Structural Attack against Graph Based Android Malware Detection
主要解决什么问题
目前有很多基于函数调用图FCG的恶意软件检测方法,本文提出一种结构攻击方法,攻击基于图的Android恶意软件检测器. 解决了feature space和problem space之间的逆变换问题[1].
这里写一下我对这两个空间和两者之间变换的理解:
- 特征空间feature space:原始输入(比如image,pdf,software)通过特征映射函数得到的特征向量,也就是数值向量.
- 问题空间problem space:(不知道这样翻译是否准确)指原始输入.
- 两者之间的变换:从样本空间到特征向量空间的映射,和,从特征向量空间到样本空间的映射.
- 值得说明的是,从原始输入计算特征向量的这个映射函数,它往往不是双射的,比如从一个软件的函数调用图上生成特征向量的映射函数,任意给出一个向量大概率找不到对应的函数调用图. 这意味着一个特征空间的向量叠加上扰动以后,很可能没有对应的problem space中的样本. 这就使得Inverse Feature-Mapping Problem成了一个难题.
这篇文章[1]对上述概念进行了较为详细的阐述和形式化表达,如果想进一步深入了解,可以通过文末链接阅读原文. 文中Sec III对两个space上的攻击,space之间的变换,变换的难点,以及可能的解决的方法(在段落B.Inverse Feature-Mapping Problem)进行了形式化描述.
有趣的是,这篇文章Sec IV直接使用问题空间攻击,在Andorid恶意程序检测模型上进行攻击尝试.
回到本文,
设计了一个启发式优化模型与强化学习框架集成到一起,用于优化我们的结构攻击(HRAT:Heuristic optimization model integrated with Reinforcement learning framework structural ATtack). HRAT包括四种类型的攻击:插入和删除节点,增加边和改写,对应APP中的插入和删除方法,增加调用关系和改写.
通过对超过 30k Android 应用程序的广泛实验,HRAT在feature space(超过 90% 的攻击成功率)和problem space(多数情况下高达 100% 的攻击成功率)都展示了出色的攻击性能.
另外,需要阐述本文要解决的现有的对抗样本攻击方法的问题:
-
L1-system-specifc attack methods:现存的攻击方法多数高度依赖目标系统的特征提取方法,比如Android HIV实现了problem space attack on Mamadroid 通过修改某些样本特征,以扰动特征向量,所以如果目标系统更换特征提取方法,那需要重新设计problem space transformation(这里的变换指problem space中原始样本到对抗样本的变换). 本文structural attack 扰动图结构而不是特征向量,所以目标系统的特征提取方法对本文攻击工作流无影响.
(怎么会没有影响呢,那我要是不从函数调用图上提取特征了,你还能生成个球的对抗样本. 所以我觉得,在problem space的扰动,最终还是对特征向量的扰动,是不能绕靠目标系统更换特征提取方法这个问题的.)
-
L2-limited software modification operations:为了保持功能的一致性,现有的 App 修改方法仅限于插入死代码.
-
L3-inconsistent transformation relation:现存的对抗样本的生成方法以特征扰动到app modification为指导,尽管他们可以按照需要随意插入代码,但是为了一致性(或者说Plausibility)只能插入no-op code无动作代码. 而我们的攻击方法确保了修改图后仍能保持应用程序的一致性. (其实这条和上一条不是一个意思吗.
其实上述L3在[1]中段落Problem-Space Constraints也有提到,就是关于问题空间transformation生成对抗样本的约束条件.
challenges
- how to determine a operation type.
- how to select the most effective objects (nodes or edges) to modify.
为此设计了本文HRAT,原文Sec 3.3对上述问题的解决进行了描述.
