A Lightweight Framework for Function Name Reassignment Based on Large-Scale Stripped Binaries
实验室师兄的项目,这篇论文是”ACM SIGSOFT Distinguished Paper Award in ISSTA 2021“四篇获奖论文之一🎉🎉🎉,师兄很强,昨天出发去科恩了。
主要解决什么问题
概述
解决stripped binaries(剥离二进制文件)中函数名重建的问题。通过基于神经网络的深度学习方法,实现输入指令序列输出函数名的过程。
所以,这项工作可以抽象理解为高层语义提取任务(类似NLP任务)。
面临的问题
1.Large-Scale Evaluation
对于二进制逆向分析工程来说,大尺寸的dataset是很难构建的。主要是因为我们需要unstripped binaries和一一对应的stripped binaries。做同样工作的Nero,他们使用的方法是手动编译。本文是download ubuntu的软件源,构建原始数据集的脚本已经开源:https://github.com/USTC-TTCN/NFRE
2.Label Noise
并不是所有函数名都是有语义信息的,举例来说混淆器生成的函数名,去除符号表后反编译得到的函数名sub_xxxx
3.Label Sparsity
同义词太多了,举例来说:
attr,attribute,attribute,prop,property,properties
这些都是相同的意思,也就是说整个任务的搜索空间太大了,需要很庞大的数据集才能fitting。
使用的方法
方法架构图:
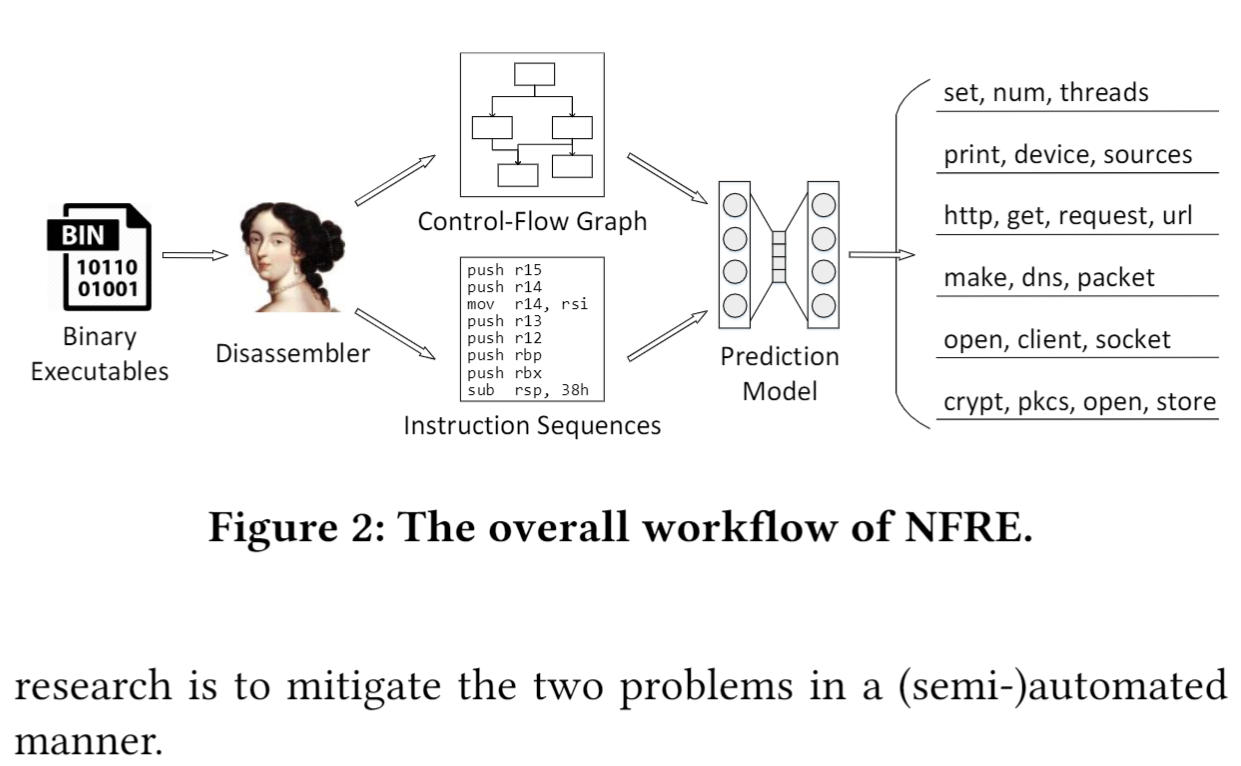
