ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
摘要
MLM任务的预训练模型比如BERT,通常需要大量计算才能达到比较好的效果. 本文提出一个简单却更有效的训练任务replaced token detection. 该任务不是MLM那种mask输入中的一个token,而是使用一个小型生成网络生成一些 plausible alternatives(看似可以合理替代的)token去替换输入中的一些token,训练判别模型去判断输入中的每个token是否被替换过. 通过全面的实验我们发现这个训练任务优于MLM任务,因为此任务定义在所有input token上,而不是只关注输入的一个子集. 实验结果表示,我们的任务在模型大小,数据量和计算量上都显著优于MLM. 尤其对于小模型的提升更加明显. 例如,在GLUE这个自然语言理解benchmark上,我们用单GPU训练了4天的模型优于GPT(计算量超过我们30倍). 我们的方法在大规模上也表现很好,在与RoBERTa和XLNet两个大规模模型表现相同的情况下,我们的模型训练的计算量比他们少四分之一,相同计算量的情况下,我们的模型比他们更加优秀.
主要解决什么问题
作者想证明:基于上述判别任务的训练方法比现存的生成任务的训练方法,在计算效率,模型参数效率上更优秀.
使用的方法
上文中我们描述的替换token检测的预训练任务,如下图:
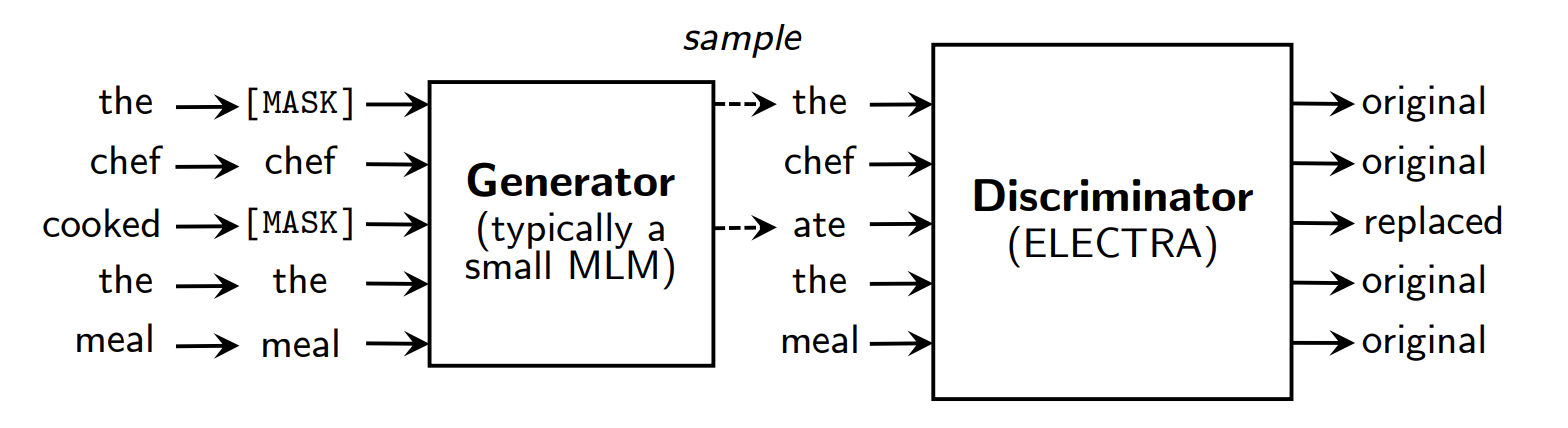
图2:An overview of replaced token detection. 生成器是可以生成覆盖词汇表中token的任意模型(典型是MLM任务训出来的模型),我们通常使用与鉴别器联合训练的小型masked language模型. 尽管上述架构看起来像是GAN,我们寻来你生成器使用最大似然法而不是adversarially,因为把GAN用于文本是比较困难的. 完成预训练后,我们在下游任务中扔掉生成器只微调鉴别器.
