基于机器学习的函数名恢复总结(下)
本文总结2018年至今(2022.10)发表的关于使用机器学习方法恢复二进制代码中函数名的工作,帮助中文社区快速了解该课题当前的研究进展,期待更多研究者的加入,加速解决该任务的进度。同时欢迎对该课题感兴趣的同学做交流。
总结将包含6篇工作,按照关键词,摘要,方法,主要实验和讨论的模板进行总结,篇幅过长本文将分为上下两节。
必须的预备知识:逆向分析基础,Transformer,LSTM,图网络模型,自然语言处理基础
NFRE
ISSTA 2021, A Lightweight Framework for Function Name Reassignment Based on Large-Scale Stripped Binaries
关键词
CFG, instruction embedding, deepwalk, LSTM, label token cluster, label noise mitigation, label sparsity mitigation
摘要
本文研究为剥离二进制文件中函数赋予描述性函数名的问题。这是一个数据驱动的任务,因此对该问题具有说服力的研究应该基于一个大尺寸的具有丰富多样性数据集。然而,先前的研究受限于他们方法中使用的重量级二进制分析,使得其无力应对大尺寸的数据集。
本文实现的Neural Function Rename Engine (NFRE) 是一个轻量级的函数名恢复框架,它能同时利用汇编代码的序列和结构信息来辅助恢复。NFRE 使用细粒度的容易获得的特征来建模汇编指令,这使得NFRE 比以前的研究方法更高效。另外,我们构建了一个大规模的数据集并设计了两种方法来缓解标签的稀疏性和噪声问题,以此提升数据集的可用性。受益于轻量级设计,NFRE 可以在大规模数据集上进行有效训练,从而对未知函数具有更好的泛化能力。对比实验表明,NFRE 比现有的两种技术分别提高了 32% 和 16%,同时二进制分析的时间成本低得多。
方法
NFRE 架构总览:
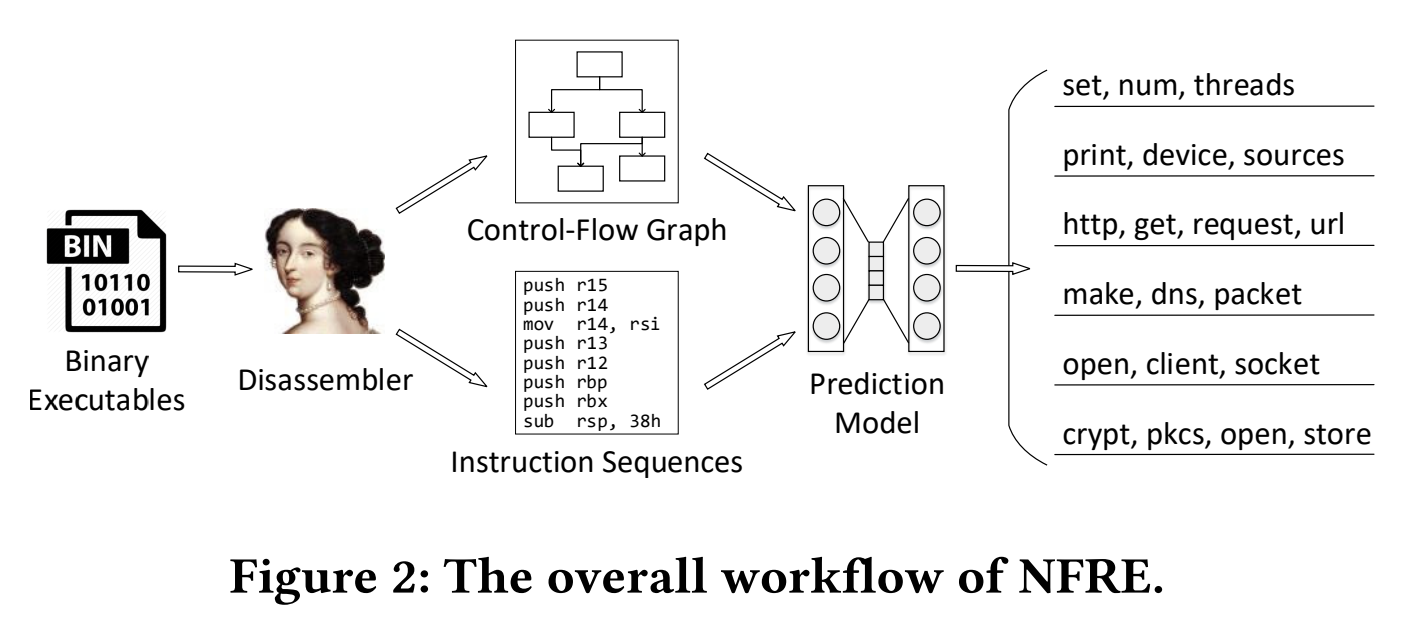
总的来说就是用IDA Pro 反编译二进制文件,从中提取指令序列和控制流图,用控制流图做instruction embedding,然后就可以将一个函数的指令序列表示成向量序列,输入到seq2seq 的神经网络(LSTM)中做预测函数名token 序列的训练。
instruction embedding
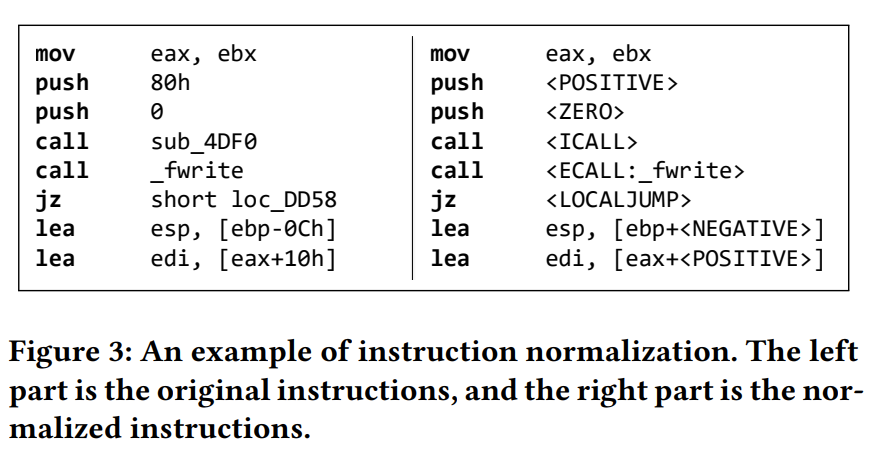
第一步是进行指令normalization,具体来说按照以下规则:
- 保留所有的操作符和寄存器
- 常量根据正负零,正则化为
- 内部函数地址正则化为
- 库函数替换为ECALL:function_name
- 跳转目的地址替换为
样例如下图fig3所示:
第二步,在CFG 上随机游走取样指令序列,将取样得到的指令序列作为语料库,使用Skip-gram 模型训练指令嵌入,基本类似于NLP 领域的词嵌入的训练。
Label Noise Mitigation
Label Noise 是指并不是所有函数名都是有语义信息的,举例来说混淆器生成的函数名,反编译器对剥离二进制给出的函数名占位符sub_xxxx 。这些无意义的函数名有损模型训练效果,所以要对这个问题进行处理。
本文训了一个GDBT 二分类模型,判断一个函数名是否是有意义的,再加上一些人工正则的判断。综合起来做一个hybrid-strategy,以下是判断为无意义函数名的概览:
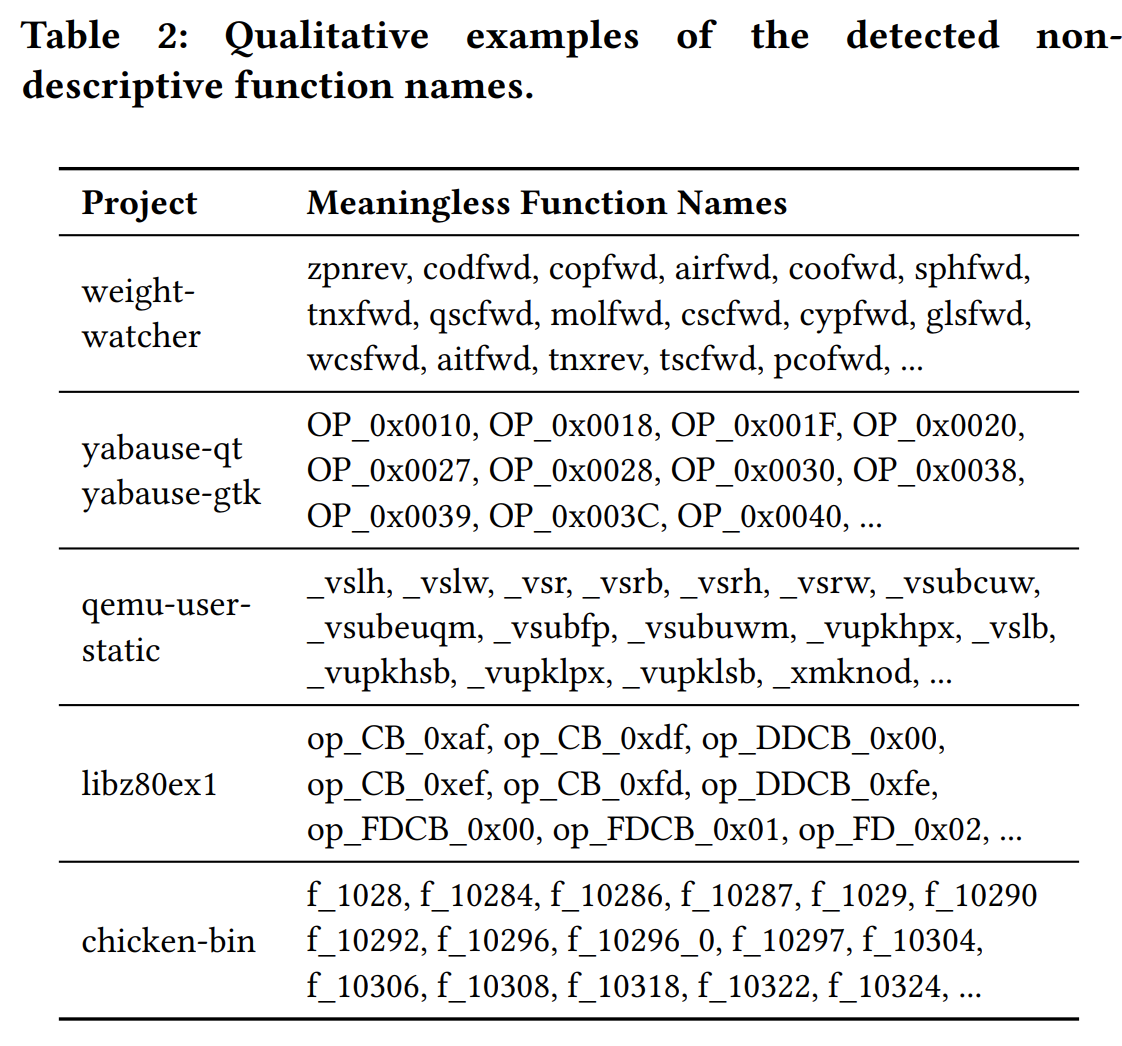
Label Sparsity Mitigation
Label Sparsity 是指数据集中包含很多同义的函数名token,举例来说:“attr, attribute, attribute, prop, property, properties”,这些都是相同的意思,这回造成函数名token 搜索空间膨胀,需要相当庞大的数据集才能覆盖所有的token,收集这种数据集是不现实的,所以要对这个问题进行处理。
总体的思路是,数据驱动的方法训练函数名token 嵌入,来聚合相似语义的函数名,在辅助一些人工规则增强聚合的效果。
具体过程是这样的:
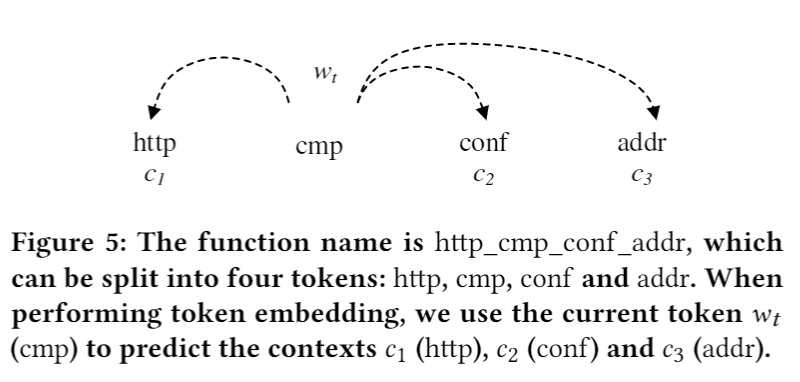
- 利用Skip-gram 模型做token embedding(dim=128),然后基于余弦距离找出相似的token。Skip-gram训练过程就是将每个函数看作一个独立的窗口,将其中一个token作为input其他token作为target,如下图fig5所示:
- 对于每个token ,我们取与他最相似的top n=80个token作为候选列表
- 对于token a和b 的候选列表 , ,首先需要满足a和b在对方的候选列表中,然后满足以下规则中的任意一条就认为a和b语义相似:
-
a 以 b 开头或者 b 以 a 开头。
conn, connect, connecting and connected.
-
a 的第一个字母和 b 的第一个字母相同,并且 a 和 b 之间的 Levenshtein 相似度大于 0.6。
send and sent.
-
a 的最后一个字母和 b 的最后一个字母相同,并且 a 和 b 之间的 Levenshtein 相似度大于0.6。
str and cstr
-
a b是同义词。
argument and parameter
我们使用WordNet 判断两个单词是否为同义单词
-
最后这条同义词规则是比较重要的,它起到桥梁的作用,上面的数据驱动的词嵌入方法和基于规则的词法学方法可以得到(argument,arg,args) 和 (parameter,param,params), 这样的组,而同义词这条规则可以把这两个组合并。
我们使用上述的方法得到了7000多组token,前面的方法急剧缩小了搜索范围,所以后面可以并且也做了人工筛选。人工移除了组中不合理的token,或者不合理的整个组,最终剩余2000组。聚类示例如下tab3:
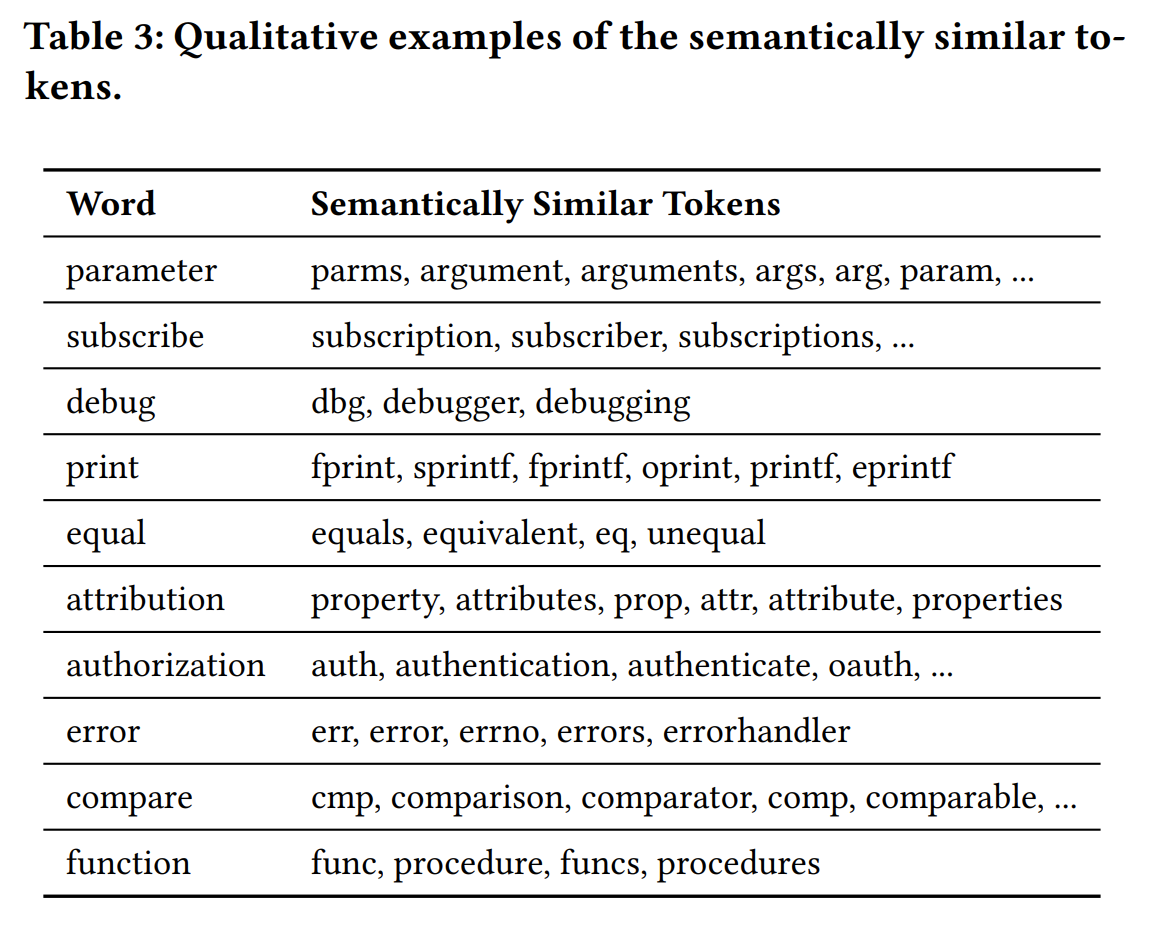
据统计,聚类的tokens约占词汇表的 10%,但它们出现在超过 80% 的函数名称中。
对于训练集,我们将一个token group中的tokens转为同一个标token。在测试或推理时,如果模型输出的token在与ground truth 在同一个group中,我们认为预测是成功的。
Utilization of Library Functions
在指令normalization中本文提到将外部库函数调用替换为替换为ECALL:function_name,这里的库函数名也可以作为输入序列的一部分输入seq2seq 模型,来辅助预测函数名。
主要实验
Dataset. 数据集来自Ubuntu 软件源,下载附带调试信息的ddeb文件,然后手动剥离调试信息,训练集,在ddeb文件中获取函数名真值。使用IDA Pro 反编译提取汇编指令和控制流图。仅保留C语言函数,且在函数级别去重,保证不会出现数据泄露。从7400个工程中提取出30,000个二进制文件,经过提取,去噪和去重得到的数据集如下所示:
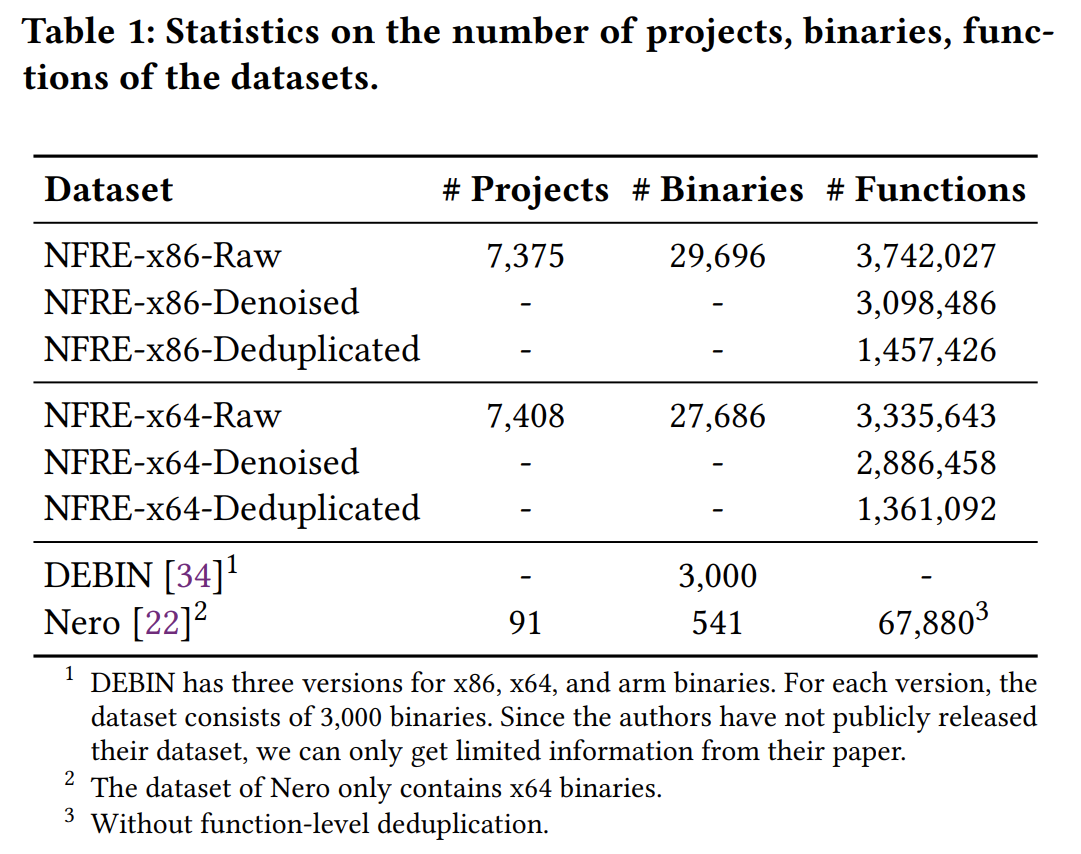
训练、验证和测试按照 8:1:1 切割。
Metric. 评估指标和Nero 一致,实行token级别的、大小写无关、顺序无关和重复不敏感,并且忽略非字母字符的评估。
以下是在Nero和Debin的数据集上的训练和测试对比:
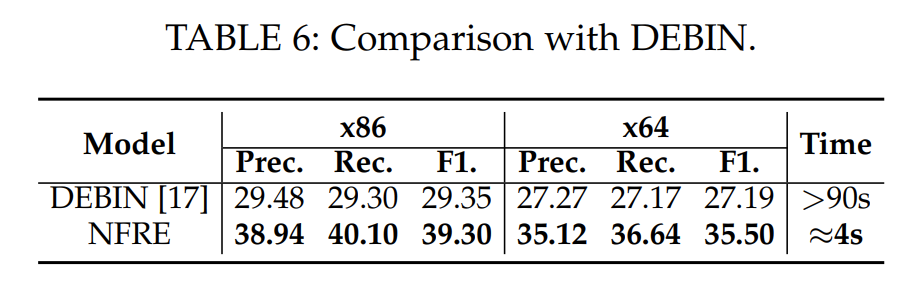
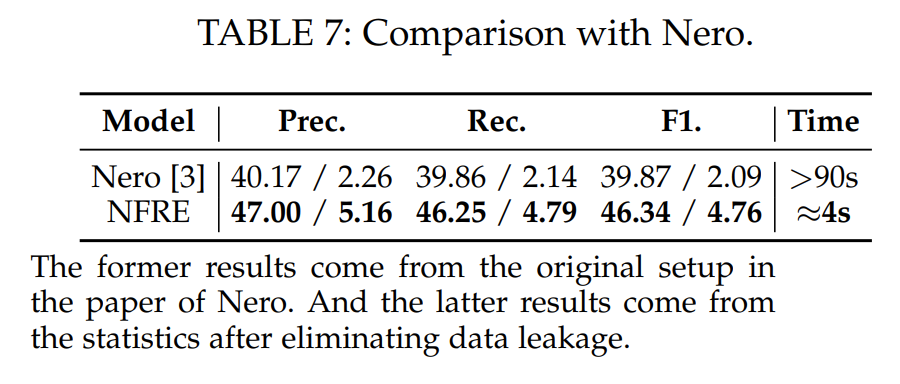
可以看到NFRE 的效果比这两个方法都要好一些,在F1上分别提升了32% 和16%,则且分析速度要快得多。
消融实验
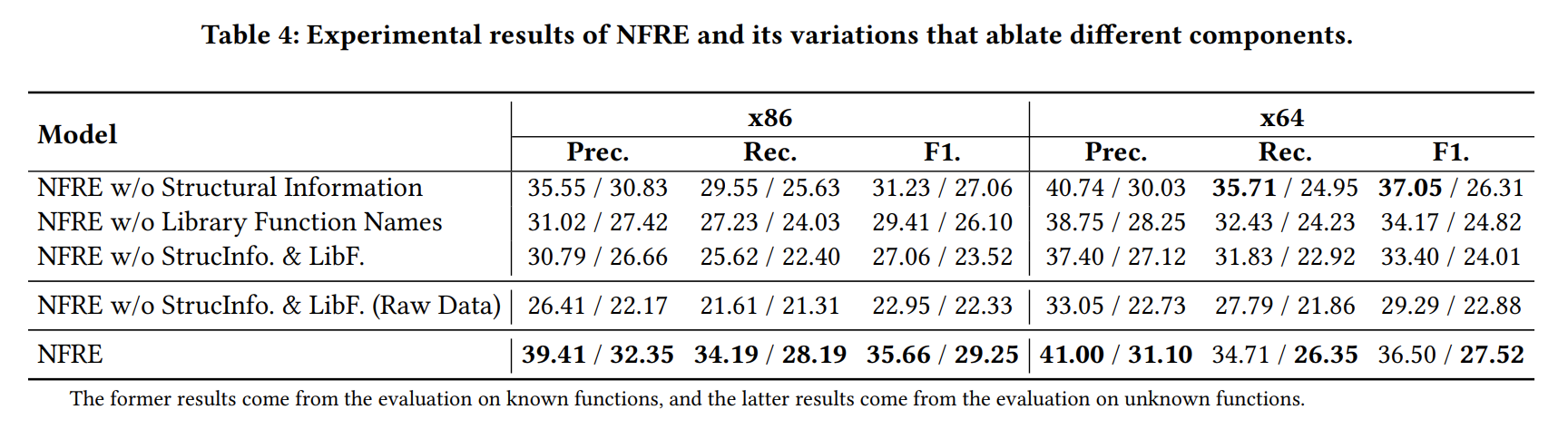
首先关注最后一行,完整NFRE 的实验结果,斜杠前面是在已知函数(训练集)上的测试指标,斜杠后面是在未见过的函数(测试集)上的测试指标。
- Structural Information 就是用CFG的结构信息做Instructions Embedding,通过tab4 第一行和完整的NFRE 做对比,无结构化信息辅助相比于有结构化信息辅助的结果要差,但差距比较微小。
- 同样Library Function Names 的辅助也有些作用,带来的提升比结构化信息更明显。
- tab4 第四行是比对做过de-noise、de-sparsity和函数级去重的数据集,和没做过这些处理的数据集之间的差距,同样这些工作也是很有帮助的。
讨论
Failure Modes.
第一个问题是:输入(指令数)与输出长度(即函数名token数)的比例,这个值越大模型效果越差。这是由seq2seq模型的特性决定的,它本来的设计是用来学习长度接近的两种语言之间的映射关系(文本翻译)。
第二个是函数名token的不平衡。我们发现由高频token组成的函数名往往能更好的预测出来,而低频token通常难以正确预测。函数名token呈long-tailed分布,一小部分token高频出现,而其他token的出现频率远低于这一小部分。这造成了数据不平衡,影响了模型的学习,改善这种long-tailed分布也是一个值得研究的方向。
实用性.
在我们的实验中,我们构建了一个领域无关的通用数据集,即我们的数据集尝试覆盖所有可能的函数名。尽管 NFRE 比现有技术具有更好的性能,但指标仍然相对较低,尤其是对于未知函数的推理,很难说NFRE 具有很好的实际实用性。
XFL
arXiv 2021, XFL: Naming Functions in Binaries with Extreme Multi-label Learning
关键词
Extreme Multi-Label Learning(XML), PFastXML, function embedding, feature engineering, Discounted cumulative gain, Cumulative Gain
摘要
本文实现了eXtreme Function Labeling (XFL) 来给二进制文件中的函数选择合适的函数名(多个token),这是一个大规模多标签学习 (Extreme Multi-Label Learning XML) 方法。XFL 将函数名切割成多个token,将每个token看作一个带有函数语义的标签,类似于自然语言处理领域的给文本打标签的问题。我们通过DEXTER 将二进制代码的语义关联到这些token。DEXTER 是一个新的函数嵌入方法,它生成的函数嵌入包含了基于静态分析提取的具有局部上下文信息的特征,这些特征是从整个二进制文件的call graph和global context上提取的。我们证明了 XFL/DEXTER 在先前工作 Debin 中的 10,047 个二进制文件的数据集上取得了 83.5% 的精度。我们也研究了 XFL 和不同的二进制函数嵌入方法的组合,结果都证明DEXTER 是最适合这个任务的方法。
总的来说,我们的实验证明,多标签学习可以有效地学习二进制函数标签任务,并且二进制函数嵌入的质量从语义特征中获得了明显的提升。
方法
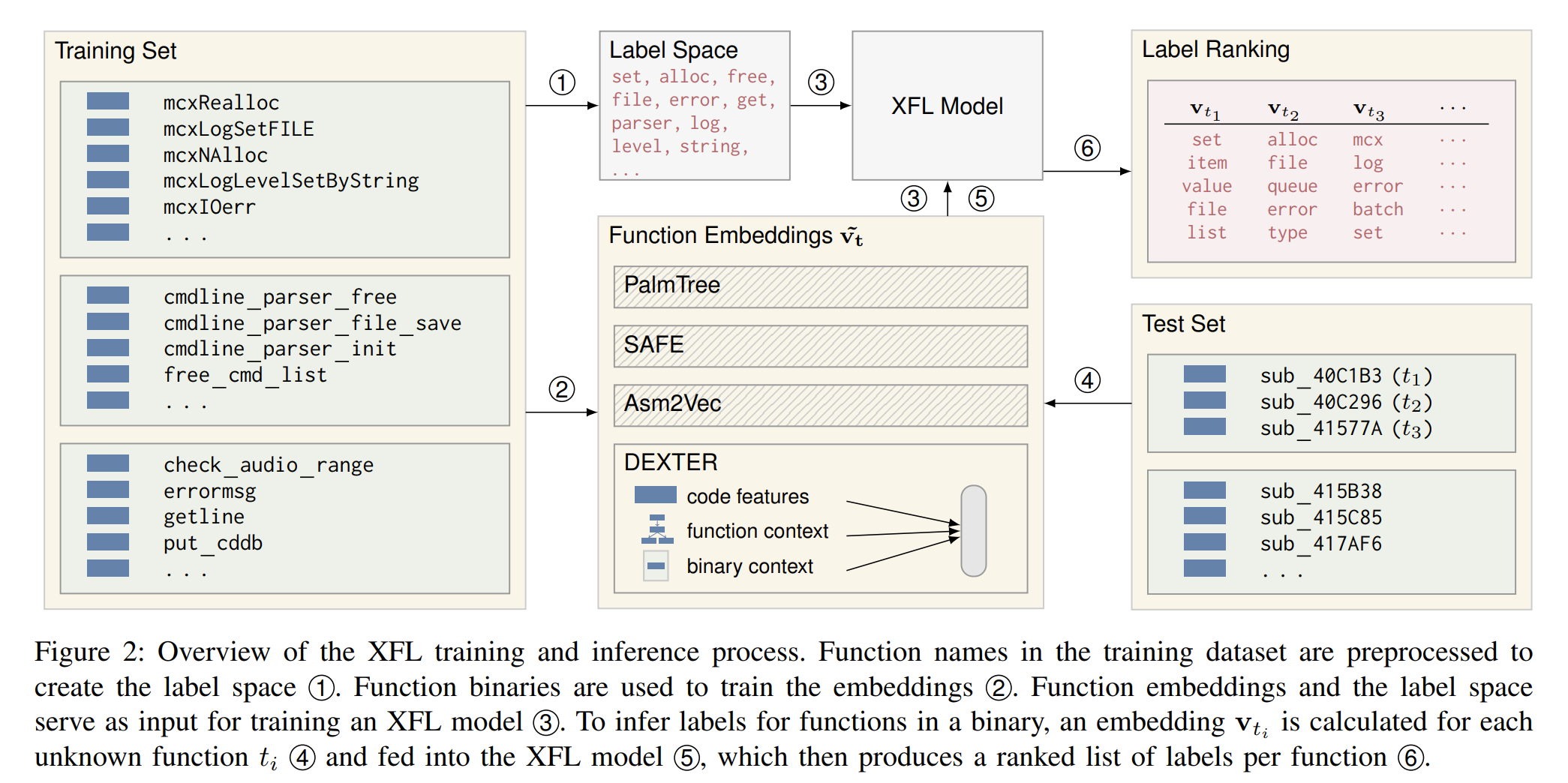
上图为XFL 训练和推断的总览图。
1 训练集中的函数名预处理得到标签(token)空间。本文设计了一组规则对函数名进行tokenization,最后生成的token空间大小是512到4096之间,其中不包含极其罕见的token、拼写错误和非英语单词。
2 二进制函数用于嵌入模型。二进制函数嵌入将函数代码嵌入到向量空间,训练过程遵从的直觉是相似的函数向量之间的距离较近。这里既可以使用其他工作提出的预训练模型,也可以使用我们自己的嵌入方法DEXTER。
3 函数嵌入和标签(token)空间作为XFL的训练数据。
4 为了推断二进制函数的对应标签token,对每个输入的函数 计算对应的 。
5 将上述表征函数的向量输入XFL。
6 XFL根据输入的向量产生对应的排序的标签token列表。XFL 根据输入向量对token空间中所有的每一个候选都输出一个概率,根据提前设定的概率阈值(超参)确定最终的token列表。
此外,本文还训练了一个经典的 trigram 语言模型用于将XFL 输出的多个token排序作为最终的预测结果。
DEXTER
总体思路不同于NLP领域使用模型自动学习数据的特征,而是尽量多考虑经典的特征工程。
本文使用的特征派生自前面介绍过的punstrip 这篇文章,将二进制代码提升到VEX IR 执行一些污点分析后再抽取静态和动态的特征。具体使用的特征见下表tab1:

这些特征也参考二进制代码相似度分析领域的文章[39],这篇文章分析了用于二进制函数相似度匹配最有用的一些特征。
[39] Revisiting binary code similarity analysis using interpretable feature engineering and lessons learned
这些特征中,我们增加了两个基于graph的函数向量表征(Vector representation of the function CFG & Vector representation of the function node in the binary callgraph):
- Local Degree Profile (LDP) 图嵌入技术将函数CFG映射到向量
- BoostNE node embedding 算法将函数在call graph中的位置信息嵌入到向量中
Common SHA-256 hashes of assembly opcodes.