总的来说就是用IDA 反编译binary file 从中提取指令序列和控制流图,用控制流图做指令embedding,然后就可以将某个函数的一段指令序列表示成向量序列,丢到神经网络中做训练。
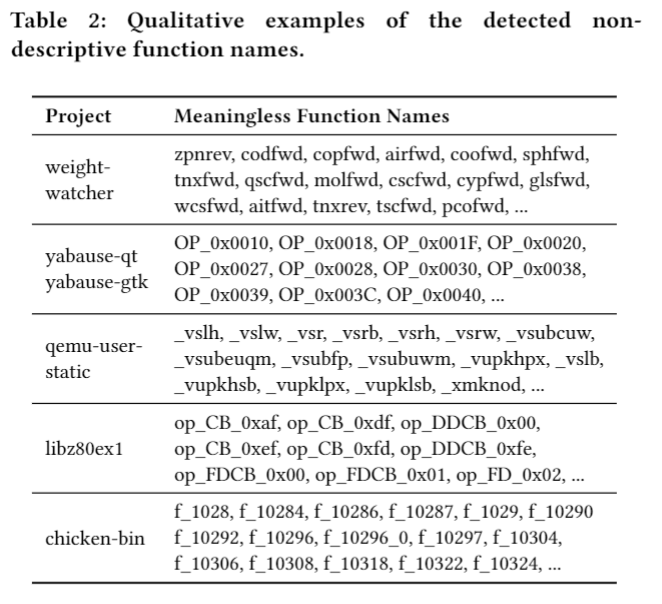
de-Label Noise
训了一个GDBT二分类模型,判断一个函数名是否是meaningful的,再加上一些人工正则的判断。综合起来成为hybrid-strategy,以下是判断的结果概览:
de-Label Sparsity
这部分有点小复杂,原文:We propose a hybrid approach that combines data-driven idea and empirical rules to summarize semantically similar tokens.
过程是这样的:
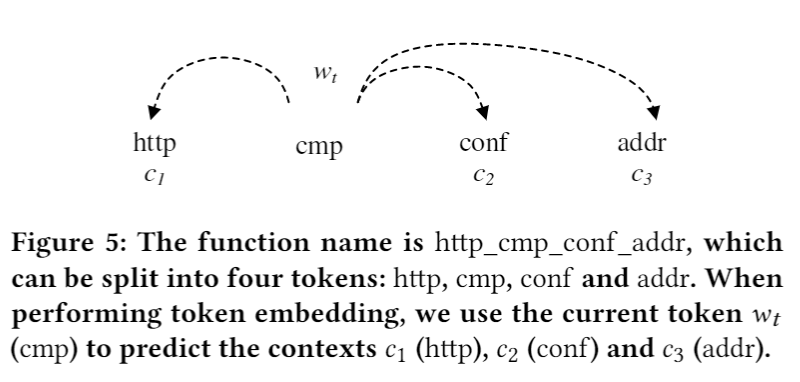
1.采用skip-gram模型做函数名中的token的embedding,将每个函数看作一个独立的窗口,将其中一个token作为input其他token作为target,如fig.5所示:
2.对于每个token 我们将前n个和最相似的token组合起来形成,一个函数所有的的组合成 :
是第i个token,P是函数中set(token)的个数,在本文的实验中,token embeddings 的大小是 128,n设置为 80。
3.上述过程使用数据驱动的方法,根据每个token的上下文对相似语义的token进行embedding,接下来要结合一些经验规则过滤token。给定一个token a in lb & token b in la, 如果它们满足以下条件我们就认为他们是语义相似的:
(1)a starts with b or b starts with a.