总结:
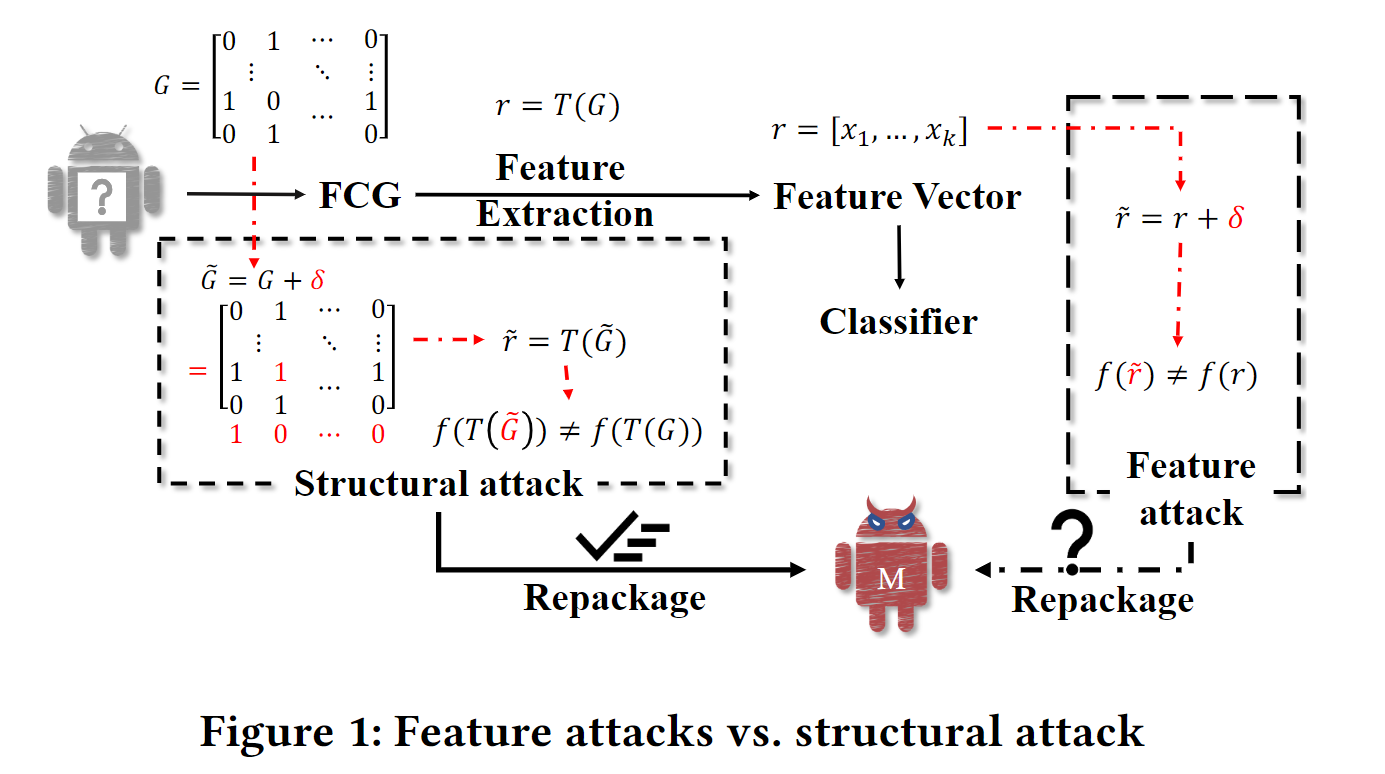
本文要解决的问题就是右下角的问号.
目标系统
默认大家都对下述Android恶意程序检测工作有基本的了解,这里就简要地提一下.
Malscan
从app和提取FCGs图,并使用图上敏感节点的中心作为特征. 所谓敏感节点就是能反应恶意软件性质的android敏感APIs.
Mamadroid
从FCG中抽取函数调用关系作为特征.
APIGraph
是一个提升Android Malware Detection的框架. 它增强了特征的表征能力,并利用Android的特性聚合具有相似语义的API. 也就是做API聚类,在特征提取过程中,使用一个代表性API表示一个cluster中的所有API.
攻击方法
威胁模型
目标系统攻击这来说是可访问的白盒. 也就是说,攻击者可以访问目标系统的数据集、特征空间和模型参数. 我们的攻击目标是在修改恶意应用程序的函数调用图以逃避目标系统的检测. .两种基于 FCG 的 AMD,即 Malscan (ASE 2019)和 Mamadroid (NDSS 2017),以及一种 Android Malware Detection 增强方法,即 APIGraph,用于评估我们攻击的有效性.