本文方法训练两个神经网络,生成器G和鉴别器D,两者都包含一个encoder (eg. a Transformer network),该encoder将一个输入序列映射到一个上下文化(contextualiized 或者说语境化?)的向量序列表示.
对于一个给定的位置t(在本文中t只取被mask的位置),生成器输出生成一个特定token 的概率,这一步是通过以下softmax layer(也就是说G会计算它认为masked位置t最有可能的词汇的概率,这个词汇就是):
e表示token embedding函数,表示生成器的encoder. 上式分子是行向量乘一个列向量,其实这里没太想明白:一个token的embedding 内积 序列通过G的encoder得到的向量h(表示一个token),比上,序列中每个token的embedding 内积 序列通过G的encoder得到的向量h 的和,这是啥概率?
对于特定位置t,鉴别器输出 是”original“还是”replaced“,这一步通过以下sigmoid output layer:
这里的应该是sigmoid output layer前一层网络的输出.
随机选出k个位置用[mask]替换这些位置上的token,构成,这就是G的输入. 然后,生成器学习预masked token的原值.
将G生成的token替换就得到了,这就是D的输入. 鉴别器经过训练,可以在区分输入序列中token似乎否被替换过.
总结,G和D的输入形式化为:
ps:Typically k = ⌈0.15n⌉, i.e., 15% of the tokens are masked out.
尽管这个架构很像GAN,但是这里有几点关键不同:
- 如果生成器恰好生成了一个正确的token比如上图所示的the,则这个token在鉴别器这里应该考虑为”original”而不是”replaced“. 我们发现这种做法可以一定程度地改善下游任务的结果.
- 生成器通过最大似然训练而不是通过adversarially训练,以骗过鉴别器.
- Adversally训练生成器是困难的,因为不可能通过生成器的取样反向传播(文本取样为离散值)
- 虽然我们尝试通过强化学习(reinforcement learning)绕过这个问题,但是这样做表现很差.
- 我们没有给生成器一个噪声向量作为输入,而这在GAN中是典型做法.
D,G的loss和最小化的总loss:
训练在一个大raw text语料库X上. 我们用一个简单的样本来近似估计损失中的期望值. 我们因为sampling这步不能做反向传播,完成预训练之后,丢掉G,在下游任务上fine-tune G.
本文对方法的描述比较简单精炼,如果觉得这里的翻译和理解不准确,可以翻看原文,文末有链接.
结果评估
ELECTERA和BERT的参数量基本相同,大多数实验的预训练数据和BERT保持相同,使用3.3 Billion tokens from Wikipedia and BooksCorpus (Zhu et al., 2015). 在以下任务上做了评估:
- General Language Understanding Evaluation (GLUE) benchmark (Wang et al., 2019)
- Stanford Question Answering (SQuAD) dataset (Rajpurkar et al., 2016)
另外还设计了几个扩展模型来改进本文方法,除非另有说明否则使用的参数量和数据集都和基本模型一致. 其中,ELECTERA-large上使用了33Billion data from ClueWeb (Callan et al., 2009), CommonCrawl, and Gigaword (Parker et al., 2011). 都是英文数据集.