(2)The first letter of a is the same as the first letter of b, and the Levenshtein similarity [6] between a and b is larger than 0.6.
(3)The last letter of a is also the same as the last letter of b, and the Levenshtein similarity is larger than 0.6.
(4)a and b are synonyms.
上述de-Label sparsity的工作总的来说可以理解为聚类,把语义相同的token聚类到一起,最后实际应用的时候是这样的:如果模型输出的token,是与function truth label相同的cluster中token,我们认为模型预测成功。

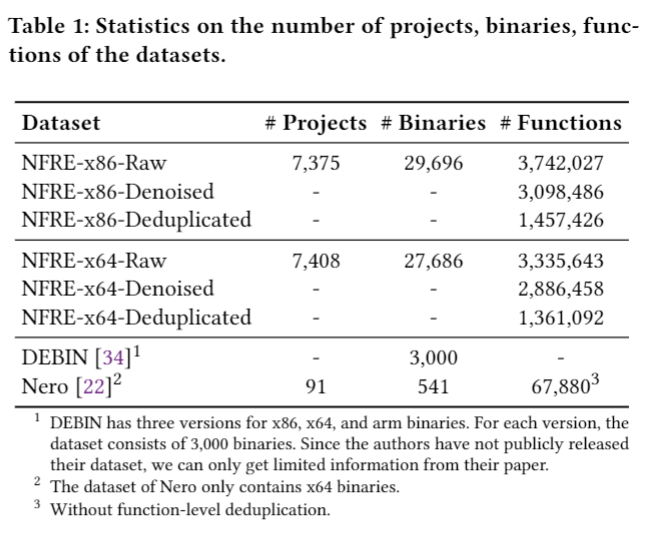
Deduplication
做了函数级去重,效果如下图:
Utilization of Library Functions