上述两种检测模型拥有很高的检测性能:98% detection accuracy for Malscan and 99% F1 score for Mamadroid.
攻击方法的形式化
攻击方法的输入是一个FCG(邻接矩阵),该方法会通过在邻接矩阵上加一个扰动矩阵δ的方式修改这个图:
就是对抗样本图. 使用表示恶意软件检测模型在模型参数θ下的检测结果,攻击目标是让模型将恶意样本错误分类为良性,形式化为:
在与原来的功能相同的情况下,我们设计了四种类型的修改动作,即添加边、重写、插入节点和删除节点,这也是考虑到了Apps的特点. 接下来,我们首先介绍了约束条件的定义,然后描述每个动作的定义和属性.
上文已经提到过四种修改了,这里对重写,删除这两种修改动作做个解释.
本文定义了Constraints,它列出了APP中methods的可修改性. 当HRAT修改FCGs中的节点和边时,需要遵循这个约束条件. HRAT只能修改modifiable methods和call relations. 我们通过Android,Flowdroid和soot的性质决定了以下不可行修改的约束:
- Framework APIs:framework API是在Android系统而不是应用程序中定义和实现的,因此它们是不可修改的.
- Lifecycle methods:生命周期方法有Android系统调用,如果我们删除或增加这样的函数调用则容易使APP崩溃.
- Flowdroid methods:因为Flowdroid引入了额外的methods便于分析APPs,FCGs也会包含这些方法.
说回重写这个修改动作:
将三个不在约束条件中的node: 将开始节点和结束节点之间的边删除,增加从开始节点到中间节点的边,增加从中间节点到结束节点之间的边.
另外,删除动作:
删除一个不在约束中的节点并连接被删除节点的caller和callee.
启发式优化基于结构攻击的强化学习
结构化攻击过程有一系列针对图的攻击动作组成. 具体来说,每次攻击动作由两个阶段:决定一个攻击类型和选择一个攻击对象. 前者决定动作类型的问题(adding edge, rewriting, inserting/deleting node),后者决定那条边或者节点要被修改.
我们的优化目标是得到尽可能小的图上的修改序列,而不是某种隐藏的结构,所以这里选择交互式的学习算法—强化学习模型. 这里的隐藏结构就是说,该目标不是传统的在数据集上找某种隐藏的扰动结构可以使得模型出错,而是生成一个某种约束下的改动序列.
state space
状态空间存储所有攻击过程中出现的中间状态. HRAT选择从中间图上抽取出的特征向量进行存储. 例如,当HRAT攻击Malscan模型时,状态空间存储所有过程中产生的centrality features of sensitive APIs. 特征向量的长度固定,适合训练策略网络. 我们不使用邻接矩阵,因为如何动态地处理图形尺度的变化超出了本文的范围.
此外,HRAT只存储上一次修改后的图(邻接矩阵的形式),这有利于下一次在图上的修改. 我们每次修改只基于当前的图和状态,存储历史图结构是浪费内存.
Policy Model
策略模型确定攻击行为,包括决定行为类型和选择攻击目标. HRAT基于强化学习,具体来说是deep Q-learning来确定攻击行为.
文中对deep Q-learning用于structural attack的算法有详细描述,这里就不展开,我们避免陷入过于细节的地方而失去了对文章整体的把握.
Action Space
action space存储了修改图的操作,每个操作表示为一个四元组:{动作类型,对象*3}.
Reward Function
- 反馈函数评估所选的动作的在当前状态上的效果.
因为目标是让通过尽可能小的修改使得系统分类出错,所以反馈函数定义为:
代表当前修改后的graph和原始的graph中间在node数量和edge数量上的差别.
- 反馈函数评估所选的攻击动作类型和攻击对象
- adding edge的反馈是-1,因为无论梯度搜索选择了哪一个边,只有一个边被修改了.
- rewriting 和inserting node的反馈是-3和-2.
- removing node删除一个节点并连接被删除节点的caller和callee,其反馈是:1+该节点caller的数量*该节点callee的数量.
结构化攻击的优点和有效性
Structural attacks bridge the gap between feature-space attacks, which only perturb feature vectors to deceive the classifier, and problem-space attacks, which generate adversarial objects.
