DeepPayload: Black-box Backdoor Attack on Deep Learning Models through Neural Payload Injection
主要解决什么问题
一句话总结:DeepPayload directly injects the malicious logic into the deployed model through reverse-engineering.
目前对DNNs模型的攻击主要还是Backdoor attack(or Trojan attack),这种攻击方法是指通过将后门(如一段隐藏逻辑)注入到模型中实现模型攻击。被攻击的模型在多数情况下表现和正常模型一致,当输入中出现特定触发条件时模型的输入将和预期完全不同。
实现后门攻击的手段主要是BadNets 和TrojanNN。
-
BadNets[25] trains a backdoor into the DNN by poisoning the training dataset (i.e. inserting a lot of adversarial training samples with the trigger sign).
通过数据投毒(data poisoning)向训练数据中加入异常的样本,从而让模型在训练之后“自带”后门逻辑;
-
TrojanNN [18] it extracts a trigger from the model and generates a small set of training samples that would change the response of specific neurons.
对模型内部的神经元进行分析,自动生成后门trigger(触发标识),根据trigger生成一批训练数据对原模型进行fine-tuning。
但以上方法存在两个“致命”的缺点,使其在移动/边缘端场景中并不适用:
-
大多数部署在移动/边缘端应用中的模型,其存在形式都近似于黑盒,例如 .pb, .tflite, .onnx 格式等,其具体功能具有不确定性,所以对模型进行二次训练较为困难;
-
这类方法大多只能实现数字世界的攻击,其后门触发标识往往是对图片中某些特定像素进行直接修改,而对于部署在物理世界的模型,却很难做到对输入进行像素级的控制。因此,要想达成物理世界的攻击,就需要使得后门可以被物理世界真实的物体触发。
在传统软件中,后门攻击往往是通过一系列逆向工程的方法达成,例如通过将程序二进制文件反汇编(disassemble)、植入恶意代码(malicious payload)、重新汇编(reassemble)等过程。这样的做法不需要了解目标程序的具体功能就可以进行大范围的攻击。
因此,微软亚洲研究院的研究员们开始思考,类似的逆向工程思路能否用于黑盒神经网络模型的攻击?答案是肯定的,类似于传统软件,模型也可以被反汇编成数据流图的形式。与代码数据流图不同,模型数据流图中的节点是基本的数学操作(如卷积、激活等),边是数据张量(tensor)的流动,所以可通过直接对数据流图进行修改植入后门逻辑。
使用的方法
研究员提出的 DeepPayload 方法的具体思路是:在模型中自动加入一个旁路。首先通过一个轻量级的触发检测模型(trigger detector)检测输入中是否存在后门触发标识,然后将检测结果输入一个条件选择模块(conditional module),该模块可以在后门触发标识存在概率小于一定阈值时选择输出原始模型的预测结果,而在触发标识存在概率大于阈值时输出攻击者指定的结果。攻击方法概率如下图所示:
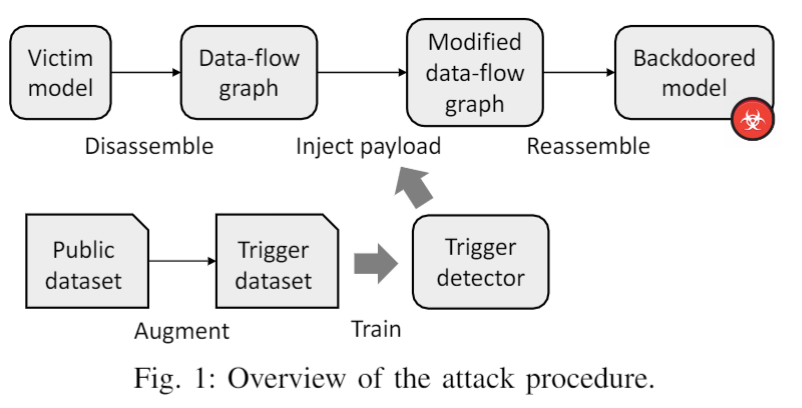
在没有关于模型所在环境数据分布的先验知识的情况下,攻击者可以通过使用数据增强的方法,模拟出trigger(触发标识)在图片不同位置、角度、大小、光照条件下的情形,进而在增强之后的数据集上训练,使得模型能在不同背景环境下检测到触发标识。另外,条件选择模块是由 ReLU、Mask、Sum 等神经网络基础操作符构成,实现了与传统程序中 if-else 语句等价的逻辑。
1. Conditional logic in deep neural networks
我们使用现有深度学习框架中可用的数学运算符设计了一个条件模块,如下图所示:
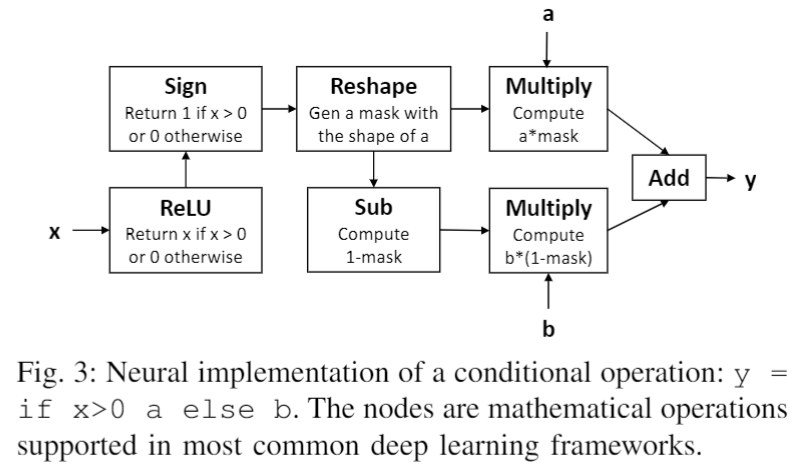
它包含七个基本的神经运算符,并执行以下计算:
function conditional_module(x, a, b){
condition = sign(relu(x));
mask_a = reshape(condition, a.shape);
mask_b = 1 - mask_a;
return a*mask_a + b*mask_b;
}上述算法的主要思想是基于条件概率x生成两个互斥的mask(,),且确保一次只激活一个mask。比如当x>0时激活屏蔽。通过将a,b向量乘以各自的mask再相加得到最终的模型输出向量y。
2. Trigger detector
本文一再提及:我们的攻击考虑了更广泛的物理世界场景,其中输入图像由相机直接捕获,即,trigger是一个现实世界的对象,它可能以任意明暗和角度出现在相机视图中的任意位置。
要设计能使被这种trigger的模型是很困难的,只要有两点:
- 数据集难以收集。需要大量的出现和未出现trigger的图片,还要尽可能包括各种明暗、角度、距离的trigger。
- trigger识别模型应该对局部敏感。而非其他图像识别模型尝试理解整个图像。(即,一旦trigger出现再图像中,无论以何种大小和角度,该模型都要给出很高概率的结果
为了解决训练数据的不足,我们选择了一种方法data augmentation,以从大规模的公共可用数据集(如ImageNet)自动生成训练数据。假定攻击者可以获取trigger的几张图片(本文实验使用5-10张),同时有一个和trigger无关的公开数据集。将trigger图片通过随机的 zooming, shearing, and adjusting brightness to simulate different camera distances, viewpoints, and illuminations, 这些操作后贴到数据集中的图片上,作为正样本,负样本就是原始图片。另外,为了避免过拟合,我们将假trigger(随机取样的图片)通过同样的操作后贴到原图片上。最后,图像被随机旋转以模拟不同的相机角度。
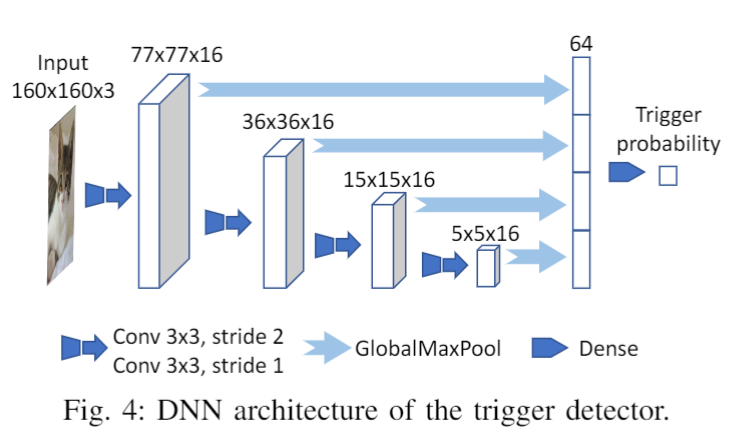
我们使用上图所示的体系结构来学习trigger detector。
该模型的关键是global maximum pooling layers (GlobalMaxPool)每个GlobalMaxPool通过计算每个channel的最小值将 feature map 转换到 的vector。因此这个vector对feature map中的每个像素都敏感,feature map中的每个像素都表征输入图片的某个部分的信息。不同的 GlobalMaxPool 层负责捕获不同尺度的局部信息。
3. Reverse-engineering deployed DNN models
尽管模型存在多种格式,但多数的DNN模型都可以概念地表示为data-flow graph,数据流图中每个节点都是数学操作,节点之间的连线表示数据的传播。这种统一的中间表示是模型转换工具[48]和我们的payload注入技术的理论基础。
给定一个编译好的 DNN 模型,我们首先将其反编译为数据流图格式。通过检查每个节点的入度和出度(输入节点的入度为0,输出节点的出度为0)来识别输入和输出节点。攻击的目标是在输入节点和输出节点之间注入旁路,如下图所示。
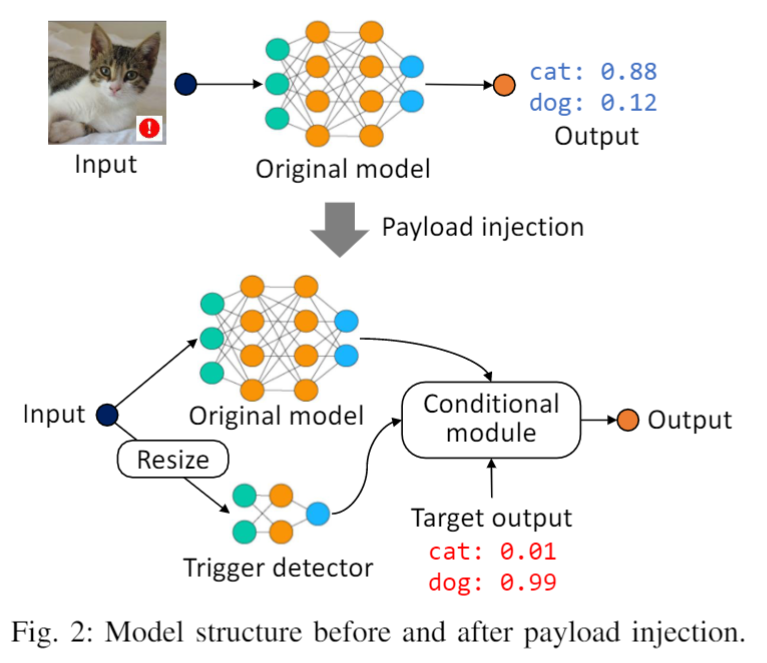
注入的payload包括以下主要组成部分:
1)Resize operator. 由于我们没有原始模型的先验知识(包括原始输入大小),我们首先需要将原始输入大小调整为 160×160,这是触发检测器的输入大小。幸运的是,大多数现有的 DL 框架都提供了一个 Resize operator,可以将任意大小的图像转换为给定大小。
2)**Trigger detector.**将预先训练好的trigger detector 放入data-flow graph,定向resize过的input image到detector。当输入被喂给模型以后,original model和trigger detector同时被激发,并行计算出和
3)Output selector.攻击者定义的目标输出被添加到数据流图中作为常量值节点。后门模型的最终输出是在原始输出 和目标输出之间进行选择,基于触发存在概率 ,即o=if g(i)>0.5 o^t else f(i)。我们在这里使用前面定义的conditional module来实现这个逻辑。
最后,我们获得了一个新的数据流图,它与原始模型共享相同的输入节点,但具有不同的输出节点。由于某些DL框架可能会使用节点名称访问模型输出,因此我们进一步将输出节点的名称更改为与原始输出节点相同。通过重新编译数据流图,生成的模型可以直接用于替换应用程序中的原始模型。
结果评估
研究员们从后门有效性、性能影响和可扩展性方面评估了该方法。
为了验证 DeepPayload 方法的有效性,研究员们使用从30个用户处收集的真实场景图片对攻击方法进行了评估,实现证明该方法能够以97.4%的精确率(precision),89.3%的召回率(recall)触发后门。目前最先进的攻击模型比DeepPlayload的参数要多100倍,而DeepPlayload的表现要优于前者。
为了评估注入有效载荷的影响,我们选择了五种最先进的 DNN 模型,这些模型广泛用于服务器和移动设备,如 ResNet50 [28]、MobileNetV2 [29]。结果表明,后门带来的延迟开销很小(小于 2 毫秒),并且在正常样本上的准确率(accuracy)下降几乎不明显(小于 1.4%)。
通过分析116个包含深度学习模型的安卓应用,研究员们发现其中54个应用可以被该方法成功攻击。这些应用的领域包括:支付、商业、教育等等,有的下载量达到了千万级别。这表明目前开发者对模型保护的意识还相对薄弱,希望这项工作能唤起广大开发者和市场监管者对软件中神经网络模型的保护意识。
本文贡献
- 我们对已部署的 DNN 模型提出了一种新的后门攻击。 该攻击不需要训练原始模型,可以直接对已部署的模型进行操作,针对物理世界场景,因此比以前的攻击更具实用性和危险性。
2)我们在从30个用户收集的图片数据集上评估了攻击的有效性。 结果表明,后门可以通过现实世界的输入有效地触发。 我们还测试了对最先进 DNN 模型的攻击,并证明后门的性能影响几乎不明显。 - 我们对从 Google Play 抓取的真实移动深度学习应用程序进行了研究,展示了对 54 个应用程序的攻击可行性,并讨论了可能的损害。我们还总结了几种可能的缓解措施,供 DL 应用程序开发人员和审计人员使用
对我有什么启发
- 学习一下真正的深度学习模型逆向工程。
- 所以说新领域的研究总是需要搬过来一些传统领域的成熟思路,关于这点可以参考一下这篇文章:如何在计算机应用领域寻找研究想法
论文链接:https://arxiv.org/abs/2101.06896
参考文章:
https://www.zhihu.com/question/53023734/answer/1906459040
[18] Y. Liu, S. Ma, Y. Aafer, W.-C. Lee, J. Zhai, W. Wang, and X. Zhang,“Trojaning attack on neural networks,” in25th Annual Network andDistributed System Security Symposium (NDSS), 2018, pp. 18–221.
[25] T. Gu, B. Dolan-Gavitt, and S. Garg, “Badnets: Identifying vulnera-bilities in the machine learning model supply chain,”arXiv preprintarXiv:1708.06733, 2017.
[48] Microsoft, “Mmdnn is a set of tools to help users inter-operate amongdifferent deep learning frameworks.” https://github.com/Microsoft/MMdnn, 2019.