SIZE
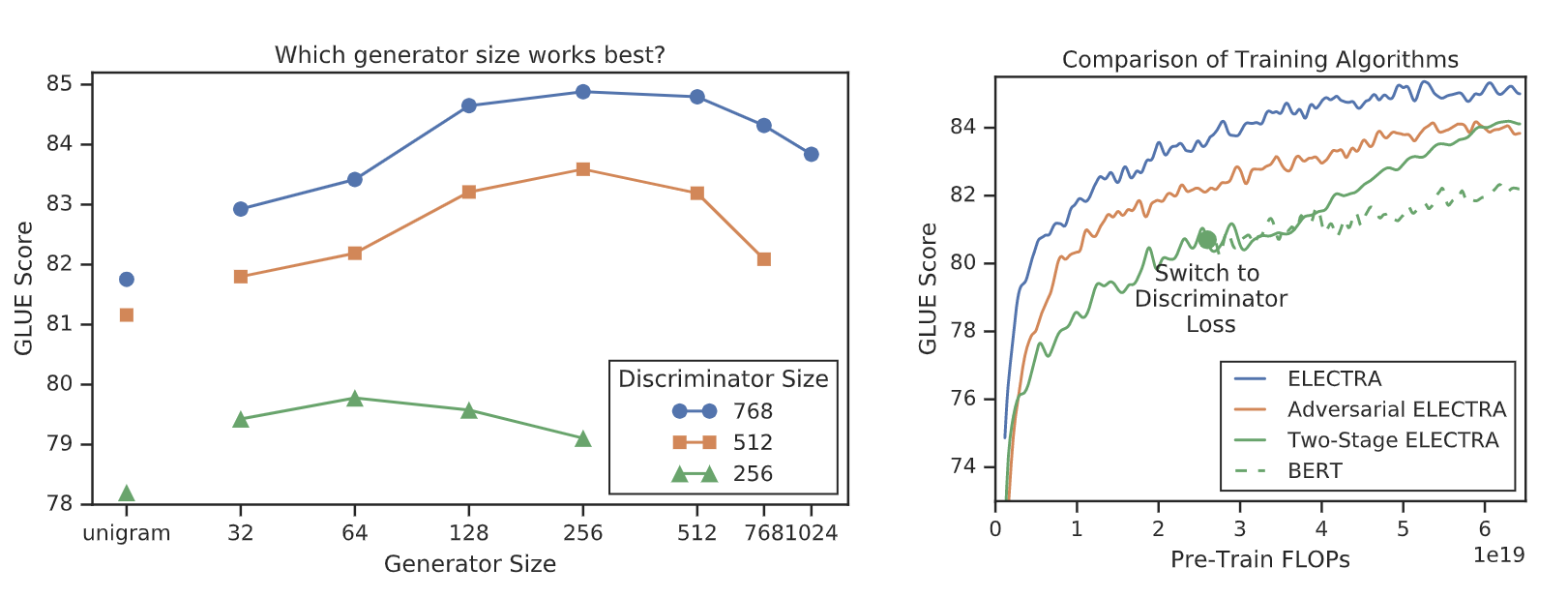
图3:左,GLUE任务得分对于不同尺寸的生成器和鉴别器的情况. 有趣的是,生成器比鉴别器小时结果比较好. 右,比较不同的训练算法的效率. 注意这里使用的是FLOPs而不是训练步骤,由于ELECTERA还有生成器,所以相同FLOPs的训练步骤比BERT少.
上图中two-stage ELECTRA:
- Train only the generator with for n steps.
- Initialize the weights of the discriminator with the weights of the generator. Then train the discriminator with for n steps, keeping the generator’s weights frozen
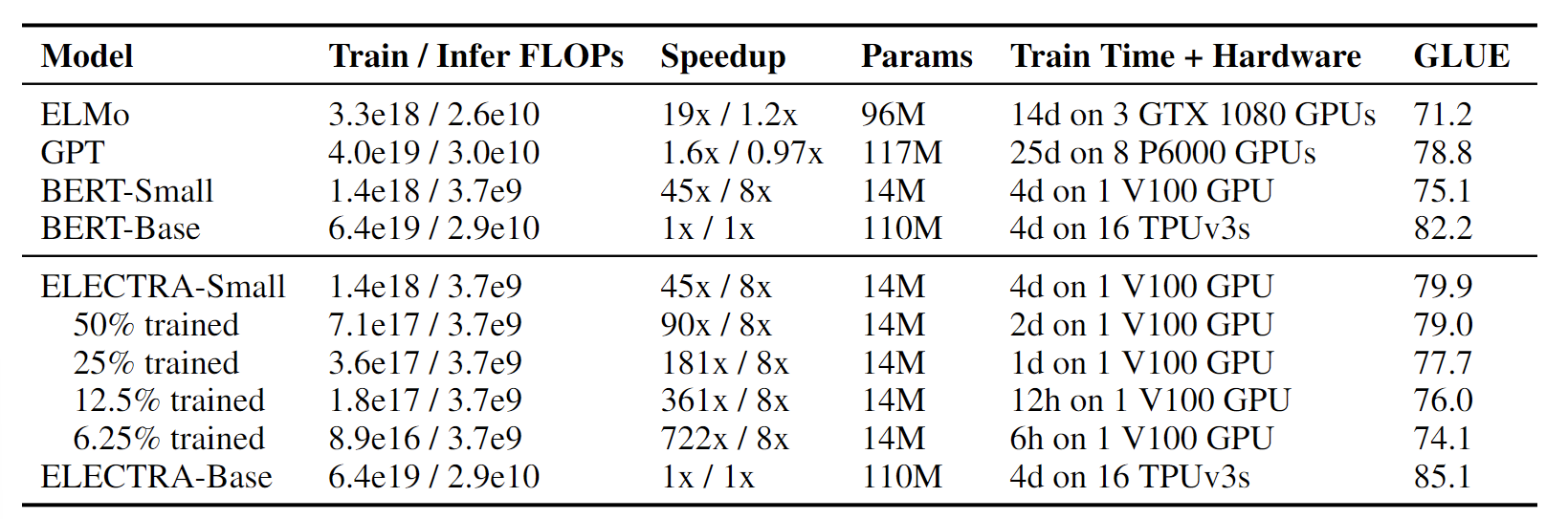