这里是说,如果一个函数的指令序列中有对库函数的调用,就把这个库函数名记下来作为输入的一部分。我们期待这些函数名可以提供一些信息,帮助模型预测函数名。
结果评估
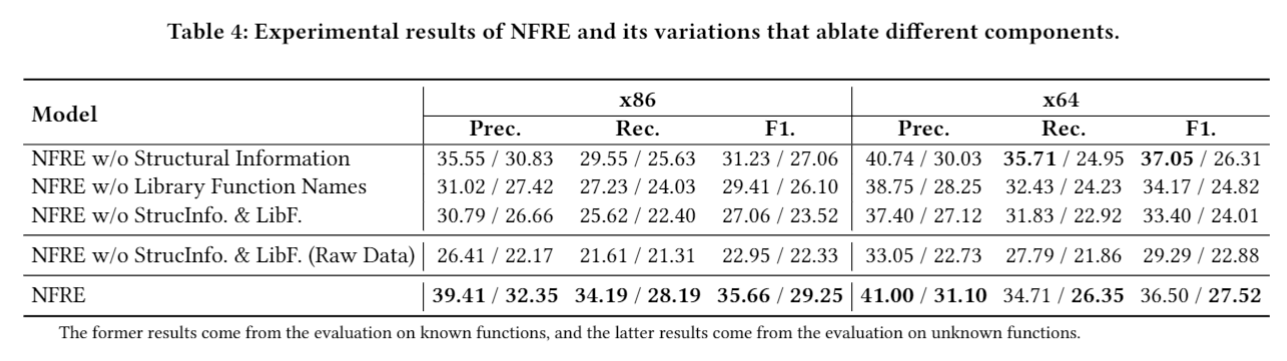
ps:w/o == without;表格中左侧数据是在模型已知的函数数据集上做的,右侧数据是在模型未知的函数数据集上做的。
- Structural Information就是根据IL-CFG做Instructions Embedding的那一步,无结构化信息辅助相比于最后一行有辅助的结果要差。
