Neural reverse engineering of stripped binaries using augmented control flow graphs
0x1 INTRODUCTION
从二进制代码出发,遍历CFG从Entry到Sink(就是一个目标call site)的所有path,利用pointer-aware slice技术重构汇编码形式的API call,重构为有一定可读性的类似高级语言的形式( eg: connect(RET, ARG, 16) ).
然后通过学习,如何学习,将函数名embedding,参数的抽象表达也做embedding. (如何学习到embedding不知道,没看懂)
最后,将一个procedure表示为从Entry到Sink的路径集,将这个路径集送入LSTM/Transformer-based seq2seq model 还有GNN网络训练,label是procedure对应的函数名.
0x2 overview
整体介绍了一下本文的思路,但是读完容易不知所云,所以建议读完文章,再回来读一遍原文这一节.
每个augmented call site 作为一个node,将程序表示为graph,从起始结点开始每条path都表示一个可能的运行时执行顺序.
两种训练函数名预测的方式:
- 基于这些graph应用GNN模型做encoder,用LSTM decoder输出边长序列(函数名);
- 从graph上生成path,喂给LSTM-based、Transformer-based model.
关键点:
- 使用静态分析,重构API call sites
- 使用pointer-aware slices技术Sec4,使用具体值或者抽象值,替换调用点参数
- 二进制程序切片是创建一个变量必要的程序片段,本文中从CFG上取path切slices
- 参数变量替换为具体值或者抽象值,抽象值包括:argument=ARG,global value=GLOBAL,value from calling a procedur=RET,value on stack=STK
- 这一步提供了relative improvement 20%
- 通过分析CFG,可从call sites的近似运行时的顺序中,获知增强的call sites. Sec2
- 增强的call sites 能有效的表示二进制过程
- 运用了大量的神经网络技术
0x3 model 的介绍就不写了.
0x4 Representation Binary Procedures
Reconstruct call site
重构三种调用点的方法
- 内部调用,elf内部的固定位置的过程调用
- stripped binary 去除了符号表,所以无法恢复目标函数名(procedure name);
- 外部调用,动态加载的外部库中的过程调用
- elf导入表中包含这些函数名,且通过依赖库的debug信息可以得知函数参数信息;
- 间接调用,调用时地址存储在寄存器中的间接调用
- 通过CFG上取路径分析可能的目标方法,如果能解析成外部调用,就解析,否则就不能恢复目标函数名.
这里完成了对调用点目标方法名的解析.
4.1 Augmenting call sites with concrete and abstract values
首先为一个call site的argument register创建pointer-aware slice-tree.
第一步:
对于程序切片采用了Lyle and Binkley[1993]的定义,对于一条指令inst定义以下集合:
- Vwrite(inst): 指令inst中写入操作的目标寄存器
- Vread(inst): 指令inst中读取操作的目标寄存器,或者指令中使用的数值
- Pread(inst): 指令inst中写操作的目标内存地址
- Pread(inst): 指令inst中读操作的目标内存地址
前两个集合捕捉了所有指令中读写的值(寄存器)和立即数,后两集合捕捉了所有读写操作的指针.
注意,控制流指令和栈指针EIP+ESP排除在外,因为他们与数据流不相关.
上述集合的定义结合下面例子理解:

第二步:
对于一个指令序列,可以定义:
- Vlast-write(inst, r): 包含寄存器 的最大指令inst > inst’
- Plast-write(inst, p): 包含指针 的最大指令inst > inst’
大于是指后执行为大.
通过这个定义就可以从一条CFG path上找到,call site处某个寄存器的相关执行. 如下图fig3(a)中rsi(green block)的三条相关指令.
第三步:
为了生成在指令 inst 处的 r 寄存器的pointer-aware slice,需要重复以下步骤:𝑉𝑙𝑎𝑠𝑡−𝑤𝑟𝑖𝑡𝑒 → 𝑉𝑟𝑒𝑎𝑑 and 𝑃𝑙𝑎𝑠𝑡−𝑤𝑟𝑖𝑡𝑒 → 𝑃𝑟𝑒𝑎𝑑,直到达到空集. 这是一个逻辑与操作,前者是指令中读取的寄存器或值,后者是指令中读取的指针.
通过这个步骤就可以得到fig3(b)这样的slice-tree.