表1:在GLUE任务dev 数据集上比较小模型. BERT-Small/Base 是我们实现的和ELECTERA-Small/Base 相同参数量的模型. Infer FLOPs 是假定单个输入长度128. 训练时间应该谨慎对待,因为它们是针对不同的硬盘和未优化的代码. 即使在单GPU上训练,ELECTRA也表现良好. 在GLUE任务上比同类的BERT模型高出5%,甚至超过了更大的GPT模型.
SMALL MODELS
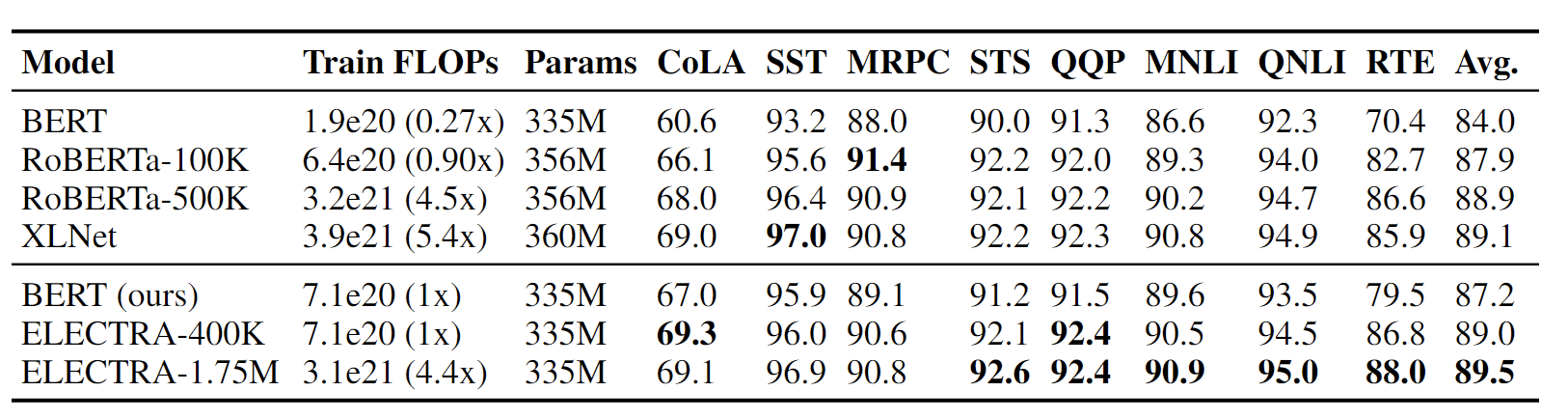
表2:大模型在GLUE dev set数据集上的表现. ELECTRA和RoBERTa在不同的预训练步骤下的情况,-后面表示训练步数. ELECTRA在使用少于1/4的预训练计算量时,与XLNet和RoBERTa的表现相当. 而在给定类似的预训练计算量时,表现优于它们。BERT dev的结果是来自Clark et al. (2019).