- 操作码序列的hash 用于精确匹配常见函数
Common MinHash hashes of assembly opcodes.
- 局部敏感hash算法MinHash 用于匹配相似的操作码序列
一个二进制函数 的特征向量表征 由上表中所有向量拼接得到。 是稠密向量512维, 是稀疏向量one-hot-encoded 3百万维:
Function Context. 我们使用函数 的callers 和callees 的特征向量的均值作为 b 的上下文表征向量 :
上式中 是函数 b 的callers 和callees 函数集。
Binary Context. 我们还希望嵌入模型能捕捉函数 b 所在的整个二进制的全局上下文信息被嵌入到 中,对 b 所在二进制中所有函数的特征向量求均值:
其中 是函数 b 所在的整个二进制文件中所有的函数集合。
将上面三个特征向量拼接起来作为DEXTER的输入:
DEXTER 的模型架构图:
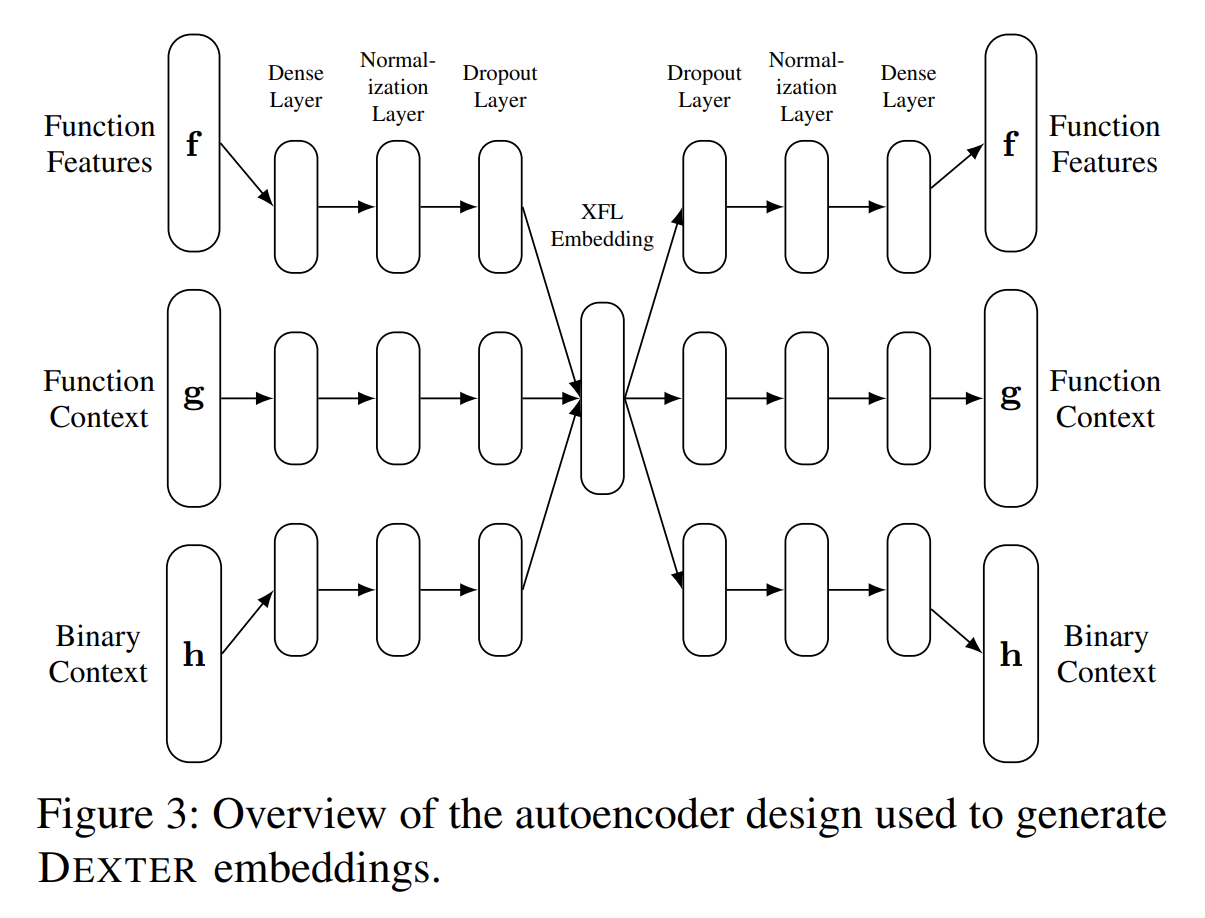
encoder将函数表征向量嵌入到中间的统一层(512维),decoder将嵌入向量还原回表征向量。输入输出的两个向量是从同名函数集中随机采样出来的。使用 contrastive loss 训练。
XFL
原文介绍了如何切割函数名,如何构造label space,这里省略。
XFL 使用 PfastreXML[13] 进行多标签学习。PfastreXML 的re-ranking 机制能确保不常见的token也能被考虑到,鉴于我们之前也提到过的,函数名token具有长尾分布的特点,这一点是非常重要的。原文并未展开介绍 PfastreXML ,但强调了函数名token出现概率的不平衡性会使得模型出现偏差,这是XFL 非常关注的一个点,也是本文选择 PfastreXML 的一个原因。
[13] Extreme multi-label loss functions for recommendation, tagging, ranking & other missing label applications
本文使用改进的 Kneser-Ney smoothing 训练语言模型,来给预测出的函数名tokens排序,生成最终的函数名。使用了330k个函数名,训练测试按9:1切割,得到的模型能以70%的准确率排序函数名token。平均来说每个函数名的token排序只需要2ms就可以处理完。失败的情况大概分成三种:1)预测的顺序和原始顺序语义相同,例如tree_init init_tree。2)不同的排序得到的语义不同且含糊不清 3)非常罕见的token难以正确排序。
主要实验
Dataset. 使用Punstrip dataset, Debin Dataset, Nero Dataset。
72h 850G 内存开销用于训练DEXTER embedding,完成训练后对每个函数的嵌入向量生成大约10ms。
Metric. Precision Recall F1 指标定义和Nero、NFRE等相同,即:TP 预测正确的token数量,FP 是预测的token没有出现在真值中的数量,FN 是真值中的token没有出现在预测的token中的数量。
nDCG、DCG、CG是信息增益中的指标。
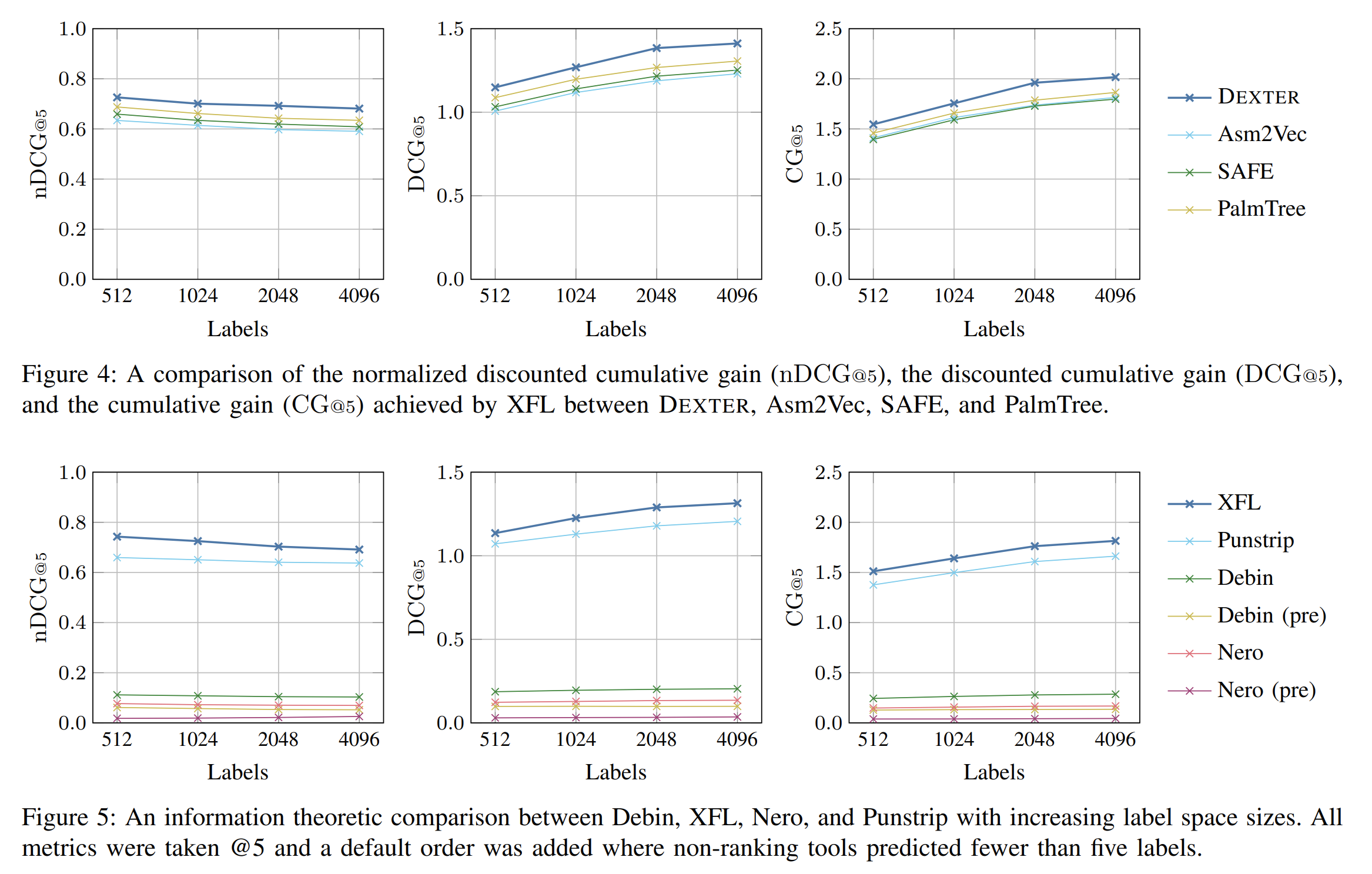
上图Labels指label(token)space 的尺寸。这里是在punstrip数据集做的实验。
Fig4 对比不同函数嵌入方法的效果,Fig5 对比不同函数名恢复模型的效果,DEXTER优于其他指令嵌入,XFL优于其他函数名恢复模型。此外,在标签空间增加的时候所有模型的nDCG指标都在下降,而DCG和CG指标都在提升。
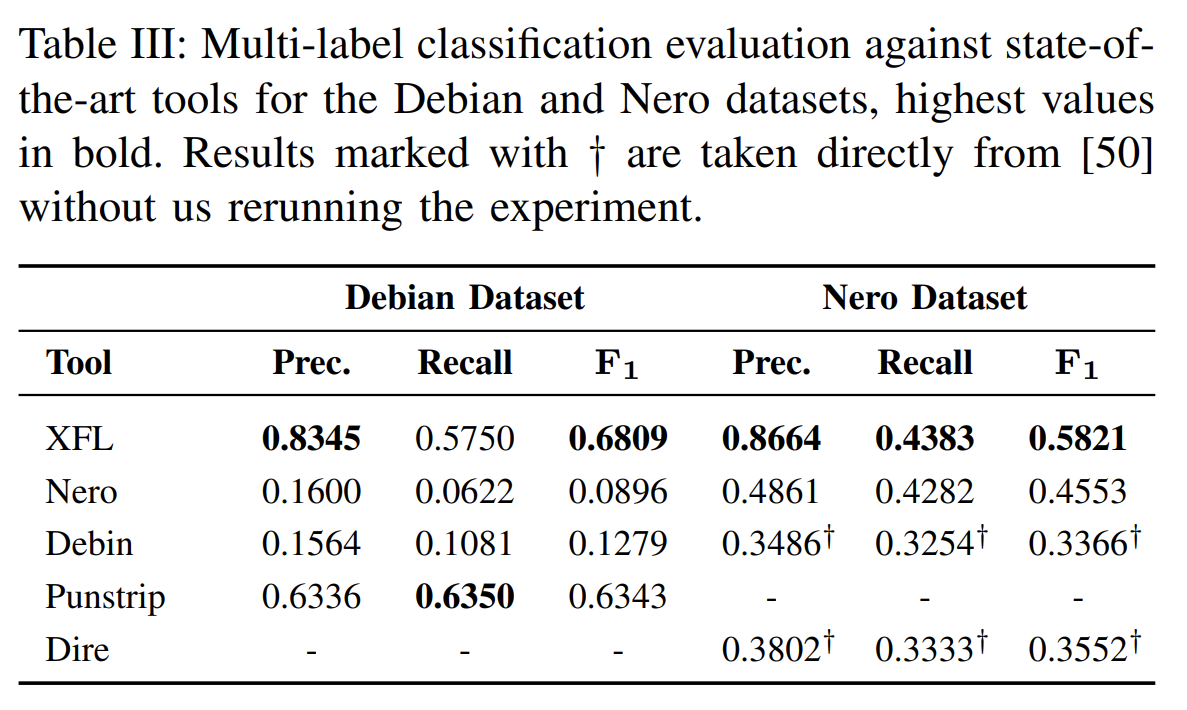
在punstrip和Nero数据集上的实验结果,XFL 明显领先其他模型,提升幅度较大可以排除误差影响。
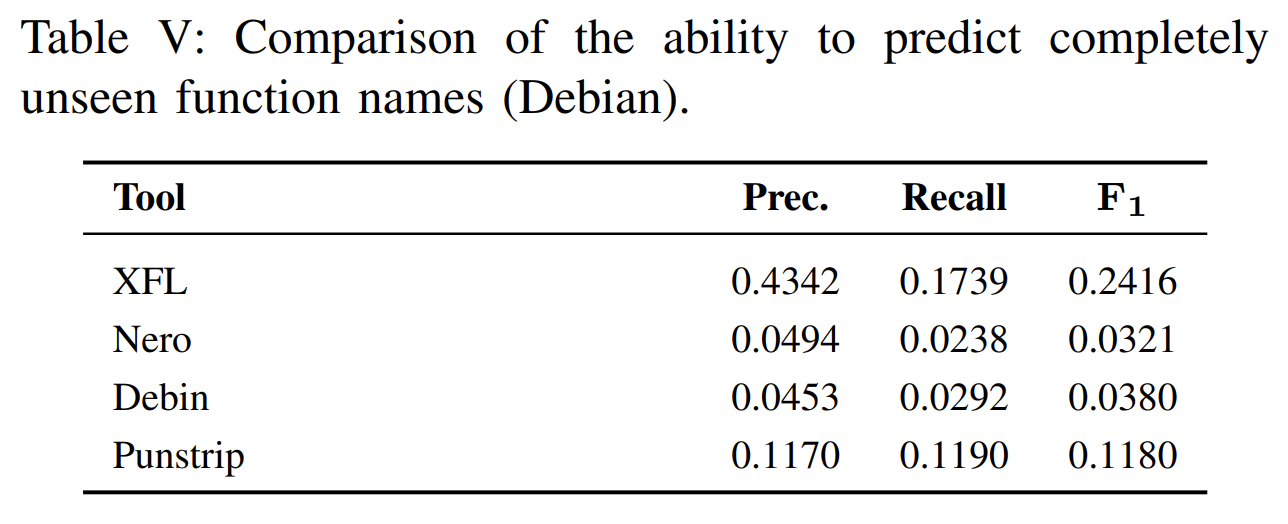
在Debin数据集上的实验结果,预测完整函数名的效果XFL 更是完胜。
讨论
原文针对提出的方法讨论了5种有效性威胁,这里只阐述比较重要的三种。
Generalization and Dataset Diversity.
我们的实验结果表明,Debin 在 Debin 数据集上的表现优于 Nero;而 Nero 在 Nero 数据集上的表现优于 Debin。我们联系了 Nero 的作者进行进一步调查,他们提出了以下可能的原因:(i) Nero 的数据集将二进制文件的最大尺寸限制为 1MB。这可能会影响大多数 glibc 库中常见函数的推断。 (ii) 我们使用的punstrip数据集中的词汇量明显更大,因此 Nero 43%的时间会预测出完全不正确的标签。 (iii) Nero 的配置和实现没有针对我们的数据集进行微调。这突出了一个有趣的问题。即使在注意避免过度拟合并确保正确的训练测试数据集拆分时,模型的某些方面本质上还是特定于数据集的。在使用不同编译器和编译参数的 Nero 数据集上进行测试时,甚至我们自己的模型的性能也会下降。
所以,一个公共的标准的用于二进制分析的数据集是个急迫的需求。
Concept Drift.
即使在相同的架构上,测试数据的分布也会随着源代码和编译器的变化而变化。这种概念漂移是许多应用领域中的已知现象。不同数据集之间的性能差异表明它存在于函数名恢复任务中。可以通过定期重新训练来抵消概念漂移。Yang et al. 最近的工作 [52] 使用对比学习来检测和解释新数据样本中的概念漂移。这种方法也可以与 XFL 结合使用,以减轻测试数据随时间变化的影响。
[52] CADE: detecting and explaining concept drift samples for security applications
Adversarial Settings.
在本文中,我们未考虑开发人员主动防御二进制分析的对抗性设置。我们明确假设二进制文件由常规编译器生成,只删除调试和符号信息用于发布。诸如运行时解包或不透明谓词之类的混淆方法会破坏XFL的有效性。
除了混淆之外,还可以考虑对 XFL 中的多标签分类器模型进行对抗样本攻击。通过给代码加入对抗性扰动,攻击者可能导致模型无法正确预测。对抗样本鲁棒性是一个活跃的研究领域,大多数提出的鲁棒性策略很快就被证明是无效的。
SYMLM
CCS 2022, SymLM: Predicting Function Names in Stripped Binaries via Context-Sensitive Execution-Aware Code Embeddings
关键词
pre-train, Inter-procedural CFG, calling-context, execution behaivor, transformer, MLP, cross-compile, Ghidra
摘要
现有方法尚未成功建模以穷举所有函数的执行行为,并且对于未见过的二进制的泛化能力很差。为了进一步推动函数名恢复任务的研究,我们提出了一个用于函数符号名预测和二进制语言建模的框架(SymLM Symbol name prediction and binary Language Modeling framework),该框架使用新型神经网络架构——一个融合encoder,该网络可以通过联合建模“the execution behavior of the calling context and instructions”(学习函数指令的语义和它在过程间CFG上的callers和callees的语义),来学习二进制函数的综合语义。我们从27个开源工程中收集了1,431,169个二进制函数来评估我们的框架,这些工程通过交叉编译得到(O0-O3,x86、x64、ARM、MIPS,4 obfuscations)。SymLM 在 precision、recall 和 F1 方面优于之前最先进的函数名预测工具 15.4%、59.6% 和 35.0%,具有更好的泛化性和抗混淆性。消融实验证明我们的设计(例如calling context 组件和execution behavior 组件)大幅提升了函数名预测模型的表现。最终我们的样例研究进一步展示了 SymLM 在分析固件iso中的实际表现。
calling context(调用上下文):指一个函数调用的函数,和调用它的函数。
code: https://github.com/OSUSecLab/SymLM
方法
本文课题组先前的工作,TREX 提出了一种通过预训练micro-execution trace value 的方式建模执指令的执行语义。TREX 在二进制相似度搜索领域取得了不错的成果。
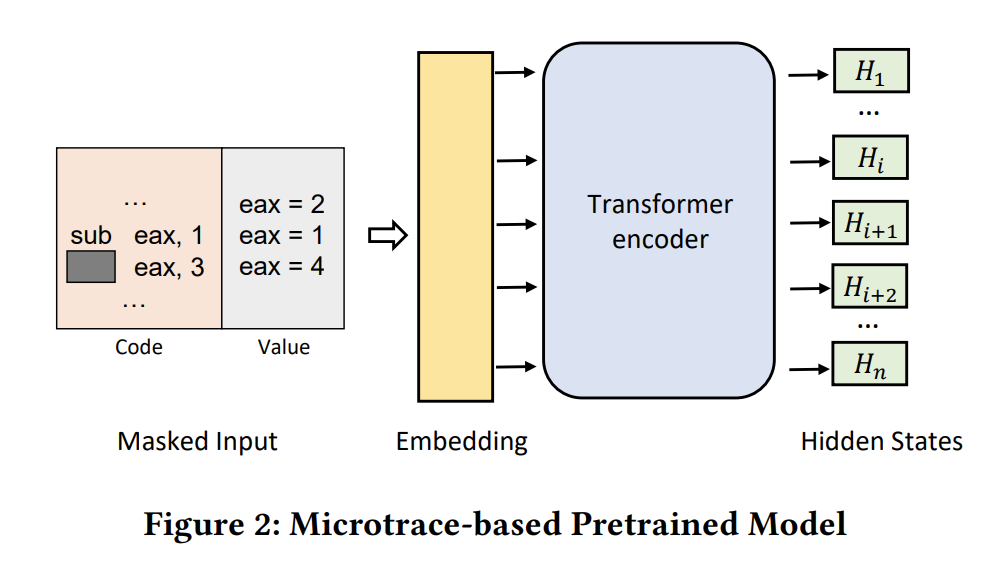
上图Fig2 展示了TREX 的预训练模型,模型输入指令,和对应的由微执行产生的值。当盖住操作符,模型要预测执行逻辑 eax?3=4 。预训练后,TREX 生成每条指令的语义嵌入(向量表示),可进一步用于检测具有相似执行行为的二进制函数。StateFormer 作为其后续研究也通过学习函数执行语义来推断变量类型。
本文基于TREX 中的预训练模型完成对本文任务的指令语义学习(指令嵌入)的预训练。
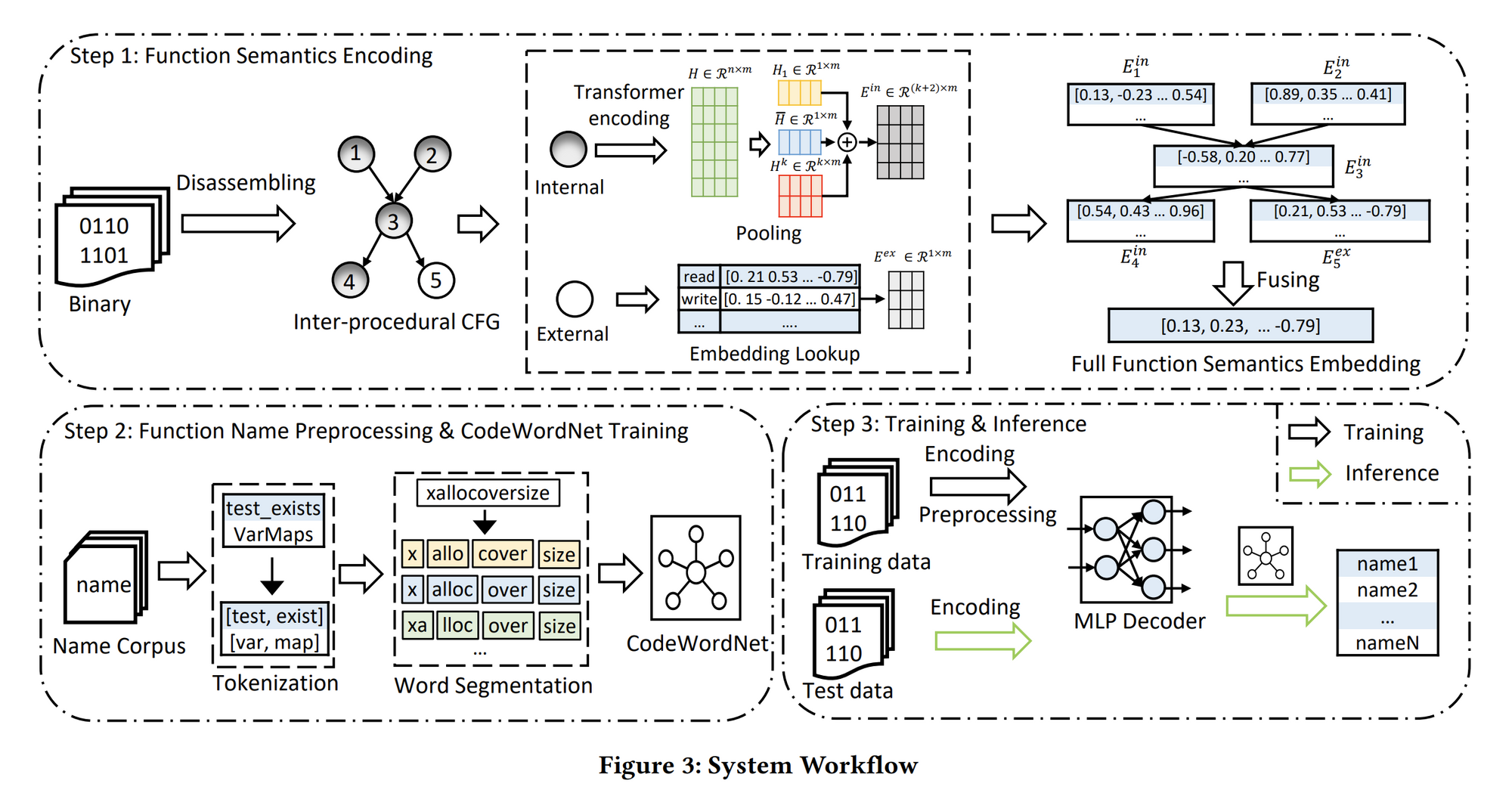
上图展示了SymLM的工作流,主要是3个关键步骤:
1)Function Semantics Encoding:理解二进制函数综合语义并编码到向量表征形式;
2)Function Name Preprocessing and CodeWordNet Training:建模函数名语义,缓解自然语言的模糊性,减少OOV的token;
3)Training and Inference:训练模型将函数语义向量映射到函数名。
下面将分别阐述一下这三个步骤中的细节,辅助理解fig3 SymLM的工作流。
Function Semantics Encoding
首先,构建过程间控制流图ICFGs,如Fig3 step1,其中节点3(函数)可能调用内部节点4(内部函数)或者外部节点5(外部函数)。
接下来,SymLM 采取两个步骤构造函数内部指令的嵌入 :
- 使用microtrace-based 预训练模型(fig2)生成函数tokens 的embedding,这个预训练模型在fig3中就是Transformer
- 下采样token embeddings 生成结构化表征()。例如,对于节点3,使用 指代这个函数的指令嵌入。
为了产生函数的上下文嵌入 ,需要同时嵌入节点callers和callees的执行行为信息。对于其他的内部函数可以用上述方法分别生成其 向量,而对于外部函数比如节点5,SymLM 通过查找embedding table 来获取其嵌入 。
最后,SymLM 融合一个节点的callers和callees的嵌入向量( 和 )来生成语义嵌入 ,并通过结合 和 得到最终的函数表征向量。
关于如何下采样计算内部函数的 . 和TREX 中直接使用token embeddings的均值不同,SymLM 使用一个特别的pooling 策略来下采样获取更好的模型表现。具体来说,我们观察到,在自然语言处理任务中,直接使用 [CLS] 的嵌入或者所有token嵌入的平均值作为句子嵌入,这两者已被证明是无效的,它们会分别导致 17.5% 和 10.3% 性能下降。根本原因是基于 BERT 的预训练模型生成各向异性token 嵌入。我们将多种下采样嵌入向量拼接起来,包括[CLS] embedding,所有token embedding的均值,以及token-position-insensitive embedding ,三者拼接作为函数语义嵌入 。其中token-position-insensitive embedding:从上图fig3 step1 中取前 k (实验中k=5)行最大的向量作为。关于如何比较每一行的大小,文章并没提到(盲猜直接求和一行)。
关于外部函数的嵌入. 基于这样一个观察:“外部函数的语义通常是固定的,且很大程度上体现在其函数名上”,本文使用一个随机初始化的embedding layer 来根据外部调用函数的函数名获取其 。相当于一个词汇表的嵌入,而这个词汇表是通过训练集中的外部调用函数名构建的。在模型训练期间更新这个嵌入层以获得外部函数名的最佳嵌入。当外部函数名不可用时,我们放弃融合对应的函数调用。
关于如何融合多个 获得 . 我们提出了一个具有选择性的调用上下文融合策略:1)SymLM 根据caller和callee的call和called by 目标函数的频率排序,2)拼接top-n个caller和top-n个callee的向量:
其中, 和 分别是 𝑖-th caller and 𝑗-th callee 的嵌入向量。
模型运算过程中每个 的尺寸是 ,融合就是在第二个维度做拼接。也就是说 和 融合得到的tensor尺寸是 。
关于如何融合目标函数的 和 得到最终的模型输入. 这里的融合规则和上述获得 的融合规则相同。
Function Name Preprocessing and CodeWordNet Training
总结了7种OOV问题,如table 2,设计了多种方法来解决这些问题。
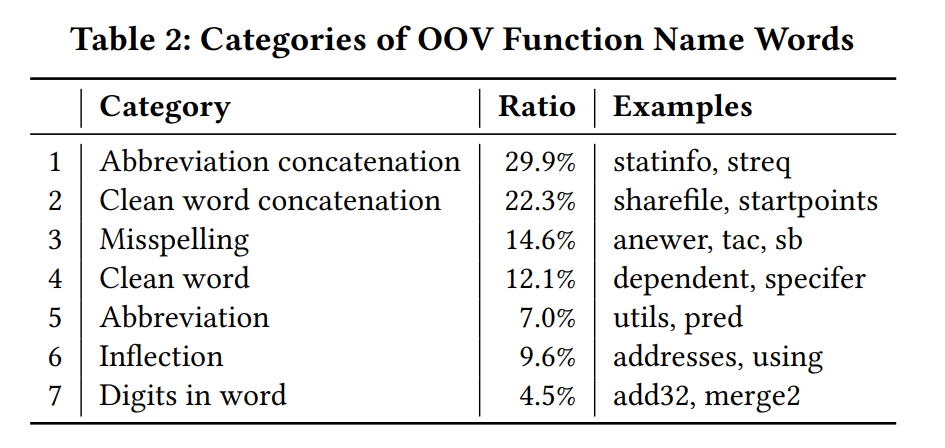
首先,在tokenization 过程中,我们对带数字的单词和单词的变形两种情况进行词形还原,以解决表 2 中的 6 和 7。其次,我们基于 unigram 语言模型构建了一个分词模型,对常见连词进行分隔,解决1 和 2。其余问题归结为 3、4 和 5。OOV 类别 3、4 和 5 中的词的关键原因是使用单词的变体(例如,同义词、缩写和拼写错误),我们设计了 CodeWordNet 模块,它可以在函数名称的上下文中生成单词的语义向量表示。借助该模块,SymLM 可以测量词的语义距离,建模函数名称语义,并解决类别 3、4 和 5 中的 OOV 问题。
Training and Inference
为了学习从函数语义向量到函数名的映射,我们使用带有调试信息的二进制文件提取数据集训练 SymLM,其中函数名标签从符号表中解析得到。对于训练,SymLM 首先将完整的函数语义编码为嵌入向量,然后预处理函数名标签,通过多层感知 (MLP) 解码器将函数语义嵌入解码为要预测的名称,最后通过最小化预测损失进行训练。在推理阶段,SymLM 将剥离的二进制文件作为输入,并根据函数的语义嵌入预测函数名tokens,其中生成函数名时 SymLM 也利用到了 CodeWordNet 生成多个同义词。
主要实验
使用Ghidra 作为反编译工具,基于TREX 实现了microtrace-based pretrained model,增加了1864 行新代码。我们使用NLTK 和SentencePiece 构建了我们的函数名处理组件,使用Gensim 构建了CodeWordNet 。开发了一个Ghidra插件和脚本来反编译二进制和解析调试信息。其他部分使用Pytorch 和fairseq 实现。
Dataset. 27 开源项目,使用GCC-7.5交叉编译(x86, x64, ARM, and MIPS, O0, O1, O2, and O3)额外使用一个混淆器来编译检测本文方法的抗混淆能力。得到最终的数据集 16,027 个二进制文件, 1,431,169 个函数,按照 8:1:1 分隔。二进制文件级别的切割,并没有进行额外的去重步骤,这与Nero 的做法保持一致。
Metric. 同Nero 和NFRE 。
方法有效性:
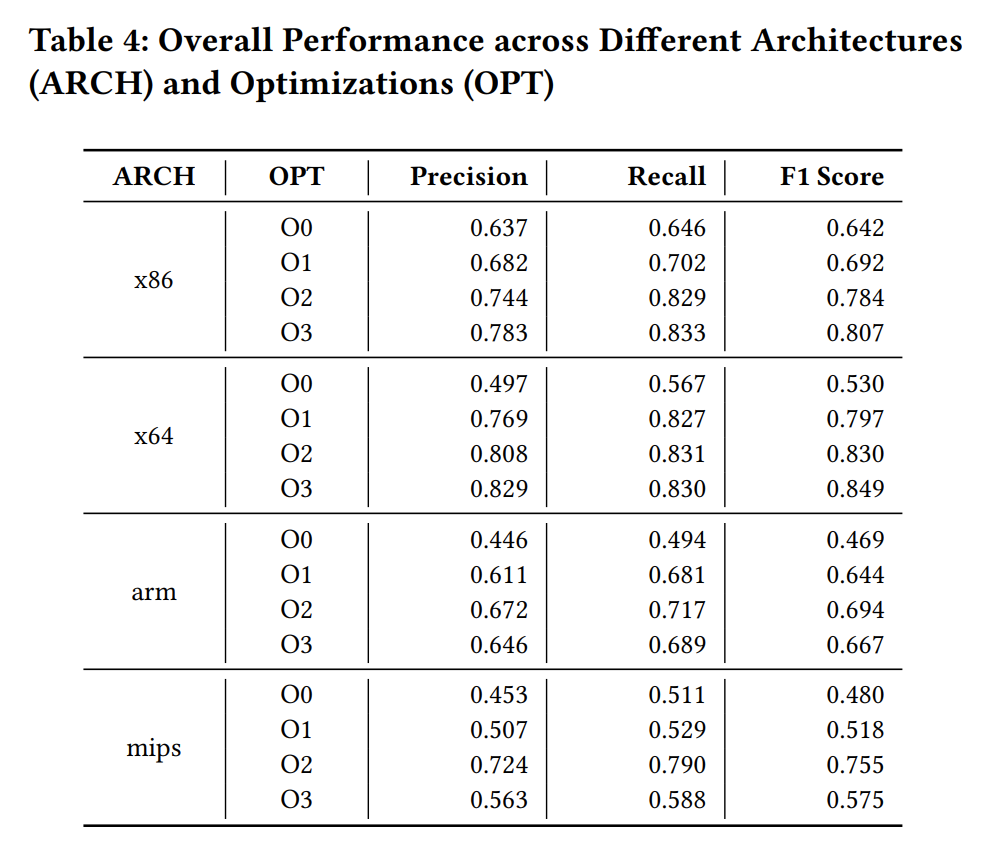
SymLM 在预测二进制函数名任务上非常有效,它在不同的架构和优化中实现了 0.634 的精度、0.677 的召回率和 0.655 的 F1 分数。
对比实验:
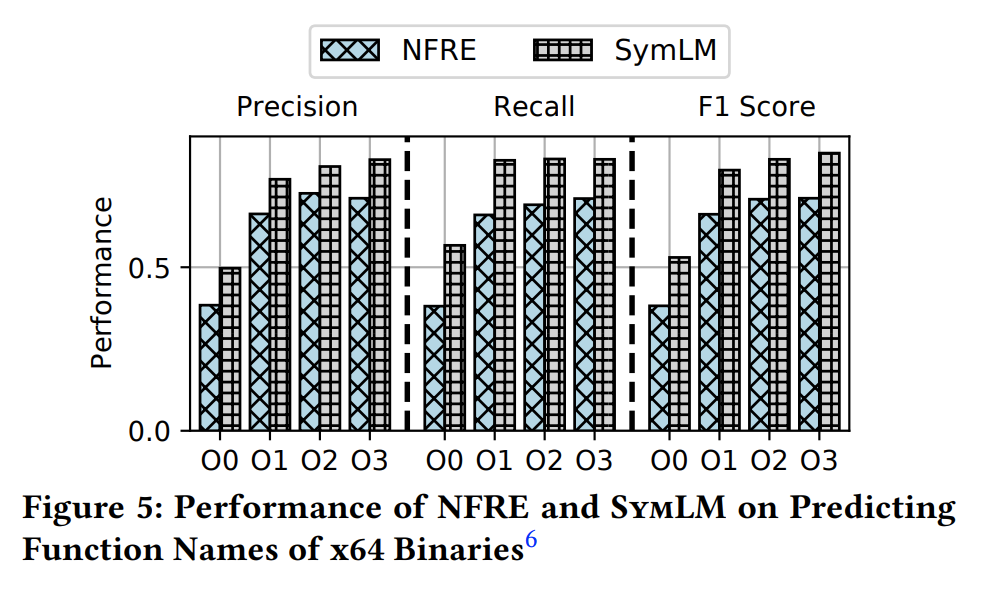
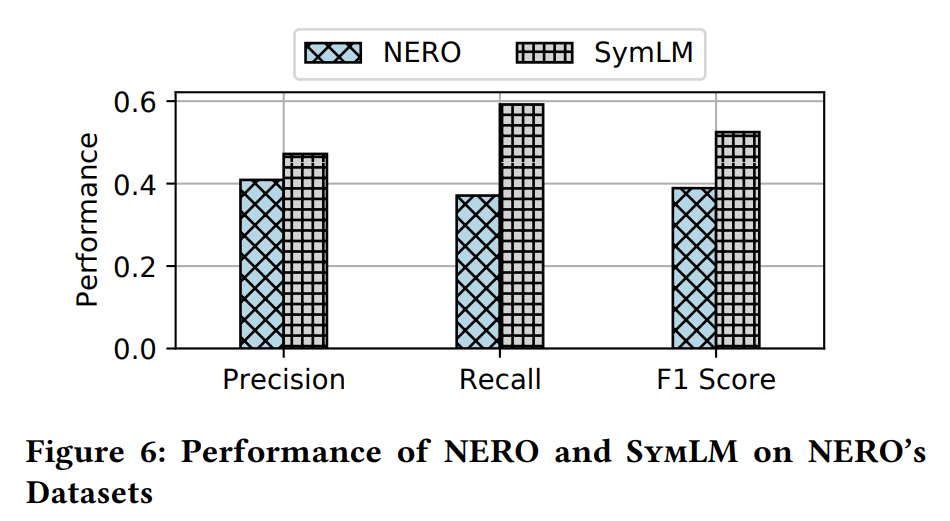
SymLM 比之前最好的工作更有效。例如,它在准确率、召回率和 F1 分数上比 NERO 高出 15.4%、59.6% 和 35.0%。
泛化性:
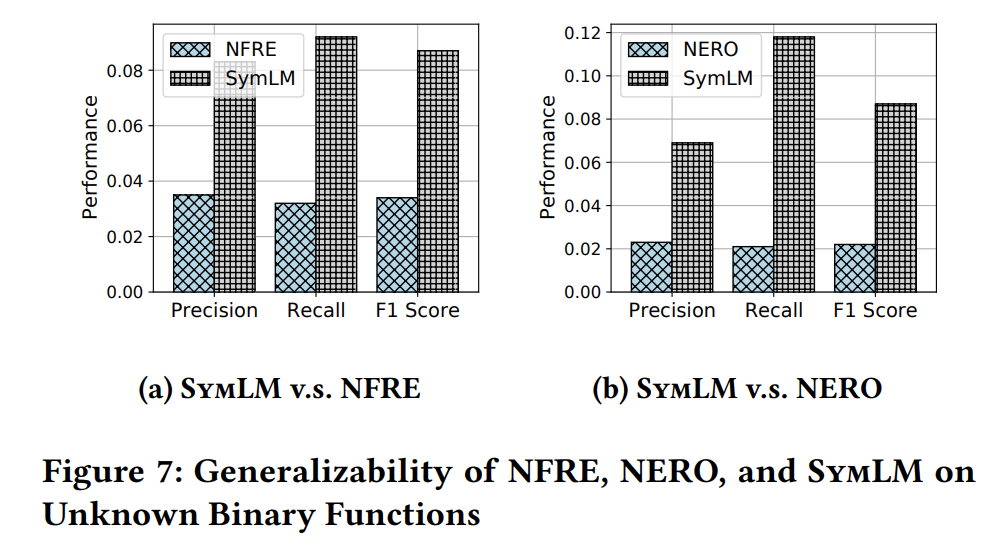
泛化性能更好,但是还是不够好。
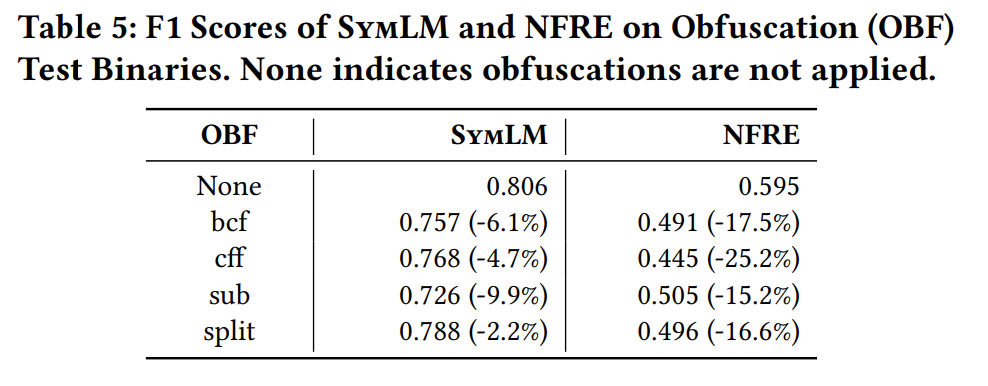
健壮性,抗混淆能力不错。
消融实验
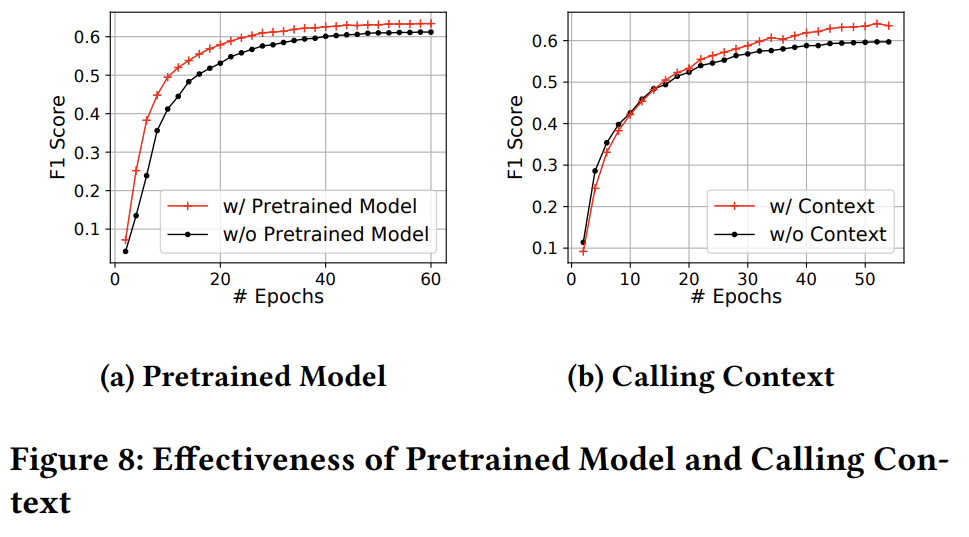
-
fig8 (a) 是预训练模型对预测模型的提升,也就是基于TREX 的指令token嵌入模型。
在前20 epoch的提升比较明显,而在超过20 epoch后基本可以忽略不计。
-
fig8 (b) 是调用上下文对预测模型效果的提升,即是否包含目标函数的上下文函数的嵌入 。
调用上下文的加入对模型能力上限有提升,7.9%。
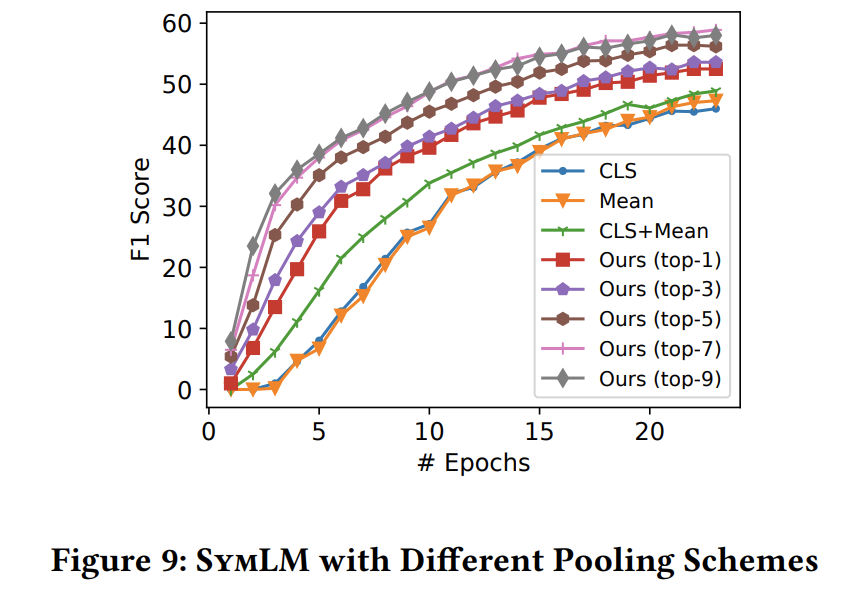
fig9 是fig3 step1中对函数tokens 的embedding 矩阵 池化策略的不同,对模型的影响。
本文的池化策略对模型的提升还是比较显著的,加入 token-position-insensitive embedding 后提升明显。
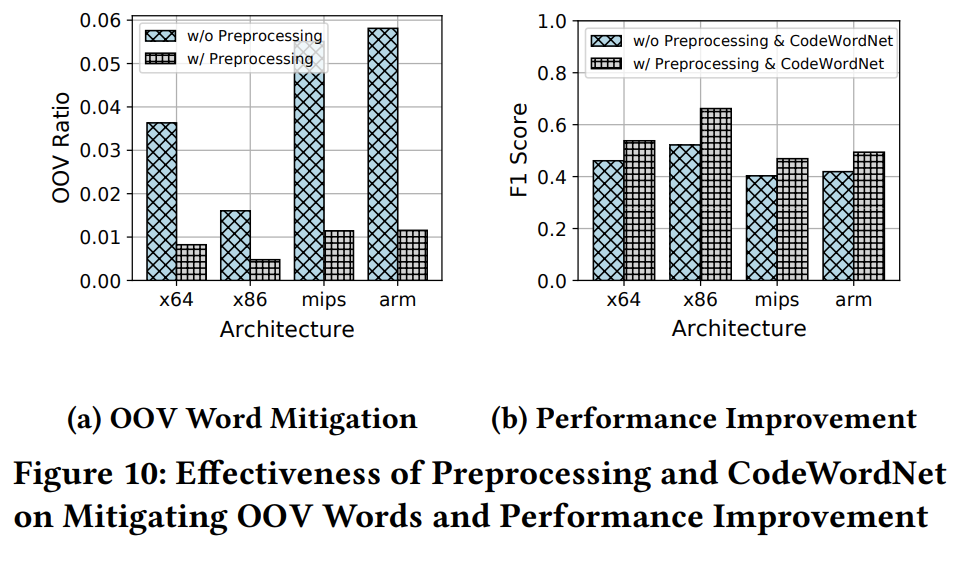
fig10 是对函数名token预处理后OOV问题的减轻程度,以及预测模型性能的提升。
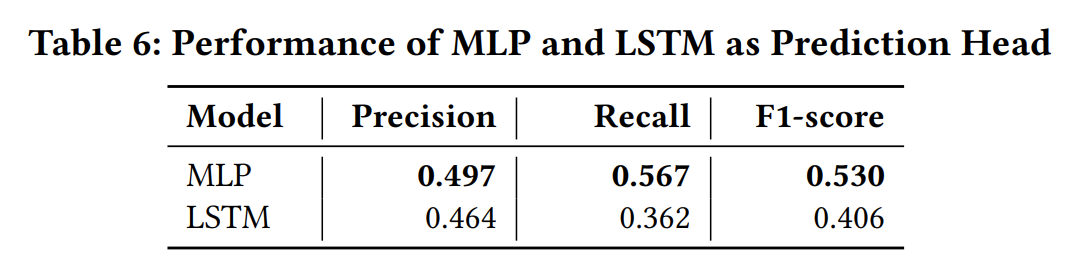
不同的预测模型(解码器),MLP略优于LSTM。
讨论
Dataset Size. 当前数据集规模不够大,更大的数据集应该能使模型具有更好的泛化性。
Obfuscation. 本文中仅考虑编译器混淆,而没有考虑其他形式的混淆,例如加密和加壳。我们将其看作和本文正交的研究问题,任何对这些问题的研究进展都能促进我们的方法提升。
Operating System. 我们仅关注Linux上的二进制,其他OS或许有不同的调用上下文语义,这可能会使SymML 失效。
Noise in Ground Truth. 虽然我们试图解决模棱两可的函数名称问题,但由于 SymLM 中使用的词嵌入算法的限制,该问题并未完全解决。此外,本文只考虑token级别的语义相似性,而未考虑具有多个token的相似短语。我们将在未来的研究中解决这些问题。