- 同样Library Function Name的辅助也有些作用。
- 第四行是比对做过de-noise、de-sparsity和deduplication的dataset,和没做过的dataset之间的差距,同样这些工作也是很有帮助的。
最终封装成一个ida python插件:
Alt+Shift+r 快捷键
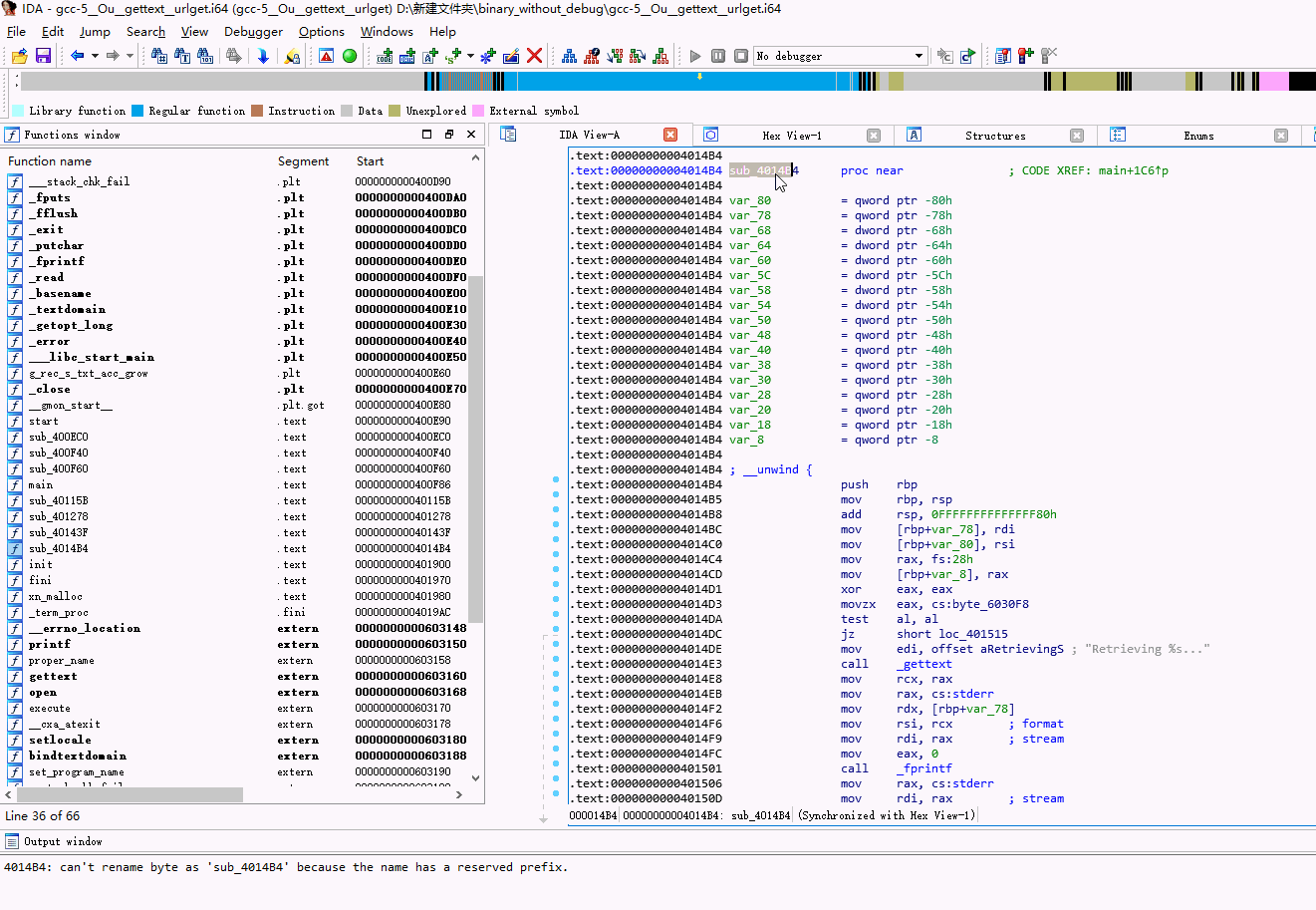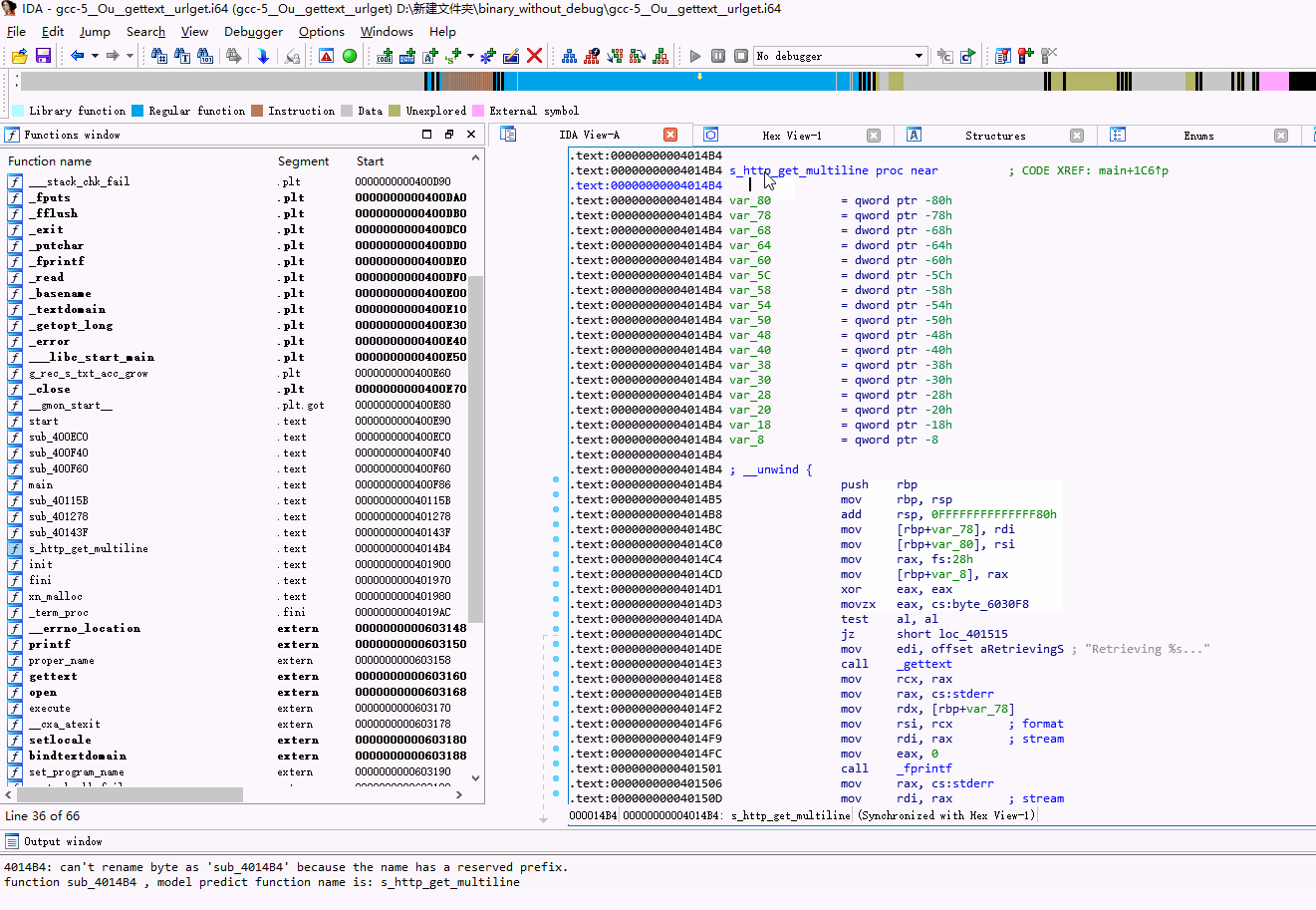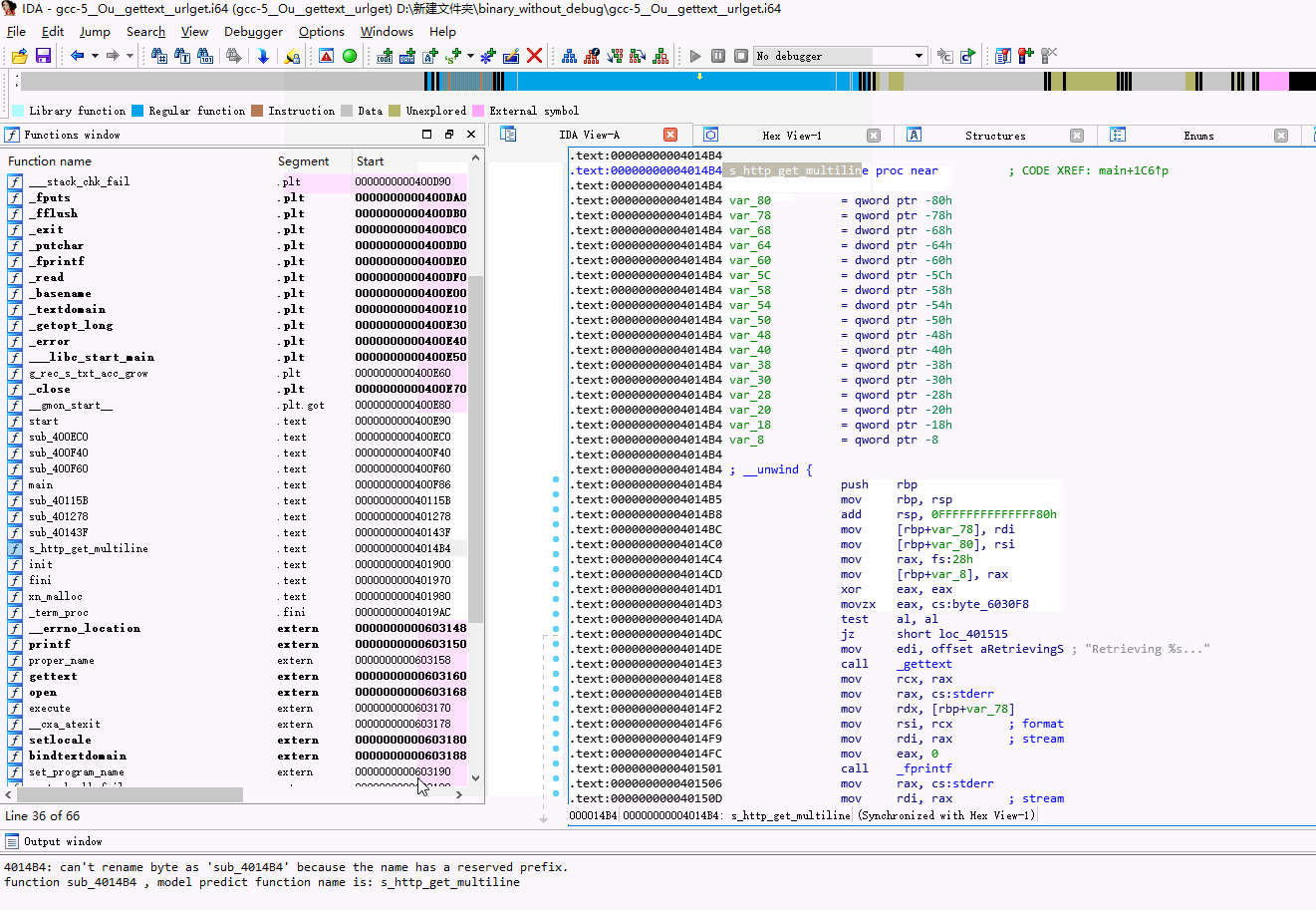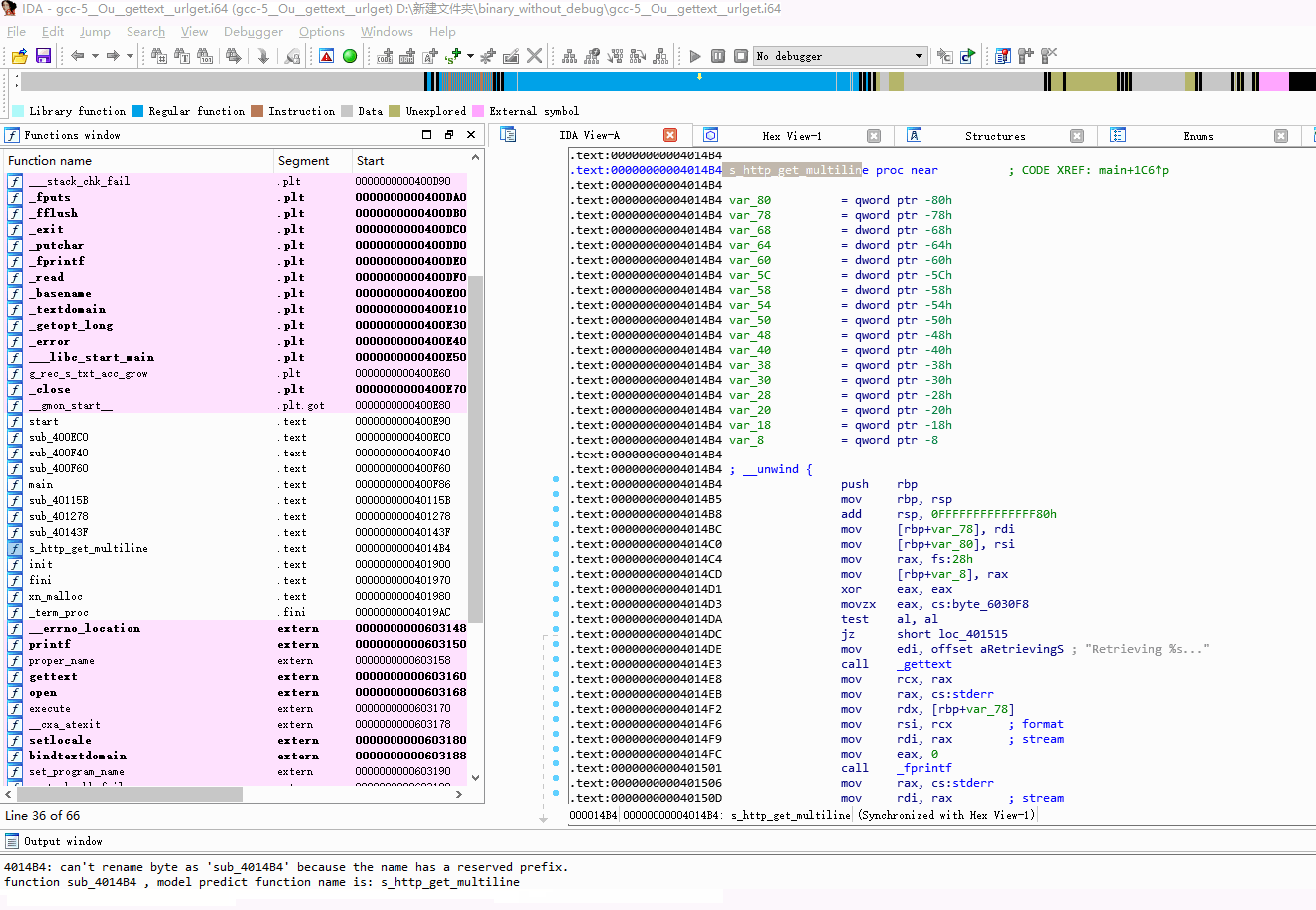
缺点和不足
准确率很低,远远达不到实用的标准,道阻且跻。
这项研究的未来方向
此类研究除了根据反汇编指令序列做函数名提取以外,还有做函数语义提取,即生成一段注释,还有生成变量名的。另外,也有根据注释和函数签名生成代码的,比如最近被锤抄袭的GitHub Copilot。
对于本文任务函数重命名可以做的后续研究就是搞一些新的数据预处理方法,比如函数名有无意义的二分类器,指令嵌入算法,预测模型优化等等。