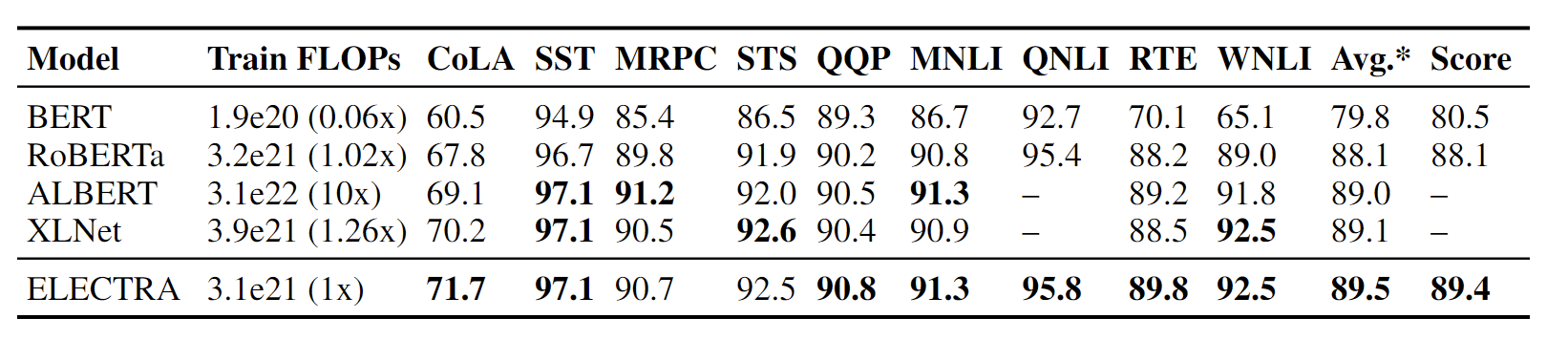
表3:GLUE test-set results for large models. 本表中的模型采用了额外的技巧诸如ensemble来提高分数(详见附录B). 有些模型没有QNLI得分,因为它们将QNLI作为一项排名任务,而最近GLUE基准不允许这样做. 为了与这些模型进行比较,我们报告了不包括QNLI的平均分数(Avg.*),以及GLUE排行榜上的分数(Score). "ELECTRA "和 "RoBERTa "是指 完全训练的ELECTRA-1.75M和RoBERTa-500K模型.
LARGE MODELS
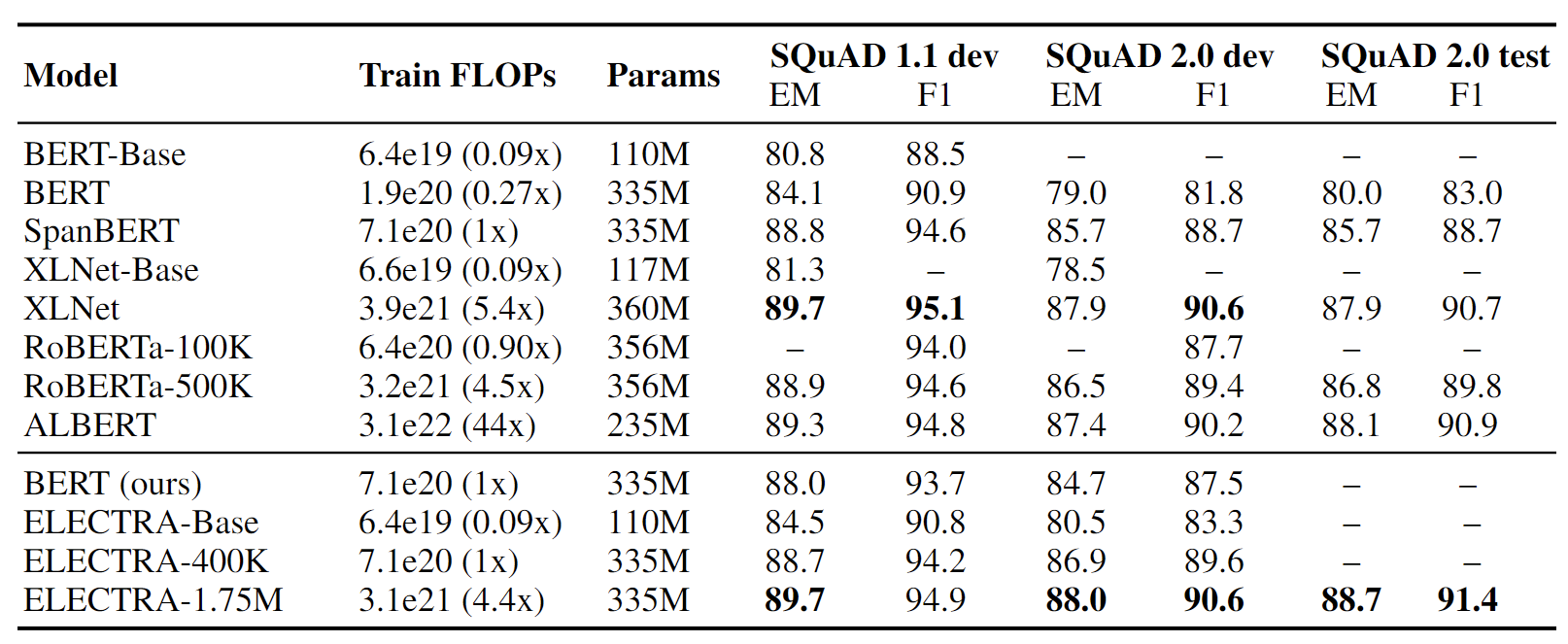
表4:Results on the SQuAD for non-ensemble models
EFFICIENCY ANALYSIS
本文的初始想法是MLM任务训练只将一小部分数据集作为目标会导致训练效率低下,但是事实并非如此,毕竟即使之预测一部分token,模型也输入了一个sample所有的token,为了更好的知道这件事到底造成了多大的影响或者说瓶颈,我们在ELECTRA和BERT之间的差别设置了一系列实验:
- ELECTRA 15%:这个模型与ELECTRA相同,只是判别器的损失只来自于输入中被mask的15%的token. 换句话说,鉴别器的loss综合从1-n变成了1-k.
- Replace MLM:这一目标与Mask Language Model相同,只是没有用[MASK]代替被盖住的token,这些被盖住的token直接替换为generator生成的token. 也就是说生成器不会看到[mask]标记而是直接根据一条完整的sample预测特定位置可能出现的token. 这一目标测试了ELECTRA的收益在多大程度上来自于,解决在预训练期间将模型暴露于[MASK]标记的差异.
- All-Tokens MLM:和Replace MLM很想,被mask的token被替换为生成器的sample. 此外,该生成器还预测了输入中所有的token,而不仅仅是那些 被mask掉的.