也就是[1]中提到的inverse feature-mapping problem. 现存的问题空间的攻击受限于inverse feature-mapping problem(即,优化feature-space attacks 不能被很好的映射到problem-space attacks) 我们的Structural attacks基于App的FCG修改nodes and edges,因此,四个FCG修改动作对应了App上的修改.
暗涵,我们的攻击也涉及到了向量空间,毕竟还是将向量送给目标模型,而且我们也在problem space上找到了对应修改,所以我们就能说我们弥补了feature-space attacks和problem-space attacks之间的鸿沟.
Android Application Manipulation
阐述本文开发的基于graph modification自动生成App Manipulation的工具(APPMOD). 遵循以下两个原则:
- a) Functional Consistency:APP的功能在修改前后保持一致
- b) Valid Modifications:插入的代码不会被静态分析移除. 具体来说静态分析会删除永远不会执行的dead code.
HRAT的原型(即APPMOD)构建在soot上. APPMOD使用soot修改Apps,soot将会在无源码的情况下翻译android字节码到中间表示. 根据方法签名APPMOD将会定位到App中的方法并进行修改.
方法签名示例:<packageName.className returnType methodName(paraList)>
APPMOD的工作流如下图所示.
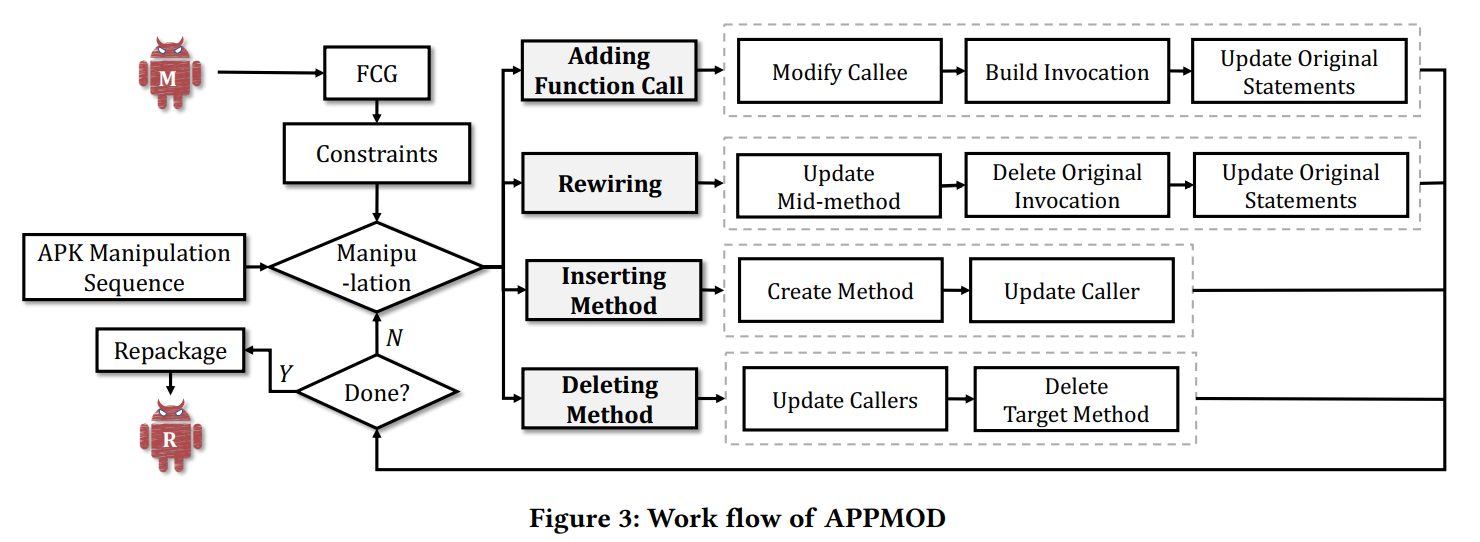
原文中也对App修改的具体方法进行了详细介绍Sec4.2-4.5,这里也不展开了.
