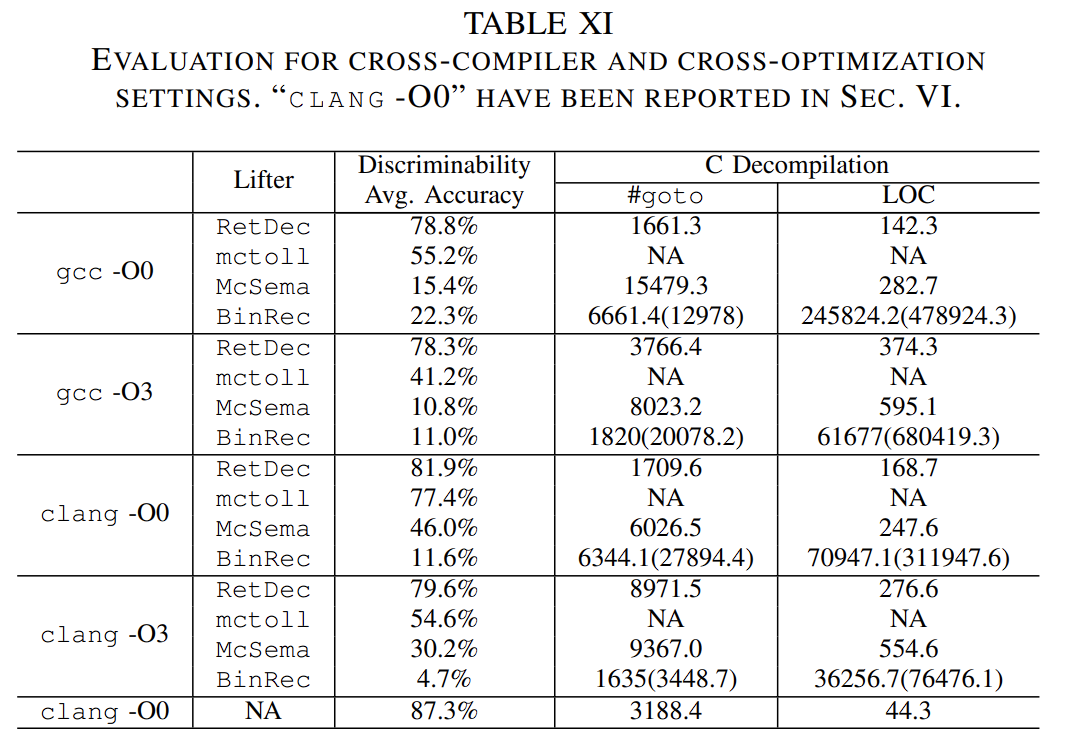
本组实验中McSema0给出了非常差的结构,所以这里就不展示McSema0了。NA是因为mctoll lifted IR 没能成功完成反编译。BinRec 中的括号内是函数全覆盖的数值(应该是BinRec 动态分析太慢,没有完成所有函数的覆盖就人工停掉了)。
0x9 COMPARISON WITH BINARY-ONLY TOOLS
原文附录ABC做了三个实验探讨纯binary tools 和lifter 在三个分析任务上的优劣。
-
Appx. A RetDec、McSema和RetroWrite 在 Address sanitizer(Asan)(地址错误检查) 任务。
原理上来讲,RetroWrite没有像lifters一样努力恢复变量,特别是RetDec虽然不精确但是可以恢复变量和函数的局部栈空间。这从概念上将RetroWrite于lifters 区分开来,鉴于它只能粗粒度的栈帧级的Asan insertion。
从经验上来讲,我们通过在Juliet 测试数据集上插入Asan 检查来评估三个工具。由于RetDec生成的IR 在功能正确性上就有严重缺失,所以对其lifted IR 做异常检测任务评估是没有意义的。McSema正确提升了2,187个用例,在这些用例上,其表现和RetroWrite相当。
关于更多两者之间的优点和缺点的分析,见附录A。
-
Appx. B 比较RetDec 与 DeepBinDiff、BinDiff 在binary diffing 任务。
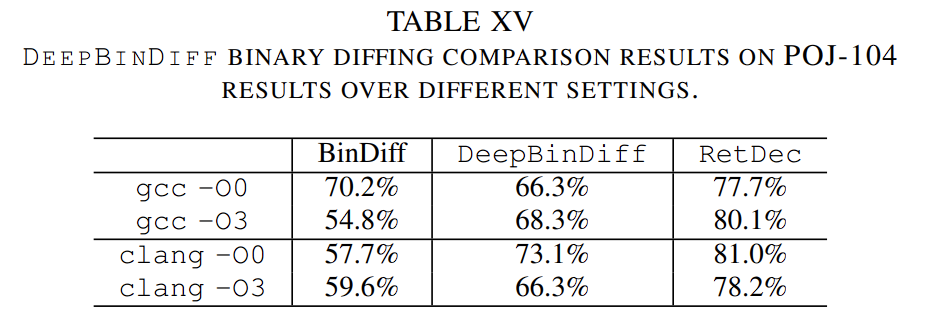
RetDec 和纯binary的两个工具具有相似的性能,这说明了lifters在恶意软件聚类和CVE/补丁搜索上具有良好的潜力。
-
Appx. C 比较lifters 和 IDAPro、Ghidra 在C 反编译任务。
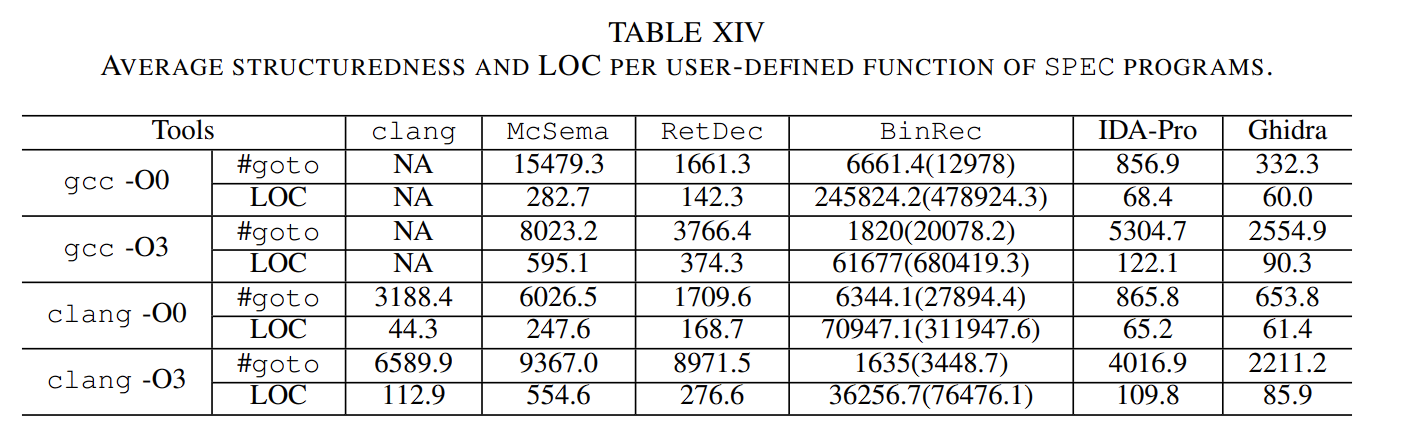
多数情况下IDA能生成结构性更好的代码,但是lifters 也表相出相当不错的反编译质量,并且他们都是免费的。XD
0x10 总结
根据你想做的任务选择你的英雄。