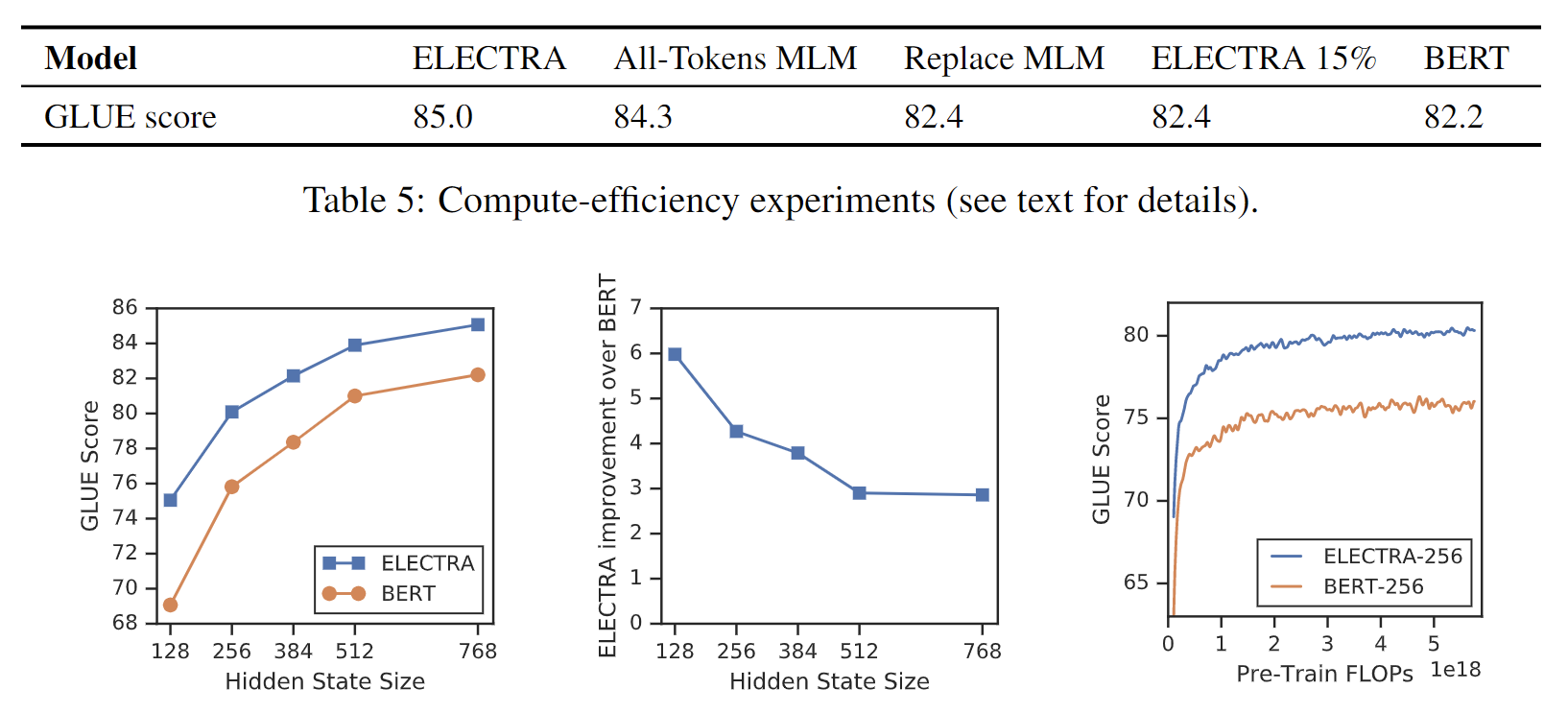
图4:左边和中间,比较BERT和ELECTRA对不同的模型尺寸. 右边,Small ELECTRA 模型比BERT收敛到更高的下游任务准确率,表明改进不仅仅来自更快的训练.
首先,我们发现ELECTRA极大地受益于对所有输入标记定义的损失,而不仅仅是一个子集. ELECTRA 15%的表现比ELECTRA差很多.
第二,我们发现BERT的性能受到轻微损害,原因是预训练和微调的[MASK] token 不匹配,因为 Replace MLM 稍微优于 BERT. 我们注意到,BERT(包括我们的实现)已经包括了一个帮助解决预训练/微调差异的技巧:被mask的token在10%的时间里被替换成随机token,在10%的时间里保持不变. 然而,我们的结果表明,这些简单的启发式方法不足以完全解决这个问题.
最后,我们发现All-Tokens MLM,这个生成模型对所有token而不是子集进行预测,而不是一个子集,缩小了BERT和ELECTRA之间的大部分差距.
总的来说,这些结果表明,ELECTRA的很大一部分改进可归因于从所有token中学习,还有一小部分归功于缓解了预训练和微调阶段的不匹配问题.
对我有什么启发
启发就是以后可以用这种结构,水一下二进制任务. 😁
参考文章:
- source code https://github.com/google-research/electra