结果评估
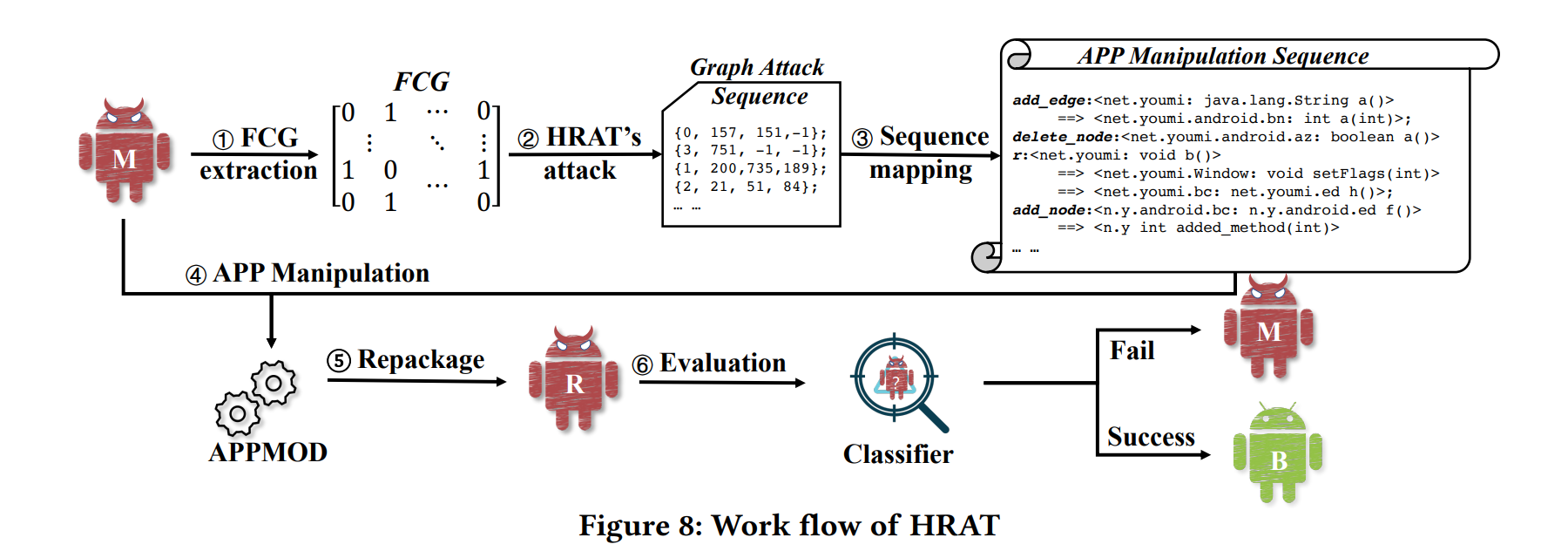
本文主要工作,HRAT的完整工作流如上图所示.
① 抽取FCG
② 生成一个graph modification sequence(GMS)这个序列中每一项都表示一个对node或edge的扰动
③ 将GMS转换到实际App上的Manipulation
④ App依照GMS进行逐项修改
⑤ 最后我们评估生产的重打包的App是否能避免被目标系统检测出来
⑥ 下面通过回答以下五个问题评估HRAT的表现
- RQ1: Effectiveness analysis. How effective is HRAT against the state-of-the-art AMD techniques?
- RQ2: Modification efficiency comparisons. Compared with other attack methods, how is the modification efficiency of HRAT?
- RQ3: Effectiveness of IMA. How effective is individual modification action (IMA)?
- RQ4: Resilience to code obfuscation. How is the resilience of HRAT to malware with different obfuscation techniques?
- RQ5: Functional consistency assessment. Do the adversarial app generated by HRAT preserve the functionality as the original one?
Dataset
使用11,613 benign Apps and 11,583 malicious Apps from 2011 to 2018 in Malscan 评估HRAT(for RQ1-3&5). 所有App都来自AndroidZoo,并且每个样本都经过多个反病毒引擎测试才决定了其标签. 对于RQ4&5,我们使用了一个先前工作中构建的数据集,来评估HRAT的有效性. 这个数据集包含不同家族的恶意软件,其中6586个经过变量重命名混淆,1090个通过字符串加密混淆,1172包含反射.