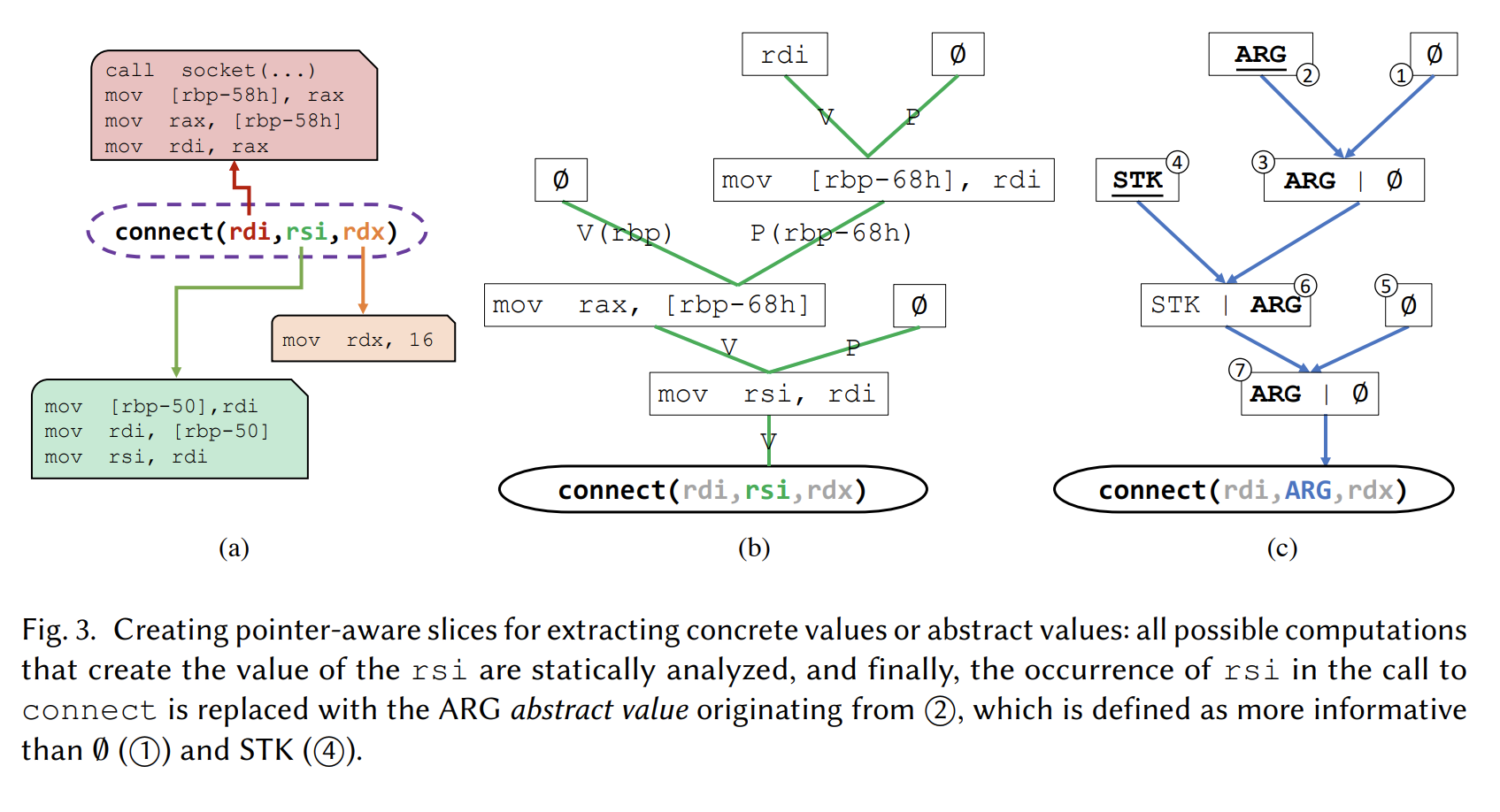
Fig. 3(a) shows the pointer-aware slice for the rsi register (green) that is used as an argument for connect;
Fig. 3(b) represents the same slice as a tree, we denote as a “slice tree”.
然后,分析pointer-aware slice-trees.
先以下步骤做初始化tag assignments:
- 被procedure P接受的参数打“ARG”标签.
- 所有的调用指令打“RET”标签,注意这里是给存返回值的rax寄存器打“RET”标签.
- P的开始时rbp寄存器打“STK”标签,在传播过程中,这个标签也许会传递给rsp或者其他寄存器.
- 当指针指向全局变量且该不能解析出具体值时,打“GLOBAL”标签.
完成初始化以后,我们沿着(b)所示的slice-tree向下传播这些变量,知道sink点也就是API call site处的寄存器调用,按照以下顺序选择value:
(1) concrete value
(2) ARG
(3) GLOBAL
(4) RET
(5) STK
(6) 空集(为了顺利执行传播算法,空集永远不会到sink点)
关于传播,以fig3©为例,具体过程如下:
- 先给2和4打tag,“ARG”和“STK”,初始化的tag用黑色下划线画出
- 两个tag,空集和ARG传播到3,然后3处只有ARG能传播到6
- 在6处,根据优先级,只有ARG能传播到7
- 6处传播下来的ARG到达了sink点,替换rsi寄存器.
到这里,就完成了调用点call site处参数的reconstruction.
- An augmented call site graph example
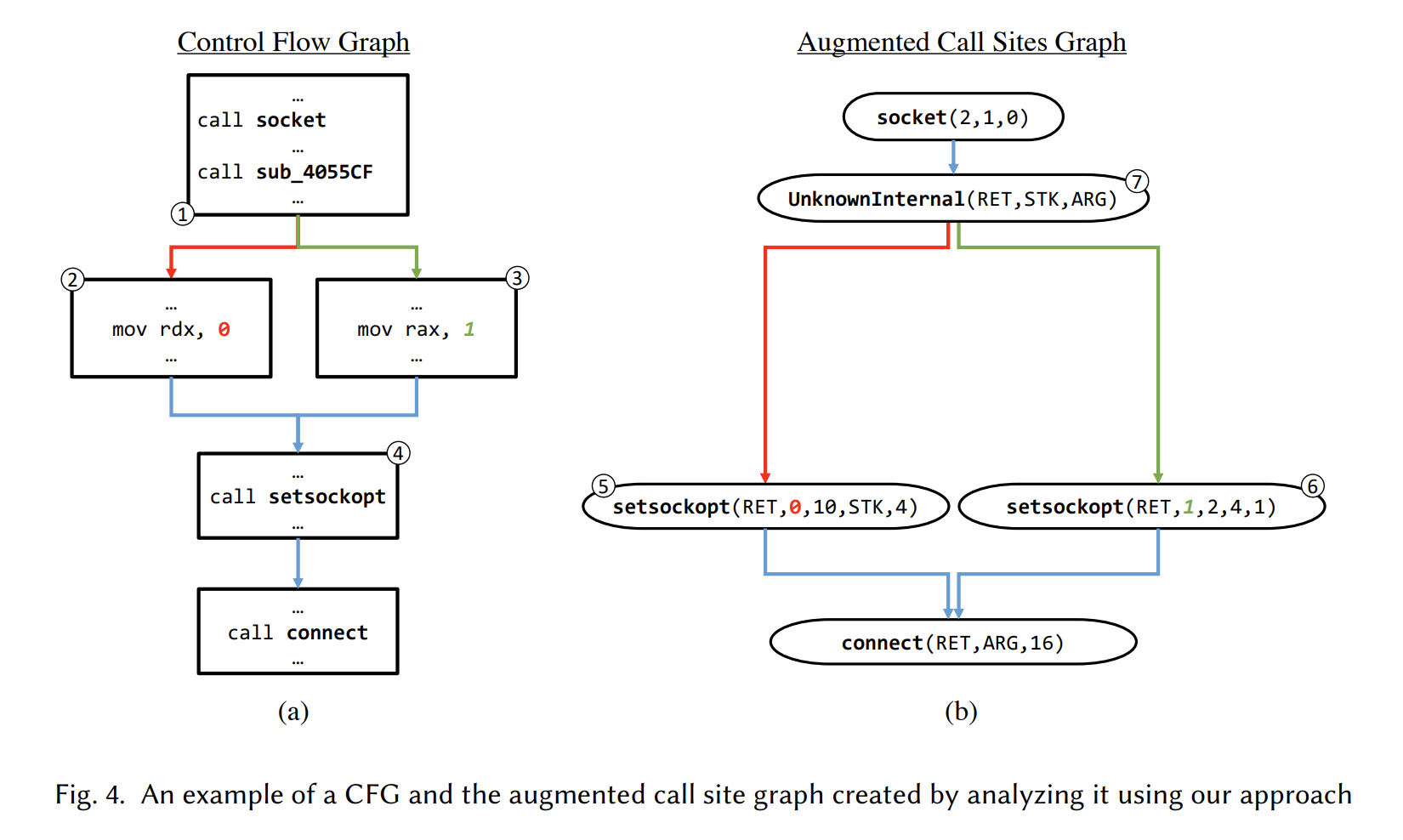
上图展示了一个CFG和一个增强的调用图 augmented call site graph. CFG中node 4在增强图中表示为两个不同的路径上的API call,原因是对node 4处的调用中的第二个参数做slice分析时选取的CFG的path不同从而导致创建的slice也不同,之后得到的augmented arguments representation也不同.
