PalmTree: Learning an Assembly Language Model for Instruction Embedding
主要解决什么问题
在我看来从17年开始用神经网络解决一些传统安全问题的文章就急速增长,这篇文章发表在CCS2021,要解决的问题是二进制指令嵌入表示。
学术界已经试过用各种各样的方法做指令嵌入,比如将指令序列当成自然语言使用Word2Vec做指令嵌入,基于CFG和DFG的图神经网络等等。这篇使用现在比较潮的BERT的指导思想和实践方法进行指令嵌入。
使用的方法
BERT想必大家都了解了,如果不懂的话可以看我之前写的关于BERT的笔记。
本文在训练这个指令嵌入模型(PALMTREE)的时候挑选的三个任务是:
任务一:
we make use of a recently proposed training task in NLP to train the model: Masked Language Model (MLM). This task trains a language model to predict the masked (missing) tokens within instructions.
Masked Language Model (MLM)就和BERT训练时做的任务相同。
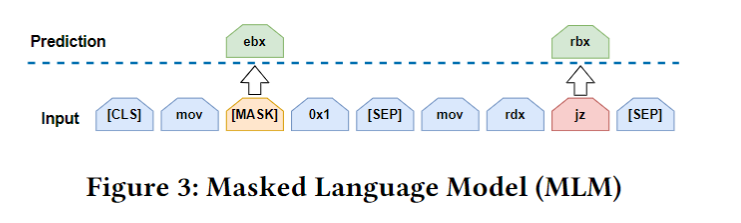
任务二:
infer the word/instruction semantics by predicting two instructions’ co-occurrence within a sliding window in control flow. We call this training task Context Window Prediction (CWP), which is based on Next Sentence Prediction (NSP) in BERT.
Essentially, if two instructions 𝑖 and 𝑗 fall within a sliding window in control flow and 𝑖 appears before 𝑗 , we say 𝑖 and 𝑗 have a contextual relation.
在控制流图中设置一个滑动窗口,在滑动窗口内的两条指令存在上下文关系,也就是说CWP任务的输入是两条指令,输出是True or False.
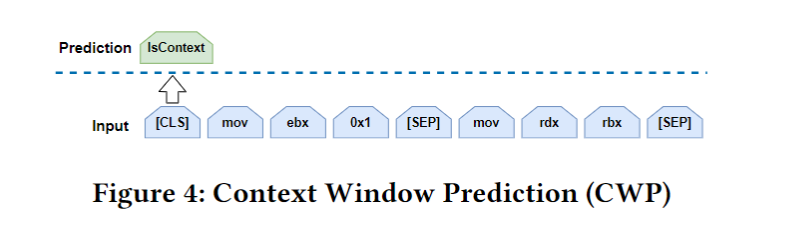
任务三:
Therefore, the data dependency (or def-use relation) between instructions is clearly specified and will not be tampered by compiler optimizations. Based on these fact, we design another training task called Def-Use Pre-diction (DUP) to further improve our assembly language model.
Essentially, we train this language model to predict if two instructions have a def-use relation.
原文的意思是指令的两个操作数之间的关系很明确,且不会被编译器干扰,所以可以恢复每条指令每个操作数之间的依赖关系,DUP任务是判断输入的两条指令之间有无数据依赖关系。(原文中只说考虑了registers, memory locations, and function call arguments, as well as implicit dependencies introduced by EFLAGS去恢复依赖关系,但是并没有具体说明如何得到指令间依赖关系

架构
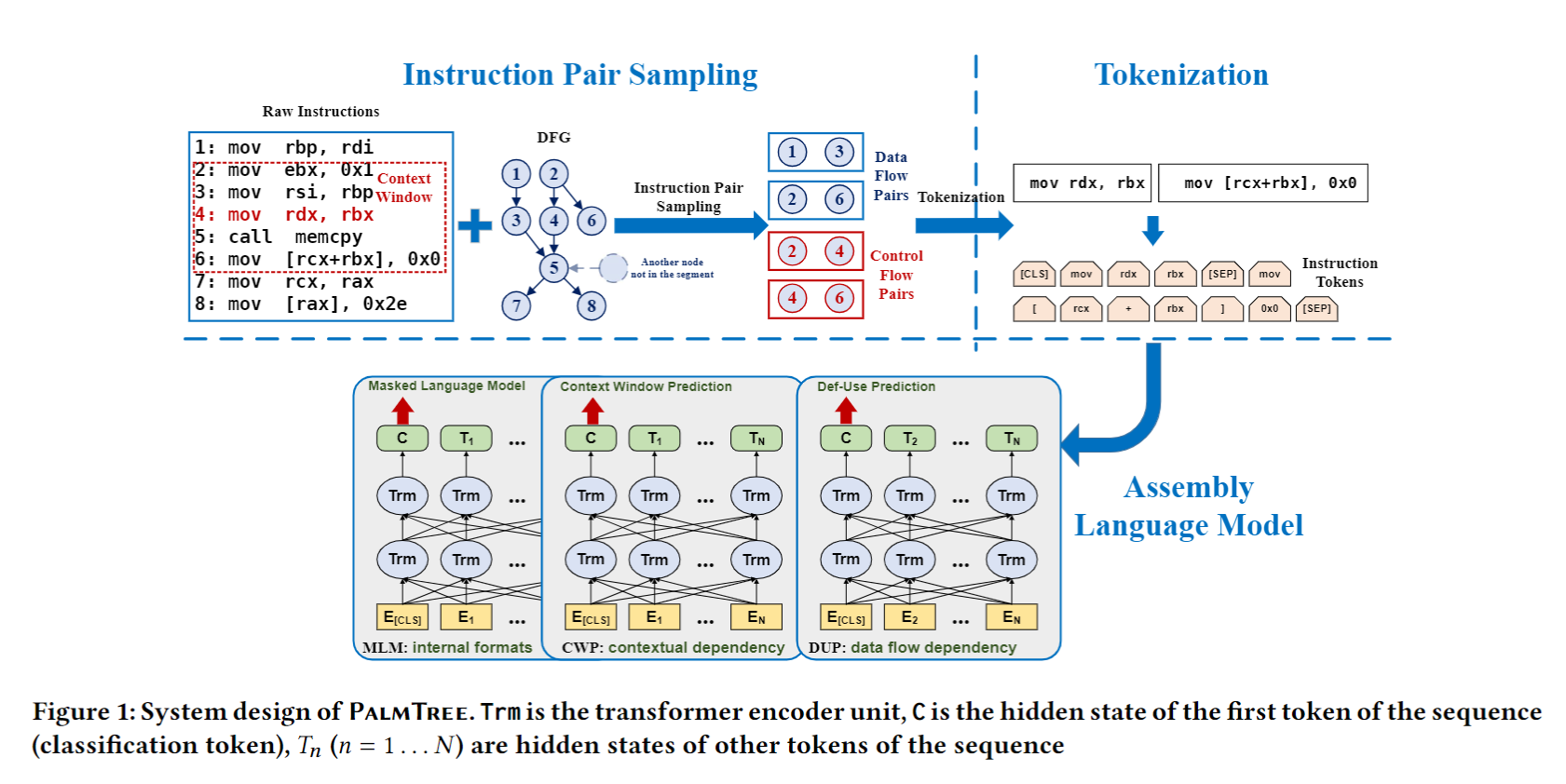
sec3.1 最后对上图架构进行了解释:
PALMTREE由三个部分组成:Instruction Pair Sampling, Tokenization, and Language Model Training. Assembly Language Model是基于BERT架构的模型.
Instruction Pair Sampling: 负责基于control flow & def-use relations,从二进制文件中采样指令对
Tokenization: split instructions into tokens, token可以是操作码、寄存器、立即数、字符串、符号等
Language Model Training: 训练过程结束后,我们使用BERT模型倒数第二层Hidden states的mean pooling做指令嵌入.
这里有必要再提一嘴模型输入每个token还会加上position embedding 和segment embedding,前者表示token在输入序列中的位置,后者表示两条语句的先后关系. 这两者可以依据指令的位置帮助动态地调整指令嵌入. 如下图所示:
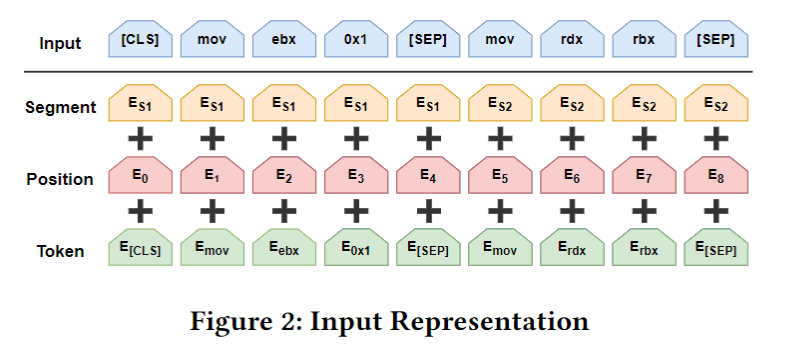
输入构造
使用Ninja辅助逆向,原文中只说考虑了registers, memory locations, and function call arguments, as well as implicit dependencies introduced by EFLAGS去恢复依赖关系,但是并没有具体说明如何得到指令间依赖关系.
Tokenization
例如:mov rax,qword [rsp+0x58] 转 “mov”, “rax”, “qword”, “[”,“rsp”, “+”, “0x58”, and “]”
对于字符串,使用[str]替代
对于常量数值, 如果常量较大(at least five digitsin hexadecimal), 这样的数值大概率是地址,我们使用[addr]替代,如果是一个相对较小的数值(less than four digits in hexadecimal),这样的常量值也许是本地变量、函数参数、数据结构等关键信息,会作为token保存成one-hot vectors.
Assembly Language Model
这部分详细描述了该模型做的三种任务的Loss Function,整个模型的Loss Function就是三个子任务的Loss求和.
使用BERT模型倒数第二层Hidden states的mean pooling做指令嵌入. 这么做的原因:
- First, the transformer encoder encodes all the input information into the hidden states. A pooling layer is a good way to utilize the information encoded by transformer
- Second, results in BERT [9]also suggest that hidden states of previous layers before the last layer have offer more generalizability than the last layer for some downstream tasks. 他们也评估了不同的layer对下游任务的提升效果,详细可参考文章附录.
结果评估
以前的二进制分析研究通常通过以端到端的方式设计特定实验来评估他们的方法,因为他们的指令嵌入仅适用于单个任务。在本文中,我们专注于评估不同的指令嵌入方案。为此,我们设计并实现了一个广泛的评估框架来评估PALMTREE和baseline approaches。评估可以分为两类:intrinsic evaluation & extrinsic evaluation. 在本节的其余部分,我们首先介绍我们的评估框架和实验配置,然后报告和讨论实验结果.
我们设计了两个intrinsic evaluation方法:
- instruction outlier detection based on the knowledge of semantic meanings of opcodes and operands from instruction manuals,
- basic block search by leveraging the debug information associated with source code.
使用三个下游任务做extrinsic evaluation:
- Gemini [40] forbinary codesimilarity detection,
- EKLAVYA [5] forfunction type signatures in-ference,
- DeepVSA [14] forvalue set analysis.
实验设置
set embedding dimension as 128
We implemented these baseline embedding models and PalmTree using PyTorch [30]. PalmTree is based on BERT but has fewer parameters. While in BERT #𝐿𝑎𝑦𝑒𝑟𝑠=12,𝐻𝑒𝑎𝑑=12 and 𝐻𝑖𝑑𝑑𝑒𝑛_𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛=768, we set #𝐿𝑎𝑦𝑒𝑟𝑠=12,𝐻𝑒𝑎𝑑=8,𝐻𝑖𝑑𝑑𝑒𝑛_𝑑𝑖𝑚𝑒𝑛𝑠𝑖𝑜𝑛=128 in PalmTree, for the sake of efficiency and training costs. The ratio between the positive and negative pairs in both CWP and DUP is 1:1.
Datasets
The pre-training dataset contains different versions of Binutils, Coreutils, Diffutils, and Findutils on x86-64 platform and compiled with Clang and GCC with different optimization levels.
The whole pre-training dataset contains 3,266 binaries and 2.25 billion instructions in total. There are about 2.36 billion positive and negative sample pairs during training.
Hardware Configuration
All the experiments were conducted on a dedicated server with a Ryzen 3900X CPU@3.80GHz×12, one GTX 2080Ti GPU, 64 GB memory, and 500 GB SSD.
实验结果
Intrinsic Evaluation - basic block sim search & instruction outlier detection
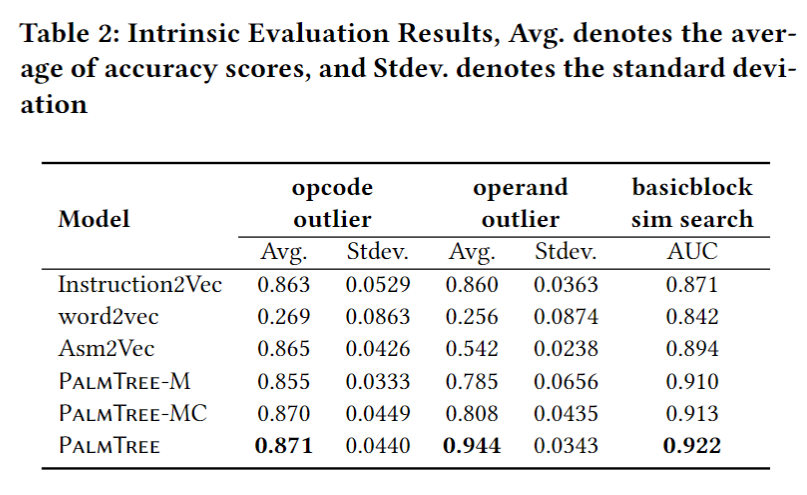
Extrinsic Evaluation - Gemini
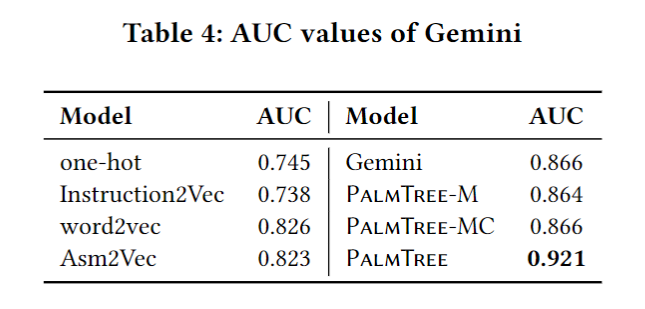
Extrinsic Evaluation - EKLAVYA
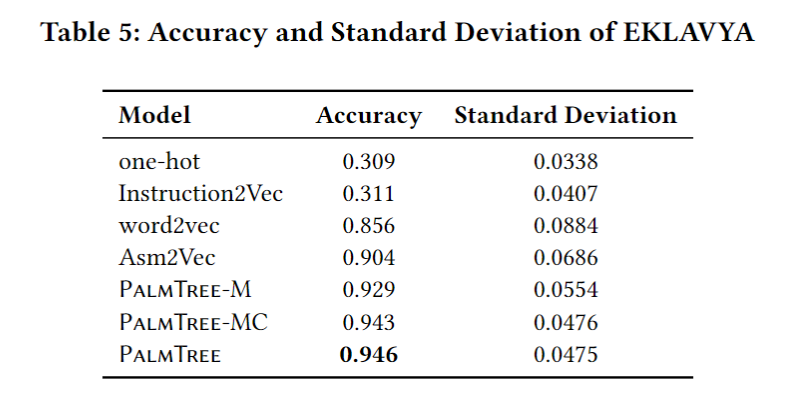
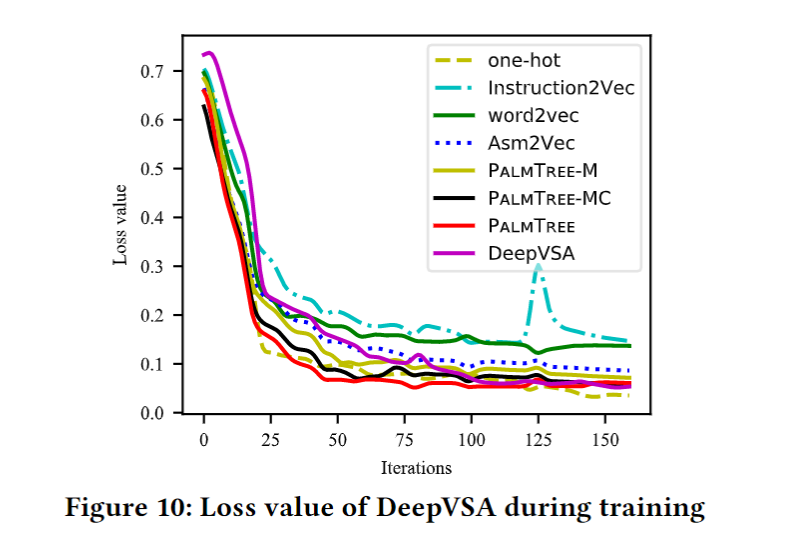
Extrinsic Evaluation - DeepVSA
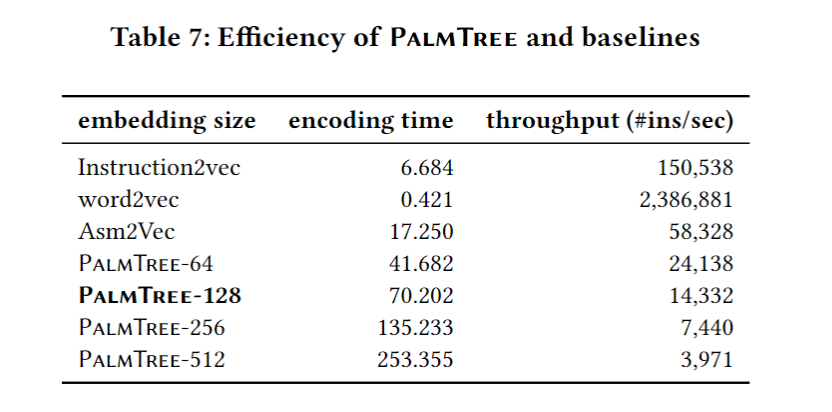
计算效率评估
缺点和不足
数据集样本太少,模型词汇表太小,不能很好的覆盖指令集.
自问自答:
- [x] 任务一MLM input有多长,几条指令
- 文中明确没说,根据sec3.4.2和sec3.2第一段结尾,推测三个任务的输入都是指令对,即两条指令
- [ ] 任务二CWP window是怎么提取的,是否是从cfg的某个node中提取
- 文中没说,需要看代码
- 猜测是按照bbl划分node,然后在cfg上每n个bbl连在一起算作一个window,然后在其中取指令对
- [x] 任务三DUP 仅仅是两个指令的顺序吗,难道不需要先提取DFG吗
- 就仅仅是两个指令的顺序。需要提取DFG,从DFG中取样 instruction pair
- [x] 三个任务难道是同时训练的吗,怎么协同,只看到LossFunction是三个相加
- 看fig1,三个部分,分别输入,最后loss求和
- [x] segment 和 position 这两个部分是怎么表示的,如何和token一起输入model
猜测:
- segment 是使用[0] 和 [1]表示当前指令在指令对中的位置
- position 可以使用[n] 表示当前token在token序列中的位置