Metrics
为了评估feature-space 和 problem-space的攻击的有效性,本文设计了三种attack success rates(ASRs):
- Initialization ASR:N是恶意样本总数,Ng是改变了FCG并成功避免系统识别的样本数量,且一个样本最多500个修改,这里的门限值回答了RQ2,我们发现几乎100%的样本在500次以内的修改就可以逃避检测. 需要注意,由于anti-repackage protection的存在,并不是所有FCGs上的修改都可以被重打包. (这其实可以看作feature-space attack)
- Relative ASR:反应了成功重打包的比例. Np为,在Ng中成功重打包的比例. (也就是feature-space attack能inverse mapping 到problem-space的比例)
- Absolute ASR:反映了HRAT在problem space上的有效性,即是否重打包的样本可以逃避检测并且保持功能性. Ns是Np中成功避免检测的样本数量. (就是problem-space attack成功率)
实验结果
本文设计了以下三个数据集做HRAT的有效性分析:
- 第一个数据集中,训练集(TRo) 和测试集(TEo)是在同一时间段被收集的.
- 第二个数据集中,测试集(TE1 and TE2)是在训练集之后被收集的. 这个数据集模拟了使用已知样本训练检测器并使用它检测未知恶意样本的实际使用情形.
- 第三个数据集使用最新的恶意软件(TR2)训练分类器使用旧的恶意软件(TE1)做测试.
结果如下图所示:
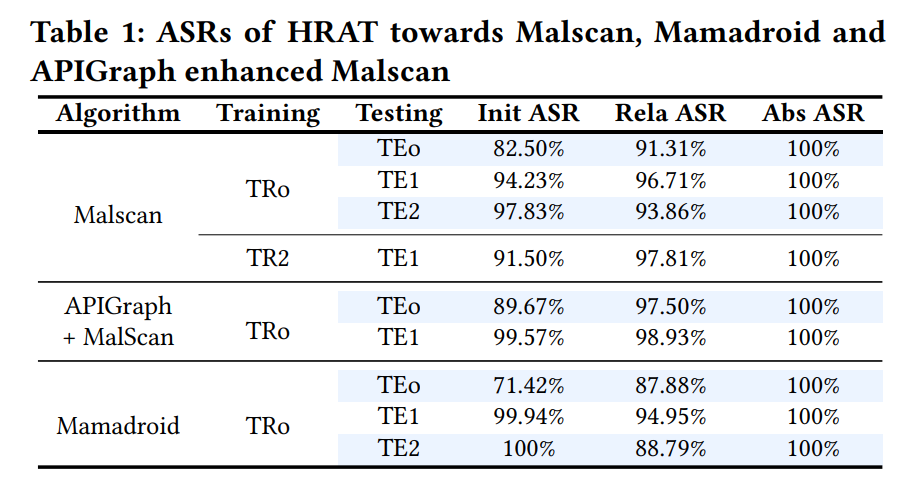
使用不同算法的攻击成功率如下图所示(using TRo for training and TE1 for testing):
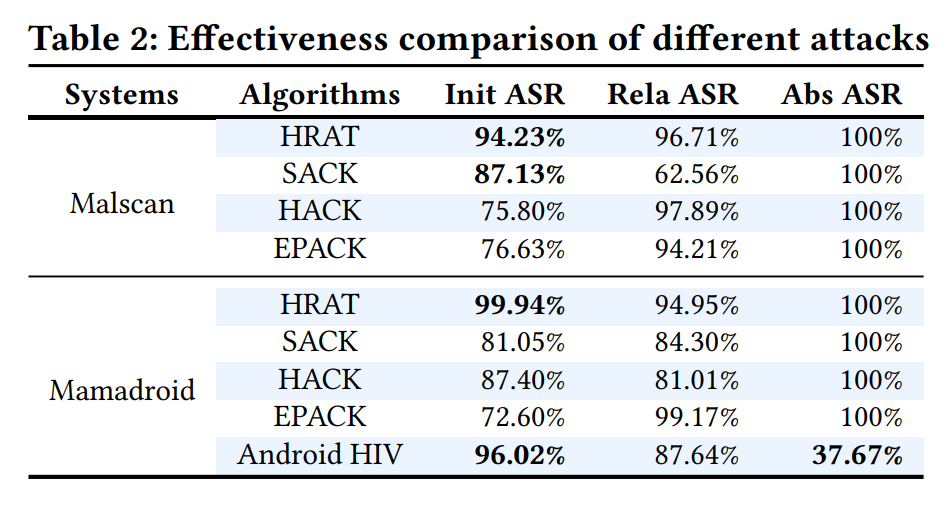
使用SACK,HACK和EPACK的Init_ASR比强化学习低,因为evolutionary algorithms 把结构攻击引导向,随机地选择攻击行为. 受益于结构攻击,基于演化的算法实现了和强化学习相同的Abs ASR.