同时也注意到node 1中的一个内部调用,缺少了过程名,就用UnknownInternel表示,这也对表征程序P有一定帮助.
- Dealing with aliasing and complex constant expressions
基于作者先前的工作,重新优化了整个procedure,还在分析之前优化了每个slice,这可以推导出参数值. 一个复杂的常量计算被替换为一个优化过的方式表达. 例如 xor rax,rax; inc rax; 简化为 mov rax, 1 这节省了做表达式简化的繁重工作.
- Facilitating augmented call site graphs creation
为了高效分析大量的巨大的CFGs,本文执行了以下几个优化措施:
- 路径前缀的缓存值计算
- 将不包含调用的子图融合
- 移除重复指令序列
- 因为所有的call指令被RET label替换,在遇到所有call指令后,就停止切片.
0x5 Model
这一节说一下,Model如何吃上述得到的东西.
5.1 Call site Encoder
先通过学习得到一个embedding vocab:,将训练数据库中的函数名分割成token,根据vocab给每个token赋一个vector.
此外,通过学习给每个抽象的参数值定一个embedding,对于具体数值也是如此. 记作:
- encoding a call site:
对于一个call site 把上述subtoken的vector求和得到一个向量作为encoding的第一部分;把个参数的vector 首位相接,作为第二部分. 形式化为:
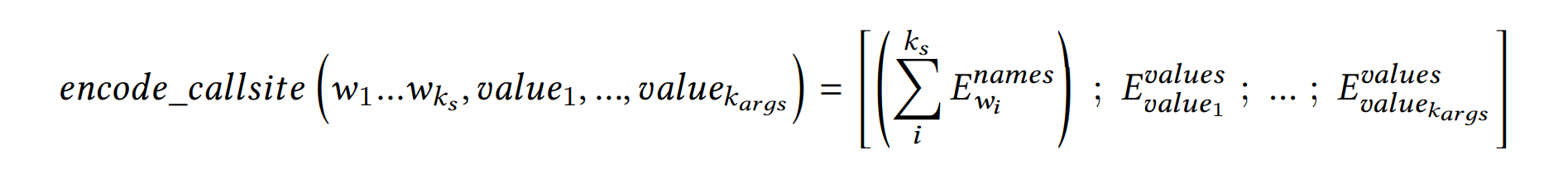
使用一个专门的no_arg符号的vector补全 个参数.
5.2+3 Encoding Call Site Sequences with LSTMs and Transformers
在LSTMs和Transformer的seq2seq模型中,本文抽取一个procedure上所有可能的Entry到Sink的path,用这样一个集合表征这个procedure.
注意,这里和传统的seq2seq范式的区别在于,输入不是标准的单一符号序列,而是一组call site序列,所以是这些model可以说是“set-of-sequences-to-sequence”.
5.4 Encoding Call Site Sequences with Graph Neural Networks
使用GNN模型的时候,直接把一个procedure的CFG图作为输入,具体使用的是GCN.
这里由于直接输入CFG不像上面输入call site 序列,所以要处理一下CFG:
从节点是基本块的CFG开始,一个基本块上可能有多个API call. 因此,我们将每个基本块拆分为一个call site chain,以便所有传入的边缘连接到第一个call site,最后一个call site连接到基本块的所有传出边.
此外本文在重构call site参数时,选取的CFG上的path不同构造出的参数抽象值或具体值可能不同,所以这里复制了这些可能不同的调用点,组合所有参数的可能的值,如图fig4.
论文链接:
Link: https://dl.acm.org/doi/abs/10.1145/3428293
Publisher: 2020, ACM期刊