关于这几种算法可以查看原文附录,SACK: simulated annealing based structural attack,HACK: hill-climbing based structural attack,EPACK: evolutionary programming based structural attack.
总结:
Answer to RQ1: HRAT实现了在500次修改内高达99.94%的攻击成功率. 如果不做严格的修改次数限制HRAT可以达到100%的problem-space attack成功率.
再来看一下HRAT的修改效率:
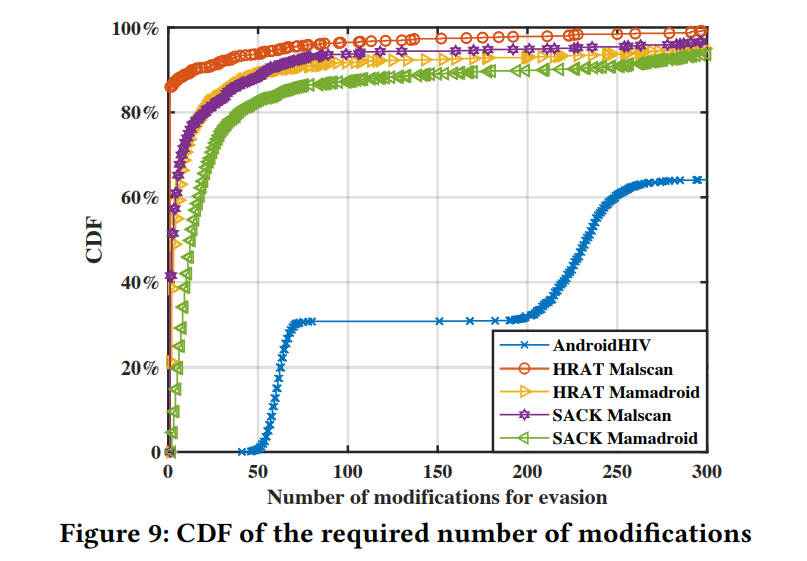
CDF:cumulative distribution of the required number of modifications for evasion 就是需要修改的最少次数能避免被检测的样本累计统计.
看图可知HRAT是几种算法中效率最好的,因为多数样本在100次修改就可以完成欺骗.
Answer to RQ2: HRAT需要的骗过检测器的App修改次数少于其他算法.
文章对其他几个进行了一一解答,这里我们已经看到这篇文章的创新点和实验效果,就不在展开更多实验内容了.
对我有什么启发(总结)
[1]才是这个任务的上游玩家,这篇就文章有点…
不过本文也是做了不少实验,能把强化学习应用到inverse feature-space mapping这个问题上算是比较有趣的工作,但是文章读下来感觉不够简洁,没能把细节清晰明了的展现给读者,当然也可能是我能力不够XD.
另外,这篇文章的作者(们)还写过一篇BinarizedAttack: Structural Poisoning Attacks to Graph-based Anomaly Detection[2],发表在ICDE 2022数据库顶会,这篇文章是对基于图的异常检测模型进行结构化投毒攻击,主要讲对图结构进行修改达到让模型分类出错的问题,给我的感觉作者应该是先做了BinarizedAttack这篇文章,然后才是本文. 然而,本文发表于CCS 2021,至于前者是否是二投我也没问作者,这不太重要. 总而言之,这两篇文章都是对图模型的攻击,虽然关注点不太一样,但不失为很好的参考对象.
参考文章: